This paper introduces RubricRAG, a framework for generating instance-specific, fine-grained evaluation rubrics for LLMs using domain knowledge retrieval. By retrieving rubrics from semantically similar queries at inference time, it achieves state-of-the-art alignment with human-authored rubrics and enhances the discriminative power of LLM-as-a-judge evaluators.
TL;DR
Evaluations of Large Language Models (LLMs) are moving away from "black-box" scalar scores toward transparent, rubric-based assessments. However, writing these rubrics is hard. RubricRAG solves this by retrieving expert-level rubrics from similar past queries to guide the generation of new, query-specific criteria. This method makes LLM judges more reliable, especially in high-stakes domains like healthcare.
Background: The Crisis of Trust in LLM Evaluation
The industry currently relies on LLM-as-a-judge—using a powerful model (like GPT-4 or Qwen-3) to grade a smaller model. Usually, the judge spits out a score from 1 to 10. But what does a "7" actually mean?
- It lacks actionability: Developers don't know what to fix.
- It lacks granularity: It might overlook a critical safety hazard if the overall "tone" is good.
- It lacks consistency: Coarse rubrics lead to ties between mediocre and excellent responses.
The authors of RubricRAG argue that we need query-specific rubrics—bespoke checklists for every single prompt.
Problem: The "Generic Rubric" Trap
When you ask a standard LLM to "generate an evaluation rubric" for a medical query, it tends to be generic: "The answer should be polite, accurate, and helpful."
In a clinical setting, this is useless. A physician needs to know: Did the model check for red flags like chest pain? Did it suggest an emergency transfer since the user is in a rural post? Zero-shot LLMs usually miss these "long-tail" domain-specific requirements.
Methodology: Grounding Evaluation in Retrieval
The core innovation, RubricRAG, shifts the burden from the model's internal memory to external domain knowledge.
1. The RAG Pipeline for Evaluation
Instead of generating a rubric from scratch, the system:
- Embeds the user query.
- Retrieves $k$ similar queries from a dataset where experts (e.g., physicians) have already written high-quality rubrics.
- Prompting: Uses these retrieved pairs as context, teaching the model the style and depth required for this specific niche.
2. Reinforcement Learning with Multi-Objective Rewards
The researchers also experimented with GRPO (Group Relative Policy Optimization). They didn't just reward the model for "looking like" a human rubric. They used a multi-pronged reward function:
- Format Reward: Is it valid JSON?
- Similarity Reward: Does it match semantic intent?
- Diversity Reward: Does it avoid repeating the same point five times?
- Logic/Reasoning: Including a "Think" mode to deliberate on clinical requirements before listing criteria.
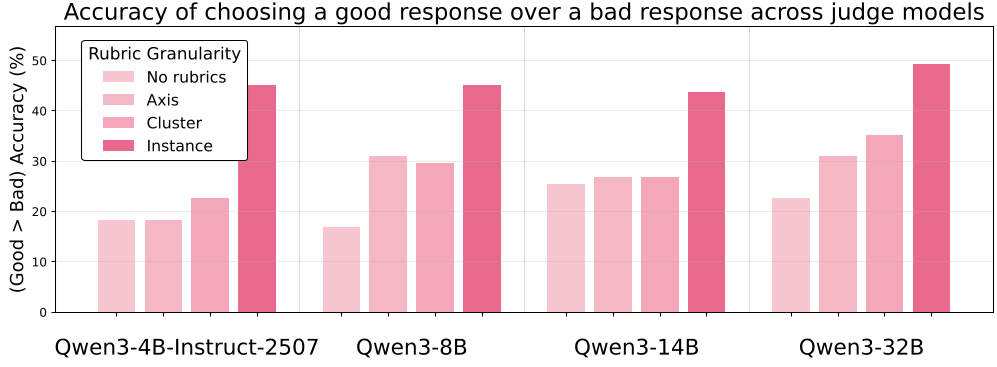 Figure 1: Comparison showing that fine-grained, query-specific rubrics (far right) provide much higher accuracy in distinguishing good vs. bad responses compared to no rubrics or coarse-grained ones.
Figure 1: Comparison showing that fine-grained, query-specific rubrics (far right) provide much higher accuracy in distinguishing good vs. bad responses compared to no rubrics or coarse-grained ones.
Experiments & Results
The authors tested RubricRAG on HealthBench (medical) and ResearchRubrics (academic).
