本文提出了 S-VAM,一种用于机器人操作的快捷视频动作模型。该模型通过创新的“自蒸馏”策略,将视频扩散网络(VDM)的多步生成能力浓缩到单步推理中,实现了兼顾高保真视觉前瞻(Geometric & Semantic Foresight)与实时交互性能的 SOTA 机器人控制。
TL;DR
传统的视频动作模型(VAM)在“高精度预测”与“高频率控制”之间一直存在难以调和的矛盾。港科大(广州)与华为基础模型部联合提出的 S-VAM (Shortcut Video-Action Model) 彻底打破了这一僵局。它通过**自蒸馏(Self-Distillation)**技术,让机器人仅凭单次前向计算(Shortcut)就能预见到未来精准的几何与语义信息,在保持 25Hz 动作采样率的同时,大幅提升了对复杂环境的操控精度。
痛点深挖:迟钝的预测与混乱的直觉
在机器人视觉操作中,**视觉前瞻(Visual Foresight)**至关重要——如果你不知道移动手臂后世界会变成什么样,你就无法精确调整动作。
- 传统 VAM 的死穴:如 SuSIE 等模型需要经过几十步 Denoising 才能生成一张清晰的未来图像,这导致控制频率降至个位数,机器人像是在“卡顿”中运行。
- 单步特征的局限性:像 VPP 这种试图用单步噪声特征(One-step features)来加速的模型,虽然快,但其特征高度纠缠(Entangled)。如图 1(a) 所示,其注意力轨迹漂移严重,甚至会出现夹持器方位在特征层面上“瞬间移动”的噪声。
