本文提出了 RVLM,一种基于递归 Python REPL 环境的视觉语言模型框架,旨在解决医疗 AI 的黑盒预测和固定计算开销问题。通过引入可预测任务复杂性的 RRouter 模块,该系统在 BraTS 2023 脑胶质瘤和 MIMIC-CXR 胸片任务上实现了具备可审计性和自适应深度的临床诊断。
TL;DR
在临床医疗领域,AI 的“黑盒”属性一直是阻碍其大规模应用的核心痛点。本文介绍的 RVLM (Recursive Vision-Language Model) 框架,彻底抛弃了传统的单次前向推理模式,转而采用一种“生成-执行”的递归循环。它不仅让 AI 的每一次诊断都有据可查(生成 Python 代码),还通过 RRouter 实现了动态的计算分配,让简单病例跑得快、复杂病例钻得深。
核心定位
RVLM 不是一个全新的基础大模型,而是一套方法论插件。它将现有的 VLM(如 Gemini 2.5 Flash)置于一个具备视觉能力的 REPL (Read-Eval-Print Loop) 环境中,使其从一个简单的“分类器”进化为一个具备“动手能力”的数字放射科医生。
1. 痛点:为什么单次推理不够用?
- 不可审计 (Lack of Auditability):放射科医生需要知道 AI 为什么判定是脑膜瘤,是基于哪个模态的什么特征?单次推理只给结果,不给过程。
- 效率极化 (Fixed-Budget Dilemma):医生处理一个简单的骨折和一个复杂的恶性肿瘤,花费的时间显然不同。但目前的 Agent 架构通常设定固定的
max_iterations,要么在简单任务上浪费 API Token,要么在复杂任务上草草了事。
2. Methodology:递归视觉推理与自适应深度
