[ACL 2025] 精准外科手术:定位并干预 LLM 中的安全关键参数
Summary
Problem
Method
Results
Takeaways
Abstract
本文提出了 Expected Safety Impact (ESI) 框架,通过可微判别模型和一阶泰勒展开,量化并定位大语言模型(LLM)中的安全关键参数。基于此,作者开发了 SET(用于快速安全对齐)和 SPA(用于下游任务微调时的安全保持)两种干预范式,显著提升了模型在对抗攻击下的鲁棒性。
TL;DR
浙江大学的研究团队提出一套名为 Expected Safety Impact (ESI) 的框架,首次精准勾勒出了大语言模型内部的“安全版图”。研究发现:密集模型的安全中枢在中层 Value 矩阵,而 MoE 模型则在后层 MLP 专家中。 基于此发现,研究者实现了仅更新 1% 参数即可完成快速安全对齐(SET),并在下游任务微调中实现了近乎零损耗的安全保持(SPA)。
1. 动机:安全对齐的“脆弱性”之谜
当前的 LLM 尽管经过了 RLHF 或 SFT 对齐,但在面对特定的下游任务微调(Instruction Tuning)时,其安全性往往会迅速崩溃。这种现象被称为“安全退化”。
- 痛点:我们不知道安全能力到底存储在哪些参数里。
- 先前方案的局限:以往的方法(如 SNIP, Wanda)大多基于交叉熵损失(Cross-entropy Loss)或权重绝对值,这更像是寻找“有用”的参数,而非专门针对“安全”的参数。
作者给出的 Insight 是:安全是一个期望值概念。我们需要衡量的是:如果某个参数变了,模型输出有害内容的概率会发生多大变化?
2. 核心技术:ESI 框架与可微判别器
ESI 的核心公式极具直觉:
abla_{ heta_i} \mathcal{S}( heta)|$$ 其中 $\sigma( heta_i)$ 是参数的标准差,代表了微调时该参数可能的变动幅度;$ abla_{ heta_i} \mathcal{S}$ 则代表了安全敏感度。 ### 攻克不可微难题 计算梯度的最大难点在于 LLM 生成 Token 是离散采样的。作者巧妙地通过以下链路解决了这一问题: 1. **Gumbel-Softmax 重新参数化**:将离散 Token 转化为连续向量。 2. **词表映射矩阵 (M)**:解决目标 LLM 与判别器(Judge Model)词表不一致的问题。 