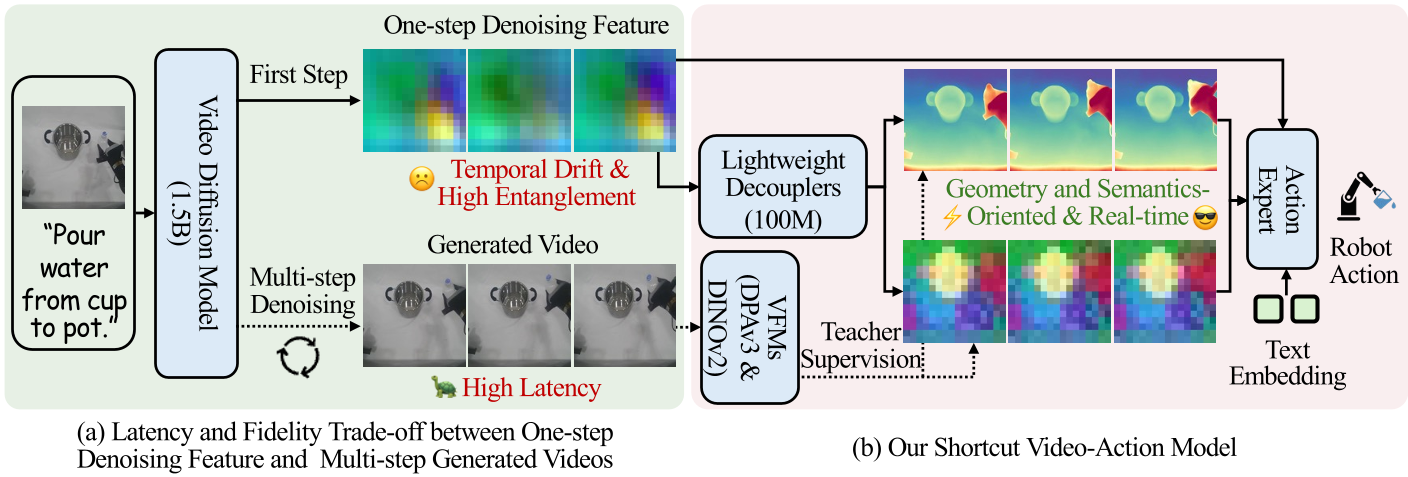
核心贡献:解耦与自蒸馏
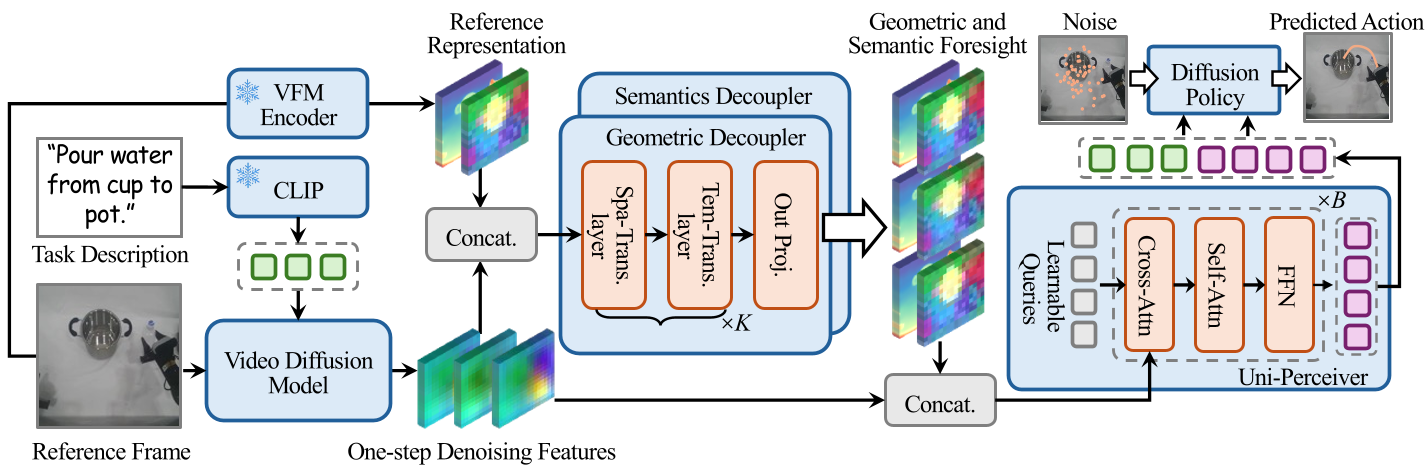
S-VAM 的核心直觉在于:扩散模型的初始步骤已经包含了全局的“未来蓝图”,只是这些信息由于噪声干扰而难以直接利用。
1. 双路几何语义解耦器 (Decouplers)
作者设计了两个轻量级的时空 Transformer 分支,专门从单步噪声特征中“滤除”噪声,提取出:
- 几何前瞻 (Geometric Foresight):通过模拟 DPAv3 (Depth Anything 3) 的表征,解决单目视觉的深度歧义。
- 语义前瞻 (Semantic Foresight):通过模拟 DINOv2 的 Patch-level 表征,识别任务相关的物体特征。
2. 自蒸馏策略 (Self-Distillation)
这是本文最精妙的设计。为了训练上述解耦器,S-VAM 使用了**“自己教自己”**的方法:
- 教师端:使用完整的 VDM 多步推理生成的视频,提取出稳定的 VFM 特征。
- 学生端:解耦器尝试仅用一步推理的噪声特征去逼近上述目标。 这种方式确保了特征空间在同一个扩散轨迹(Diffusion Trajectory)上,避免了直接用 Ground Truth 训练带来的轨迹偏差。
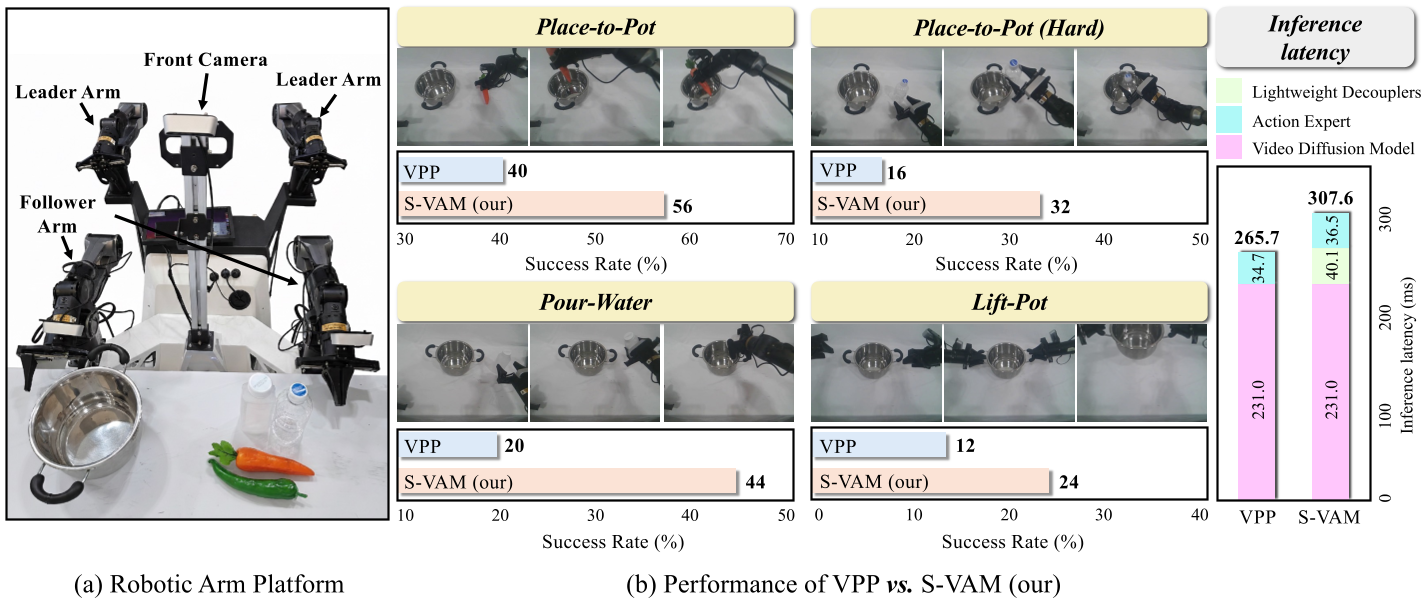