2.1 视觉 REPL 环境 (EV)
RVLM 的核心在于它给模型提供了一个“实验台”。模型可以编写 Python 代码来操纵图像:
describe_image():针对特定模态(如 T1ce 或 FLAIR)进行独立描述。llm_query_with_images():进行跨模态对比,例如对比增强后的 T1 与水肿明显的 FLAIR 图像。- 图像处理工具箱:支持调用 PIL 或 NumPy 进行裁切(Crop)或增强(Enhance),模拟放射科医生放大局部观察的行为。
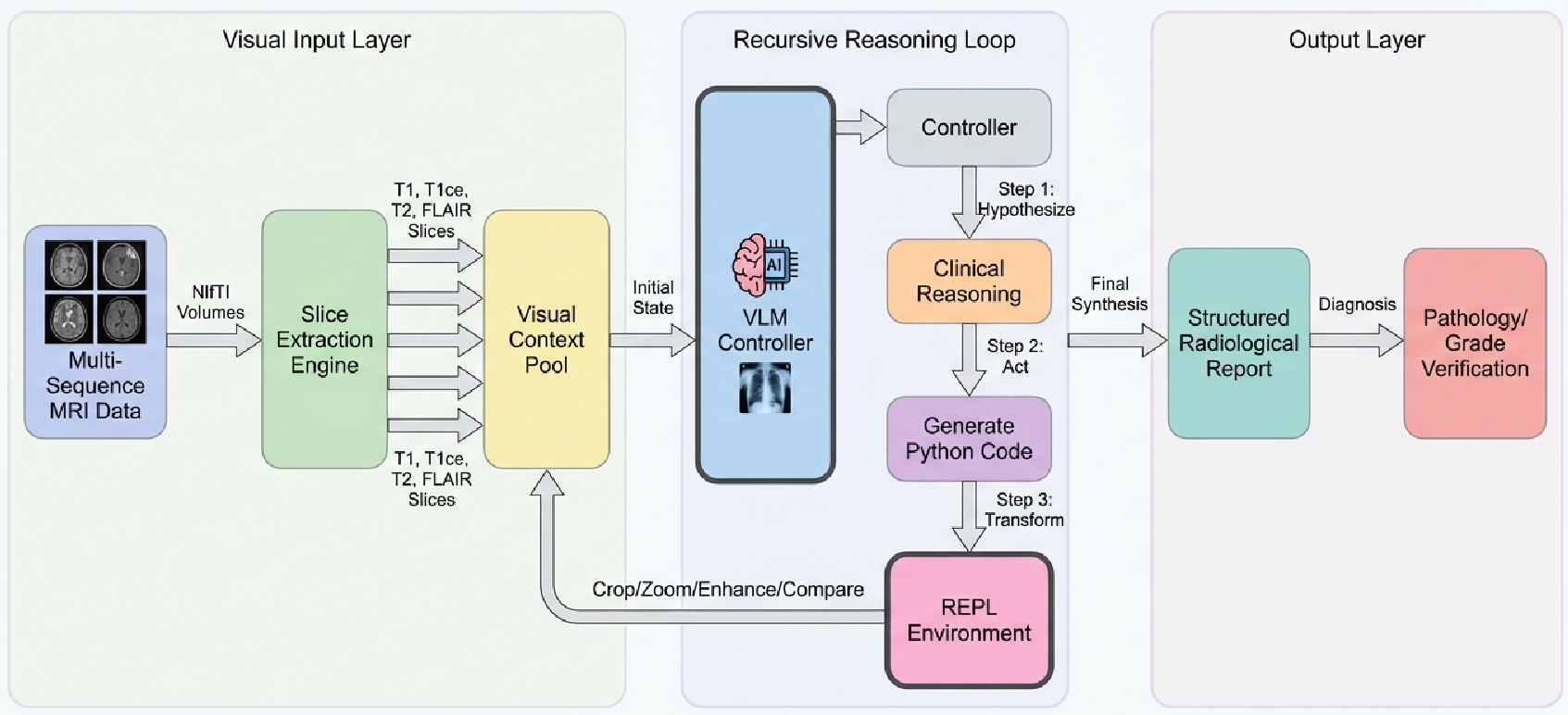 图 1:RVLM 系统架构,展示了 MV 控制器与 EV 环境之间的闭环交互。
图 1:RVLM 系统架构,展示了 MV 控制器与 EV 环境之间的闭环交互。
2.2 RRouter:任务复杂性预测
为了实现自适应深度,作者设计了 RRouter 逻辑。它首先通过一个“预检阶段”提取病灶的 4 个物理特征:
- 标签熵 (H): sub-region 分布越平均,复杂度越高。
- 肿瘤总体积 (V):体积越大,分析步骤越多。
- 子区域数量 (R):判断包含环形增强、水肿等多少个组成部分。
- 微小区域指标 (T):是否存在难以察觉的小病灶。
通过公式计算出复杂度评分 ,并将其映射为 3 到 6 次不等的迭代预算。
3. 实验结果:不仅仅是准确率
3.1 脑膜瘤亚区表征 (BraTS 2023)
在 BraTS 任务中,RVLM 展现出了极高的跨模态验证能力。例如,它能检测出分割掩码(Segmentation Mask)与原始图像信号之间的矛盾——这是单次推理模型绝对无法察觉的逻辑缺陷。