Key Findings:
- Superior Alignment: RubricRAG (nothink) achieved a Spearman's $\rho$ of 0.545, significantly higher than Zero-shot (0.426).
- Discrimination Power: LLM judges using RubricRAG-generated criteria were much better at catching "bad" responses that looked "good" on the surface but failed specific rubric points.
- The "Overthinking" Tax: Interestingly, models that used "thinking tokens" (CoT) before generating rubrics sometimes performed worse. The reasoning was often noisy, leading to "overthinking" that distracted from the core clinical constraints.
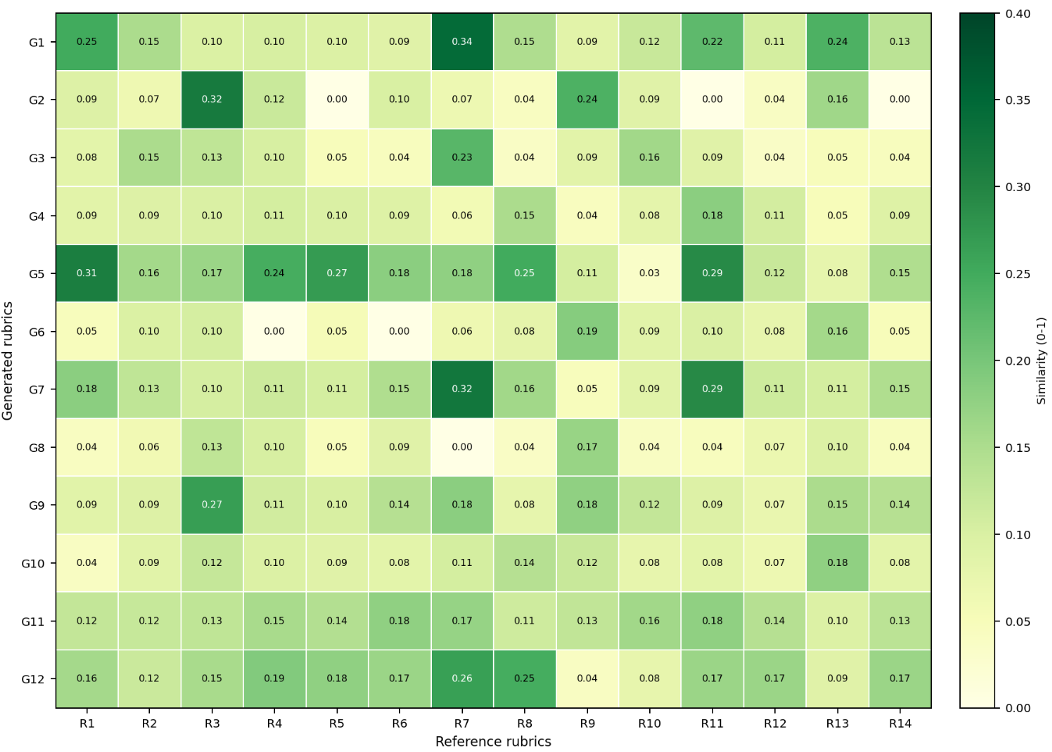 Figure 2: Heatmap visualizing semantic alignment. RubricRAG (right) shows a much denser correlation with human expert rubrics compared to the sparse, generic alignment of Zero-shot (left).
Figure 2: Heatmap visualizing semantic alignment. RubricRAG (right) shows a much denser correlation with human expert rubrics compared to the sparse, generic alignment of Zero-shot (left).
Critical Insight: Surface vs. Substance
A crucial takeaway from this study is that SFT (Supervised Fine-Tuning) is not a silver bullet. While SFT models got the "vocabulary" right (high BLEU/ROUGE), they didn't actually produce more effective grades. RubricRAG, by contrast, provided better utility—the rubrics it generated actually helped the judge make the right decision. This suggests that for evaluation, context (RAG) beats rote learning (SFT).
Conclusion & Future Work
RubricRAG proves that we can automate the creation of high-quality, expert-level evaluation criteria. However, a remaining challenge is redundancy: the RAG approach sometimes generates the same criterion twice (e.g., rewarding "clarity" and penalizing "vagueness").
For the industry, this work signals a shift: we are moving away from asking "Which model is better?" to "Exactly which verifiable requirements did this model fail to meet?"
Senior Editor's Note: This paper is a must-read for anyone building LLM-as-a-judge pipelines for specialized fields. It bridges the gap between raw model performance and human-level pedagogical assessment.