本文提出了一个针对 4D 动态场景重建的鲁棒性框架,通过在 Visual Geometry Grounded Transformer (VGGT) 中引入分层不确定性感知先验,实现了动态与静态组件的有效解耦。该方法在不需要特定任务微调或场景优化的情况下,在 DyCheck 和 DAVIS 评估中达到了 SOTA 性能,显著降低了重建误差。
TL;DR
在三维重建步入“基础模型”时代的当下,VGGT 等模型在静态场景表现惊艳,但在处理“动起来”的世界时却显得力不从心。本文提出的新框架通过 熵引导子空间投影、几何纯化 和 不确定性感知一致性 三大核心机制,在不改变模型权重、无需微调的前提下,实现了动态场景下重建精度的跨越式提升(精度提升 13.43%)。
痛点深挖:为什么动态场景是 Transformer 的“噩梦”?
传统的 3D 重建模型(如 DUSt3R, VGGT)都默认了一个物理前提:静态刚性假设。但在 4D 动态世界中,物体的运动会产生额外的位移 ,这直接导致了对极约束的失效。
在 Transformer 架构中,这种违背会导致 Attention Pollution(注意力污染)。原本应该聚焦于几何对应点的注意力变得弥散,使得相机位姿估计产生漂移,最终在 3D 空间中留下大量的“幽灵”(Ghosting Artifacts)和“漂浮物”(Floaters)。
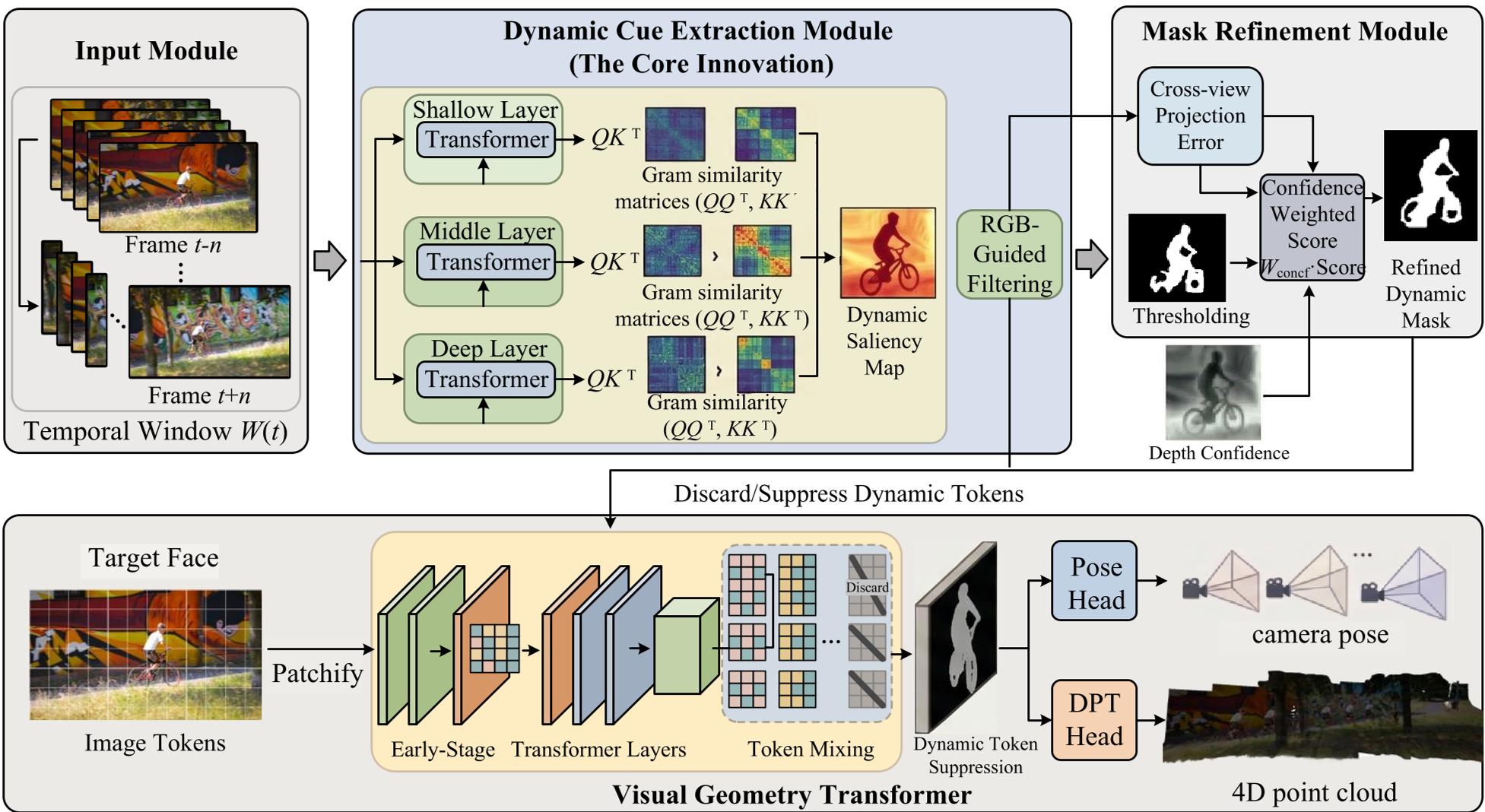
核心机制:三维一体的不确定性建模
作者认为,解决动态解耦的关键在于:不仅要识别“动”,还要量化“不确定性”。
1. 特征层:熵引导子空间投影 (Entropy-Guided Subspace Projection)
并非所有的注意力头(Attention Heads)在识别运动时都是平等的。作者发现,包含真实运动信息的注意力头通常具有较高的空间方差(即响应更集中)。
- 做法:利用信息论,根据每个 Head 的空间响应方差计算权重,自适应地投影多头分布式,从而抑制弥散的背景噪声,提取纯净的动态特征信号。