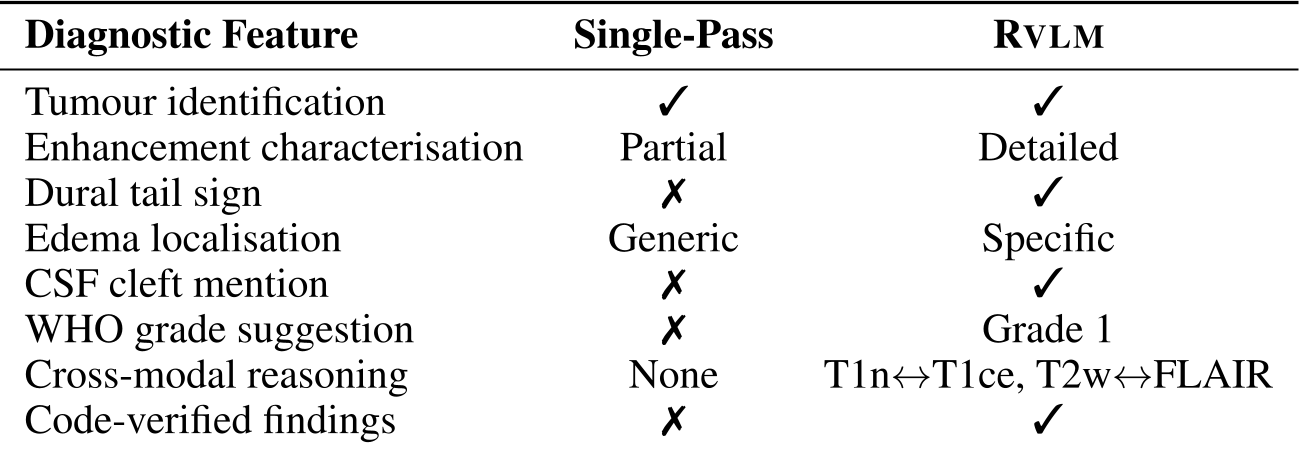 表 1:RVLM 与单次推理 VLM 在诊断功能上的对比,展示了其在增强表征和代码验证方面的优势。
表 1:RVLM 与单次推理 VLM 在诊断功能上的对比,展示了其在增强表征和代码验证方面的优势。
3.2 成本效率
对于简单案例(BraTS-MEN-00008-000),RRouter 将迭代次数压缩至 3 次。相比固定 12 次的上限,推理成本和延迟直接下降了约 75%,这使得该架构在实际生产环境中具备了经济可行性。
4. 深度洞察:符合监管的“内生透明度”
RVLM 最具前瞻性的贡献在于它对 Trust-by-Design 的实践。它产生的不是一段“看起来像解释”的文字(幻觉重灾区),而是:
- 程序化透明度:每一条结果都有对应的 Python 代码和执行日志。
- 临床友好输出:系统会自动将 REPL 记录转化为符合放射科规范的 PDF 报告。
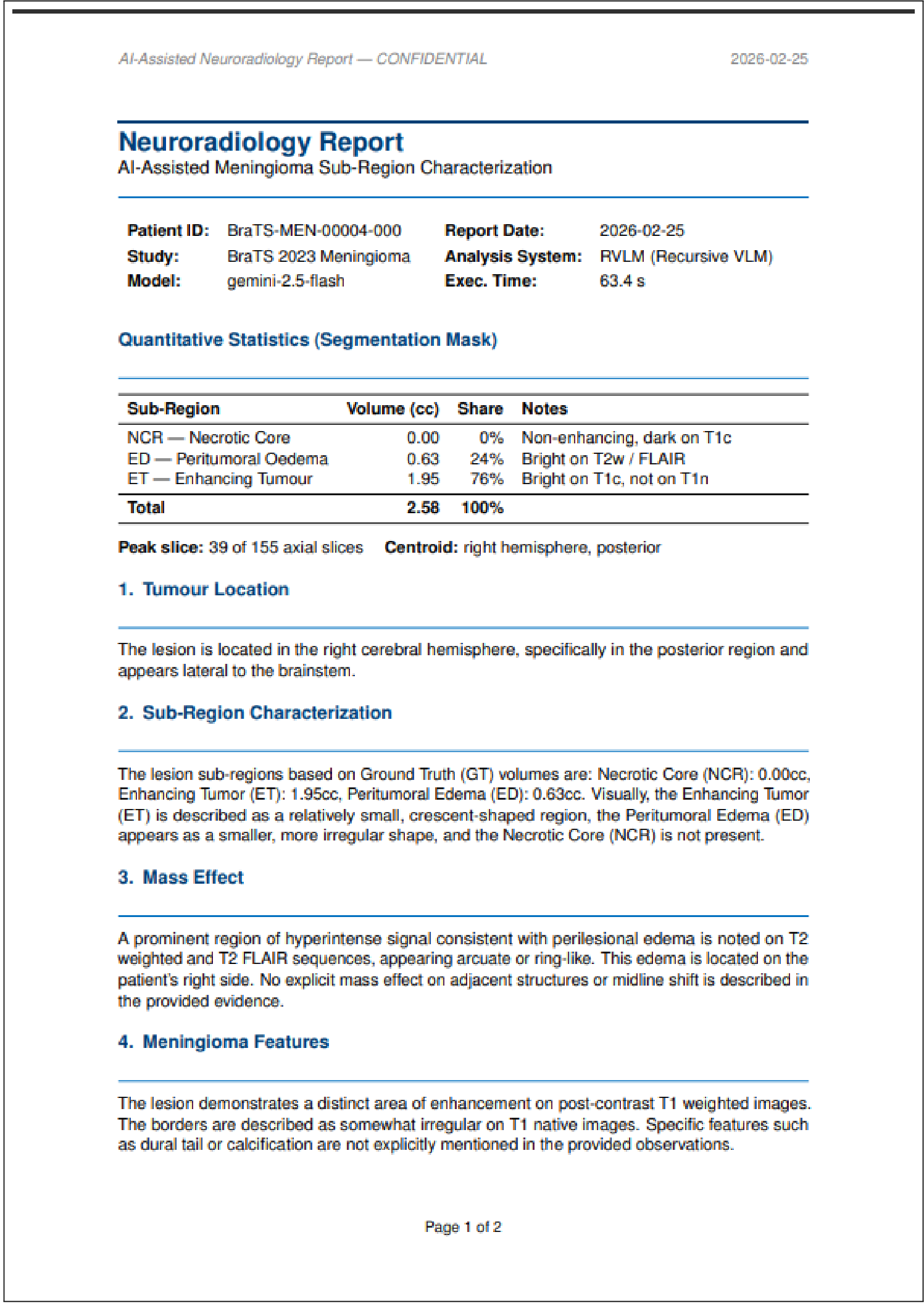 图 2:RVLM 自动生成的临床 PDF 指向:包含分割统计、执行数据及 AI 免责声明。
图 2:RVLM 自动生成的临床 PDF 指向:包含分割统计、执行数据及 AI 免责声明。
5. 局限性与展望
尽管 RVLM 在 Brain MRI 和 MIMIC-CXR 上表现卓越,但目前仍局限于 2D 切片。未来的演进方向包括:全体积 3D 递归导航(模型自主决定查看哪个层面)以及基于不确定性的递归触发(只有当模型“不确定”时才申请更多迭代预算)。
总结
RVLM 证明了医疗 AI 并不一定要在“精度”和“解释性”之间做选择。通过将视觉任务分解为可执行的递归步骤,我们既得到了 SOTA 的诊断深度,也得到了应对监管的可追溯证据链。