The paper introduces ROPD (Rubric-based On-policy Distillation), a framework that replaces teacher logits with structured semantic rubrics for model alignment. It enables effective on-policy distillation in black-box scenarios, outperforming advanced logit-based methods such as LOPD and achieving state-of-the-art results on reasoning benchmarks like AIME24/25.
TL;DR
On-policy distillation (OPD) is the gold standard for aligning LLMs, but it usually requires "white-box" access to teacher logits—a luxury we don't have with proprietary models like GPT-4o. ROPD (Rubric-based On-policy Distillation) shatters this limitation by using structured, semantic rubrics instead of logits. It doesn't just match the performance of white-box methods; it surpasses them, achieving 10x higher sample efficiency and outperforming its own teacher in complex reasoning.
The Problem: The "Mimicry Trap" of Logit-Based Distillation
Traditional distillation forces a student model to predict the exact same token distribution as the teacher. This approach (Logit-based OPD or LOPD) suffers from three fatal flaws:
- The Black-Box Barrier: You cannot distill from proprietary APIs that only give text, not probabilities.
- Stochastic Noise: Logits often reflect a teacher's specific phrasing style rather than logical correctness.
- Misalignment: A student can match the teacher's distribution perfectly but still get the answer wrong because it's mimicking "style" over "substance."
The Insight: Crossing the Semantic Bridge
The authors found a startling reality: Teacher logits are a poor proxy for correctness. In their analysis, the correlation (AUC) between teacher logits and ground-truth correctness was near-random (0.35), while rubric-based rewards reached a staggering 0.90 AUC.
ROPD shifts the goal from "What token would the teacher say next?" to "Does the student's reasoning follow the teacher's principles?"
Methodology: How ROPD Works
The ROPD pipeline consists of two primary stages integrated into the GRPO (Group Relative Policy Optimization) framework:
- Rubric Induction (The Rubricator): The teacher model looks at its own diverse solutions and the student's current attempts. It identifies a set of criteria (e.g., "Identifies the parity obstruction") and assigns weights.
- Rubric-based Verification (The Verifier): The teacher then acts as a judge, blindly scoring student rollouts against these generated rubrics.
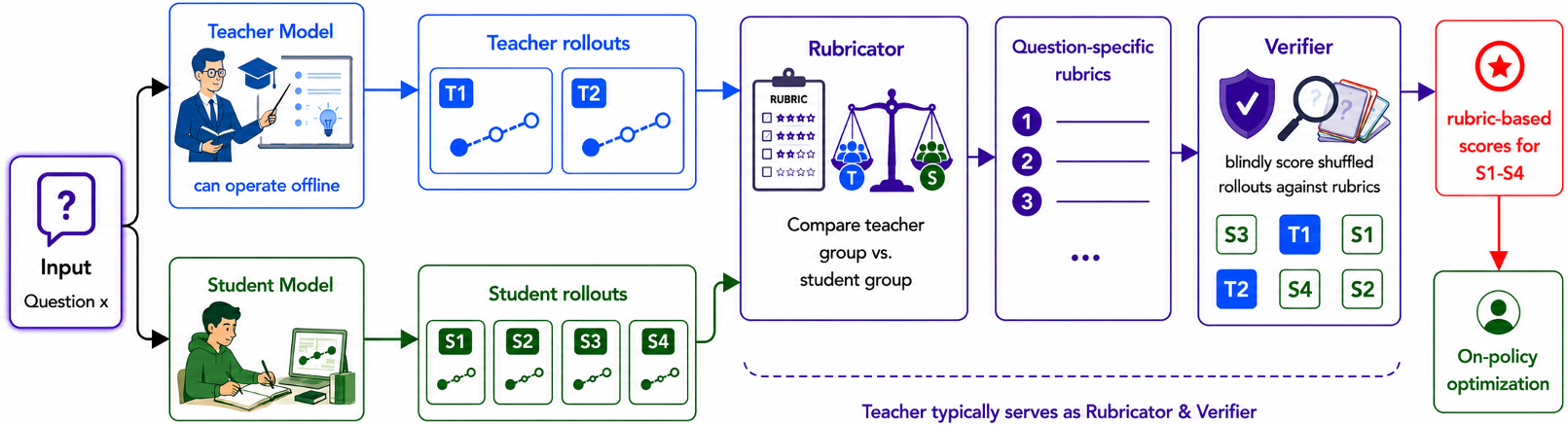
This "blind" verification is key—it filters out the "identity bias" and focuses purely on whether the reasoning steps are sound.
Experimental Results: Breaking the Ceiling
ROPD was tested across a gauntlet of reasoning benchmarks including AIME24/25 and GPQA. The results were transformative:
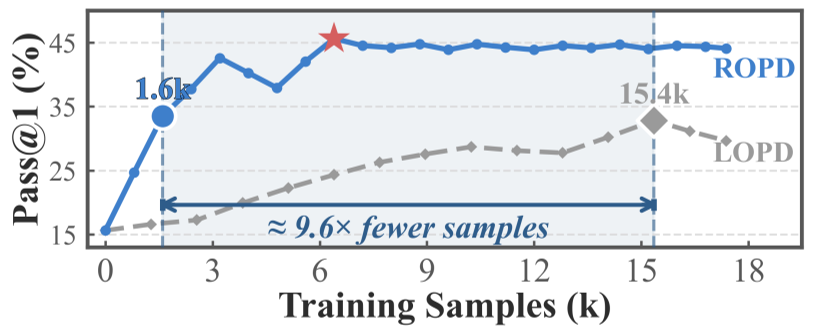
- Efficiency: ROPD recovered LOPD’s best performance with 9.6x fewer samples (1.6k vs. 15.4k).
- Transcendence: On AIME25, the student (Qwen3-4B) actually beat the teacher (GPT-5.2), scoring 68.75 against the teacher's 67.08.
- Robustness: It works even when student and teacher have entirely different architectures or tokenizers.
Why It Works: Mimicry for Training, Divergence for Transcendence
The most fascinating discovery in the paper is the "phase shift." Early in training, ROPD students copy the teacher's style. However, once they master the "language" of reasoning, they diverge.
While LOPD students stay trapped in the teacher's token distribution, ROPD students continue to improve in accuracy even as their similarity to the teacher's logits decreases. This proves the student is learning the underlying logic, eventually finding more efficient or clearer paths than the teacher originally provided.
Critical Insight & Conclusion
ROPD reframes distillation. Instead of seeing it as a process of matching numerical distributions, it sees it as the transfer of structured semantic principles.
Limitations: The framework currently focuses on "verifiable" reasoning tasks (Math, Science, Medicine). Whether rubrics can capture the "vibe" of creative writing as effectively as they capture the logic of a math proof remains an open question.
Takeaway for the Industry: For anyone building proprietary-level models on a budget, ROPD provides a blueprint. You don't need the teacher's hidden weights; you just need its expert judgment to build the rubrics that will guide your model to greatness.