3. **可微判别器**:使用 Llama-Guard 等模型作为判别函数,反向传播安全得分。  ## 3. 跨架构的安全模式分析 通过 ESI 对主流模型进行排查,研究者发现了有趣的现象: * **Dense 模型 (如 Llama3)**:安全关键参数聚集在**中间层**,特别是 Self-Attention 的 **Value (V) 矩阵**。 * **MoE 模型 (如 Qwen3, Mixtral)**:安全关键参数向**后层**偏移,且高度集中在 **MLP 专家模块**中。 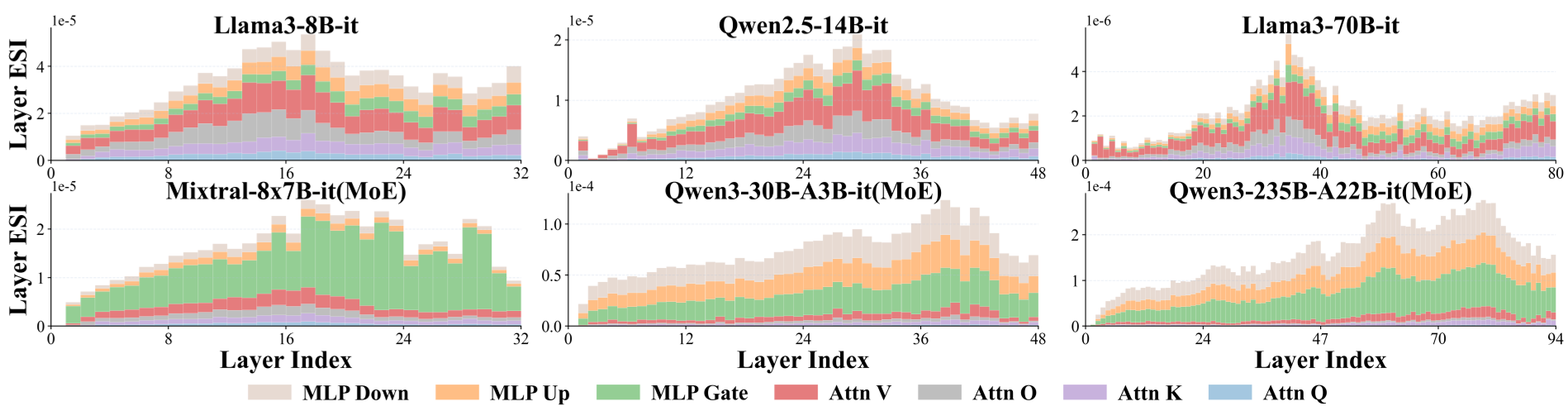 ## 4. 两大干预范式:SET 与 SPA ### Safety Enhancement Tuning (SET) 针对未对齐的“白板”模型。 * **操作**:仅冻结 99% 的参数,只对识别出的 1% 安全关键参数进行微调。 * **效果**:在极短的迭代内(100 steps),ASR 显著下降,且不破坏模型的通用能力(Reasoning, Coding)。 ### Safety Preserving Adaptation (SPA) 针对已对齐模型进行下游适配。 * **操作**:在微调下游任务(如医学 QA)时,**固定死**那 10% 的安全参数,只更新非敏感区域。 * **效果**:彻底解决了微调导致的安全护栏失效问题。 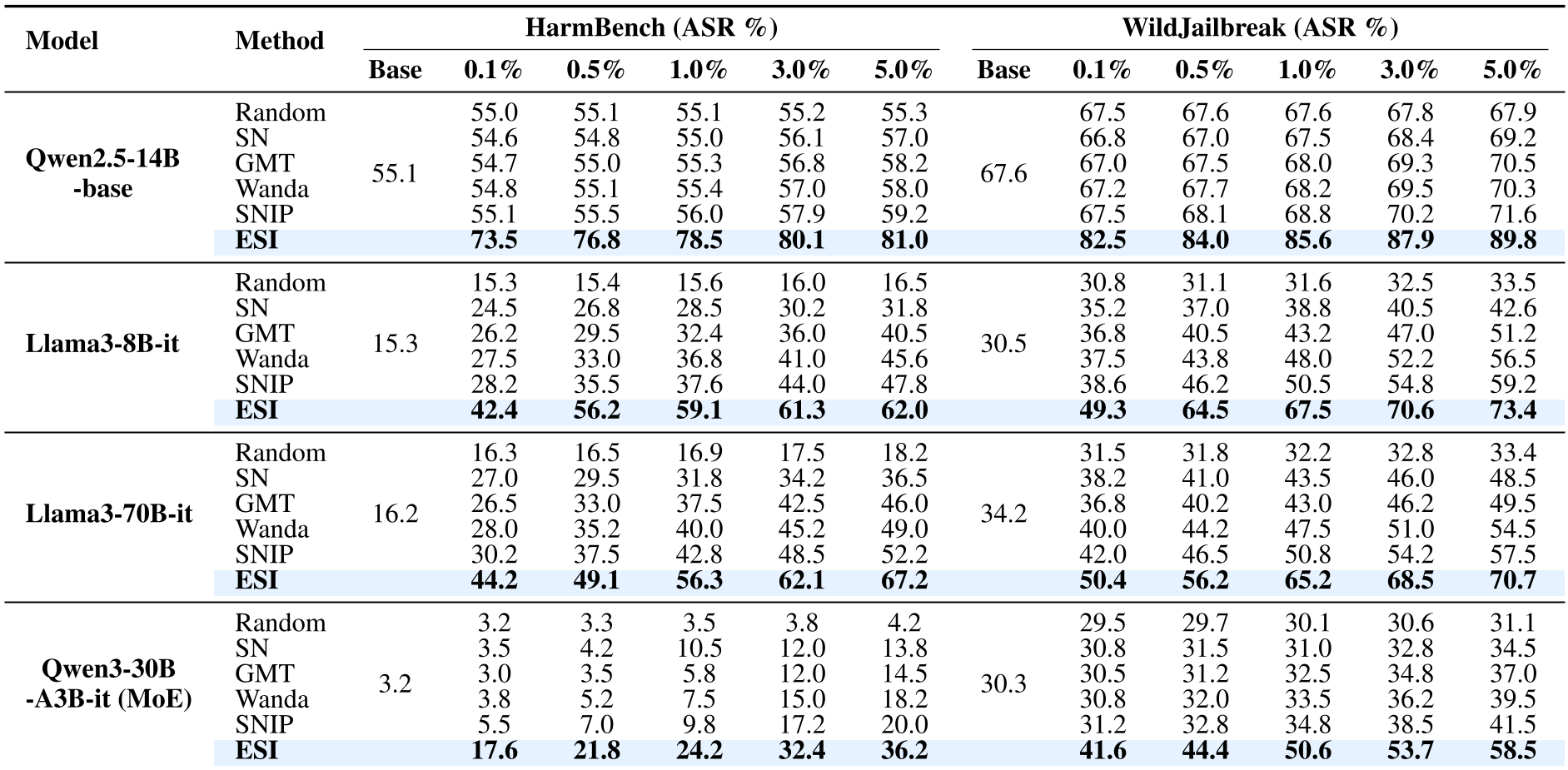 *在 Llama3-8B-it 上,扰动仅仅 1% 的权重(ESI 识别),ASR 即可从 15.3% 暴涨至 59.1%,充分证明了精准定位的威力。* ## 5. 深度洞察 这项工作不仅提供了一个工具,更揭示了 LLM 安全性的一种“稀疏性”本质。这意味着,我们未来或许不需要在大规模对齐上耗费数千 GPU 小时,而只需要像外科医生一样,对模型的特定“神经中枢”进行微量修正,即可达到极高的安全性。 **局限性**:目前该方法依赖于获取模型的参数梯度,因此主要适用于开源模型。对于闭源模型,如何通过黑盒探测实现同等精度的参数定位仍是未来的课题。 ## 总结 ESI 框架通过数学直觉和可微化工程,将 LLM 的安全研究从“黑盒试探”推向了“白盒精准干预”。它告诉我们:安全不是一种玄学,而是一组可以被量化、定位并永久锁定的特定权重。