本文提出了 S2D2,一种针对块扩散语言模型(Block-diffusion LLMs)的无需训练的自推测解码(Self-speculative Decoding)框架。该方法通过复用同一个预训练模型在不同块大小下的特性,实现了比自回归解码高 4.7 倍、比动态阈值扩散解码高 1.57 倍的加速效果,并能同步提升生成质量。
TL;DR
在大型语言模型(LLM)的推断优化领域,自回归(AR)模型因其严重的内存带宽限制而显得步履蹒跚。虽然扩散模型(Diffusion Models)带来了并行生成的曙光,但在追求极限推断速度时,往往会牺牲掉生成文本的连贯性。本文介绍的 S2D2 (Self-Speculative Decoding) 框架,巧妙地利用了块扩散模型的一个“隐藏属性”:同一个模型,只要把 Block Size 设为 1,它就是一个完美的自回归验证器。 这一发现让模型可以在无需任何额外训练的情况下,实现质量与速度的双重飞跃。
痛点深挖:扩散模型的“快”与“乱”
目前最前沿的文本扩散模型(如 LLaDA, SDAR)通常采用块扩散(Block-wise Diffusion)策略。它们试图在每个 Block 内并行生成多个 Token,但面临一个本质困境:
- 序列依赖性缺失:在减少去噪步数(Few-step regime)以加速时,模型倾向于独立地预测每个位置,忽略了 Token 间的深度语义耦合,导致逻辑断层。
- 置信度陷阱:传统的置信度阈值解码非常脆弱,阈值设得高则慢,设得低则胡言乱语。
- 成本高昂:现有改进方案(如 EDLM)往往要求训练专门的能量模型(Energy Model),增加了算力和工程复杂度。
核心机制:S2D2 的“变色龙”策略
S2D2 的天才之处在于它不需要任何“外部辅助”。它将推断过程转化为了一个内部的推测游戏:
1. 身份复用(Self-Verification Mode)
对于一个预训练好的块扩散模型,作者发现:
- 推测器 (Drafter):使用正常的 Block-diffusion 模式并行产生 Token 建议。
- 验证器 (Verifier):将模型切换至 Block-size=1 的掩码模式。此时,模型退化为经典的自回归视图。
通过引入一种名为 "2L Trick" 的注意力掩码矩阵,S2D2 可以在单次前向传播中,同时计算出所有预测 Token 在自回归视图下的条件概率。