实验与战绩:战胜透明与复杂性
模拟器刷榜
在 CALVIN 连续任务基准测试中,S-VAM 取得了 4.16 的惊人成绩,不仅超越了同门师兄 VPP,更击败了 π0 和 OpenVLA 等一众重量级基线。
攻克透明物体(Real World)
在真实世界实验中,S-VAM 展示了对透明水杯和反光金属锅的极强操控力。这类物体在普通视觉模型中由于缺乏几何稳定性极难处理,但 S-VAM 通过解耦后的几何前瞻,成功将“向透明杯倒水”等任务的成功率从 VPP 的 16% 提升到了 32%。
深度洞察:为什么选择 DPAv3 + DINOv2?
消融实验(Tab. 4)给出了非常有趣的 Inductive Bias 结论:
- 语义层面:DINOv2(细粒度 Patch)远优于 SigLIP(全局语义)。这说明对于底层控制,局部特征的区分度比全局摘要更重要。
- 几何层面:动态视频训练的 DPAv3 优于静态的 VGGT。机器人需要的是“物体如何运动”的几何感,而非静态的场景重建。
总结与局限 (Critical Analysis)
S-VAM 证明了视频生成模型不仅是演示器,更是极佳的特征提供者。它的局限性在于:目前仍依赖外部预训练的 VFM 作为蒸馏目标,如果能完全从物理模拟中自监督学习这些解耦特征,模型的通用性将进一步增强。
对于未来的具身大模型,S-VAM 这种“重表征解耦、轻生成步骤”的思路,将是走向低延迟、高精度闭环控制的核心路径。