2. 几何层:局部一致性驱动的几何纯化 (Local-Consistency Geometry Purification)
即使有了好的特征,初始投影的点云仍会包含大量离群点。
- 做法:引入半径邻域约束,规定有效的动态点必须在球形半径内拥有足够的“同伴”支持()。这一步骤像是一个“高频滤波器”,去除了空间中的随机噪声点。
3. 约束层:不确定性感知交叉视图一致性 (Uncertainty-Aware Consistency)
这是本文数学美感最强的地方。作者将多视图投影误差建模为 各向异性(Heteroscedastic) 问题。
- 直觉:遮挡区域和无纹理区域的深度预测本来就不准,强行赋予它们高权重进行优化是不合理的。
- 公式推导:通过输出一个置信度对数 ,并利用极大似然估计(MLE)将深度残差与观测方差解耦:
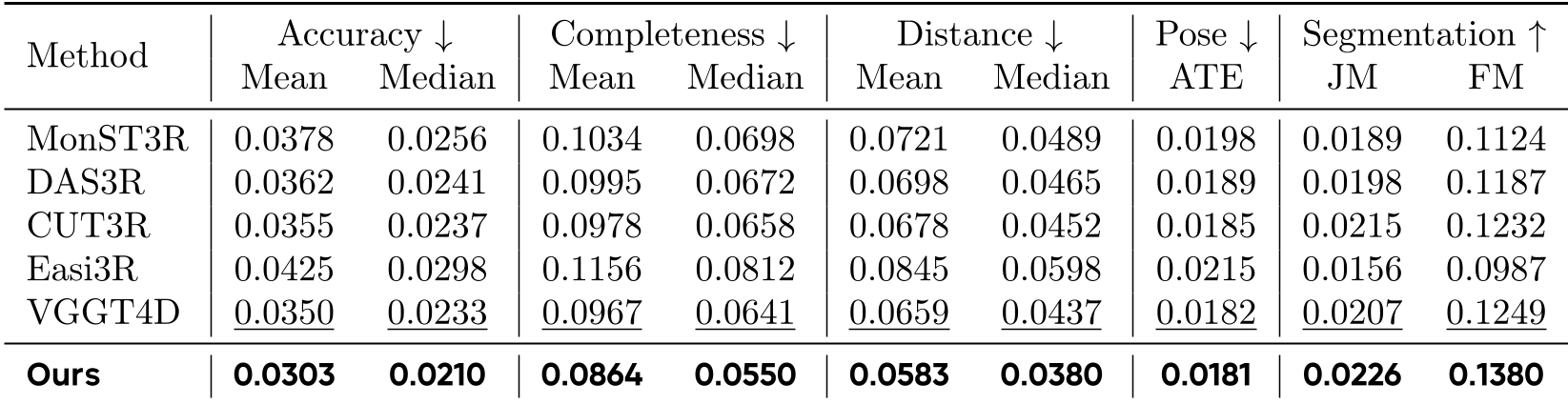
实验战绩:不训练也能赢 SOTA
在 DyCheck 和 DAVIS 两个硬核数据集上,该方法展现了降维打击般的优势:
- 高精度:Accuracy Mean 改善了 13.43%。
- 强分割:在 DAVIS-2016 上的 Jaccard Mean 达到了 61.60,大幅领先于需要大量训练数据的 MonST3R 和 DAS3R。
深度洞察:4D 重建的未来
这篇论文提供了一个非常深刻的启示:几何先验优于盲目训练。
当前的趋势是不断堆参数和数据,但本文告诉我们,通过精确地刻画 3D 投影过程中的物理/概率特性,我们可以在零样本(Zero-shot)的情况下,让现有的静态视觉基础模型具备处理复杂动态世界的能力。这对于实时交互、自动驾驶等对推理延迟和泛化性要求极高的场景具有巨大的工业价值。
局限性:尽管有效抑制了“漂浮物”,但在极度快速运动或极端光照变化的区域,深度估计的初始下界仍限制了最终的恢复上限。未来的研究或许可以结合 SSM(状态空间模型)来增强时间维度的长程一致性。
总结 (Takeaway):本文通过分层不确定性建模,成功让 Visual Geometry Transformer 在“动感世界”中保持了冷静与精准。