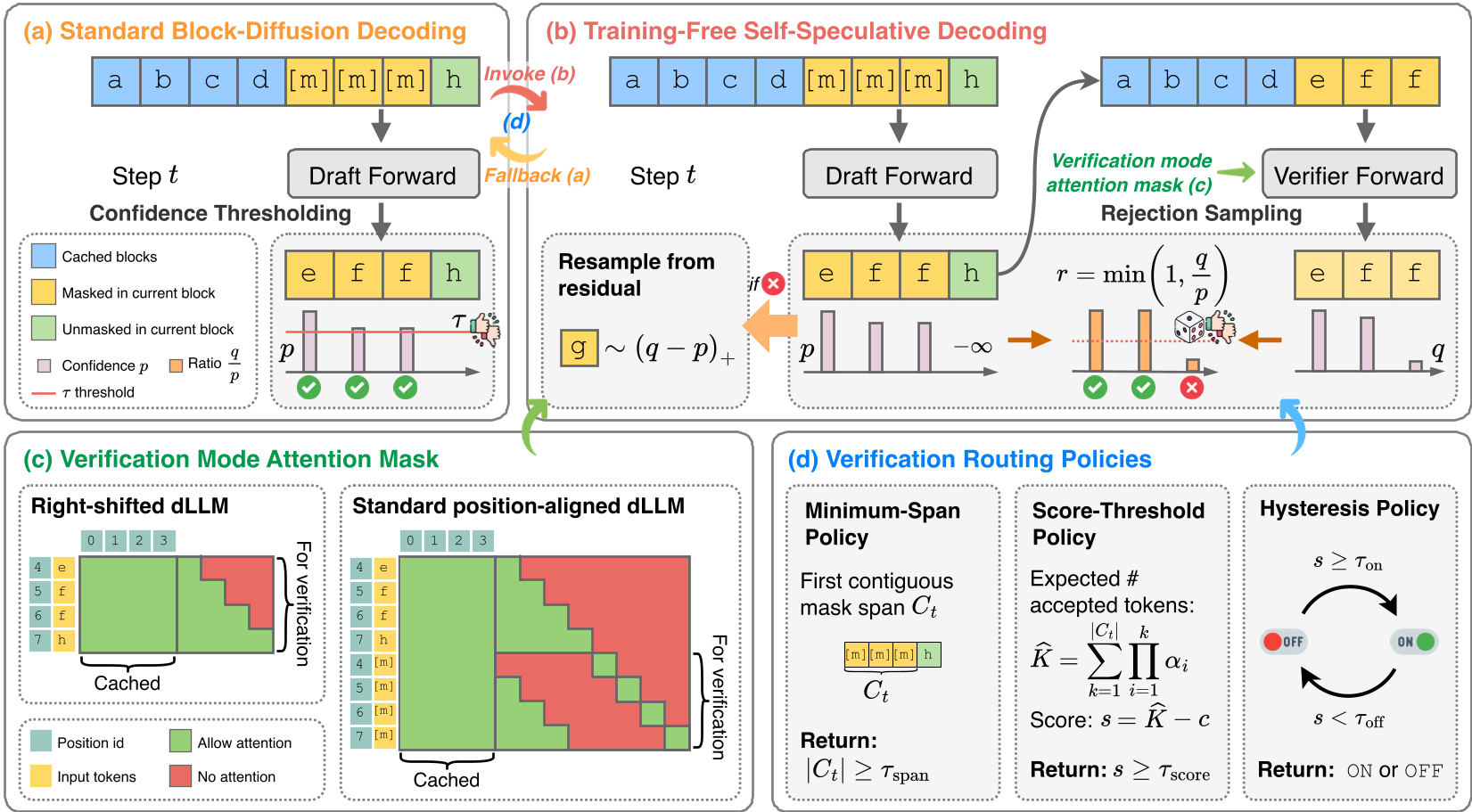 图 1:S2D2 架构示意图,展示了从标准扩散到自推测验证的切换。
图 1:S2D2 架构示意图,展示了从标准扩散到自推测验证的切换。
2. 智能路由(Routing Policies)
并不是所有的 Step 都值得验证。验证步会带来额外的前向传播开销。S2D2 引入了多种路由策略(如 Minimum-span, Hysteresis 等)来判断:当前的预测块是否足够长?置信度是否有大幅波动的风险?只有在“有利可图”时,才会启动自回归验证。
实验与结果:速度与准确率的罕见正相关
在 SDAR 及 LLaDA 多个量级的模型上,S2D2 展现出了惊人的一致性提升。
- 性能狂飙:在 SDAR-1.7B 上,相比自回归解码实现了 4.7 倍 的加速;相比目前最强的动态阈值基线,加速比也达到了 1.57 倍。
- 质量反哺:令人意外的是,速度变快的同时准确率反而提升了。在 GSM8K 任务中,平均准确率提升了约 4.5 个百分点。这说明自回归验证有效地通过“局部序列批评家”的角色,修正了扩散过程中的逻辑错误。
 表 1:SDAR 系列模型在各基准测试下的表现,可见 S2D2 (Config-B) 在速度和准确率上均处于前沿。
表 1:SDAR 系列模型在各基准测试下的表现,可见 S2D2 (Config-B) 在速度和准确率上均处于前沿。
深度洞察:为什么这有效?
从数学直觉上看,S2D2 实际上是在执行一种随机贪婪的局部能量修正。扩散模型提供的推测分布(Draft Distribution)是一个粗糙的近似,而自回归视图提供的验证分布(Verifier Distribution)拥有更强的条件依赖。通过拒绝采样(Rejection Sampling),S2D2 将生成的轨迹推向了能量更低、更符合人类语言逻辑的分布区域。
总结与局限
S2D2 证明了扩散 LLM 不需要复杂的辅助模型就能跑得又快又稳。
- 优点:Plug-and-play(即插即用),无需重训练,由于复用 KV Cache,推断内存占用增加微乎其微。
- 局限性:目前主要针对块扩散架构,对于纯全局采样(Global Sampling)的扩散模型,注意力掩码的改造可能更为复杂。
展望未来,这种“自推测”的思想可能会成为扩散模型推断的主流配置,甚至可能启发我们在训练阶段就更好地利用这种 AR-Diffusion 的对偶性。