SAGE (Self-evolving Agents for Generalized reasoning Evolution) is a closed-loop multi-agent framework that enables LLMs to co-evolve using four specialized roles: Challenger, Planner, Solver, and Critic. It achieves SOTA gains on reasoning benchmarks, improving Qwen-2.5-7B by 10.7% on OlympiadBench and 8.9% on LiveCodeBench using only 500 seed examples.
TL;DR
The research community has hit a bottleneck: we need more high-quality reasoning data to train better LLMs, but human experts are expensive and slow. SAGE (Self-evolving Agents for Generalized reasoning Evolution) solves this by turning a single LLM into a four-agent ecosystem. By generating its own "curriculum" of math and coding problems, SAGE enables models like Qwen-2.5 to autonomously improve their reasoning scores by over 10% on elite benchmarks like OlympiadBench, starting from just a tiny seed of 500 examples.
Background: The Limits of Human-in-the-Loop
Traditional Reinforcement Learning (RL) for LLMs relies on massive libraries of human-curated problems. As models approach "superhuman" reasoning, finding human data that is actually challenging enough becomes a bottleneck. While frameworks like DeepSeek-R1 have proven that RL with verifiable rewards (binary pass/fail on code or math) works, they still struggle with curriculum drift—where a model gets good at simple tasks but fails to evolve toward more complex, multi-step problem solving.
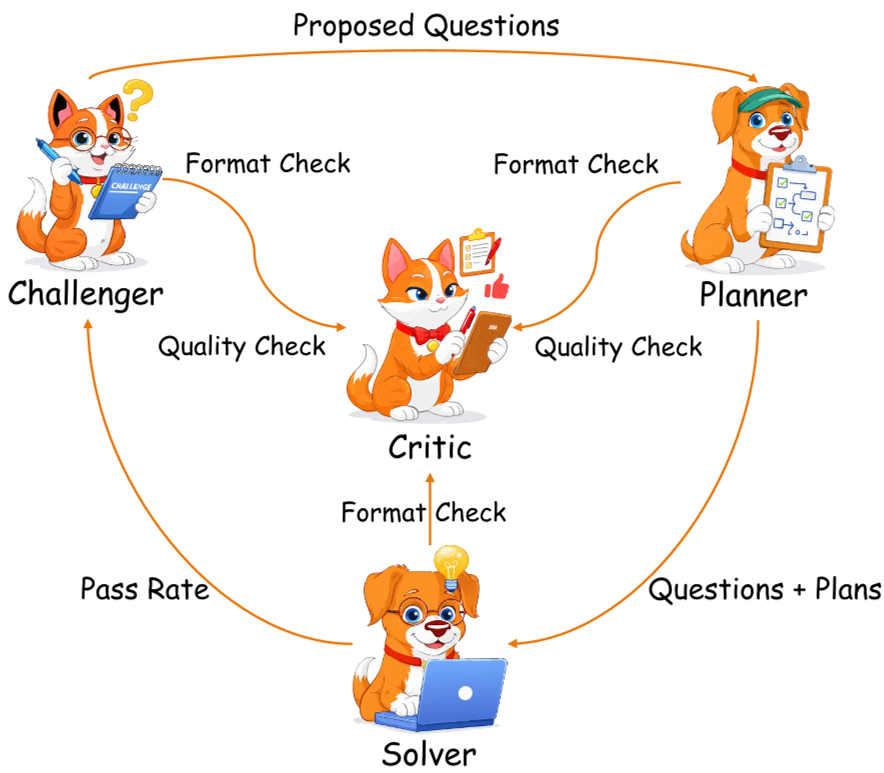
The SAGE Architecture: A Four-Agent Symbiosis
SAGE doesn't just ask the model to "think harder." It assigns the LLM four distinct personas that co-evolve on a shared backbone:
- The Challenger: The "Level Designer." It looks at seed problems and generates new, harder versions. It is rewarded when the Solver fails, incentivizing it to find the model's weaknesses.
- The Planner: The "Strategist." It breaks down the Challenger's task into logical, multi-step sequences.
- The Solver: The "Executor." It follows the plan to generate the final code or proof.
- The Critic: The "Gatekeeper." It filters out ill-posed questions from the Challenger and bad plans from the Planner to ensure the training signal remains "clean."
Why this works: Task-Relative REINFORCE++
Training four agents at once is numerically unstable—the "Challenger" has a completely different goal than the "Solver." SAGE employs Task-Relative REINFORCE++, a technique that normalizes advantages per role. This ensures that the gradient updates for the Challenger don't overwhelm the learning process of the Solver, allowing all four roles to level up in sync.
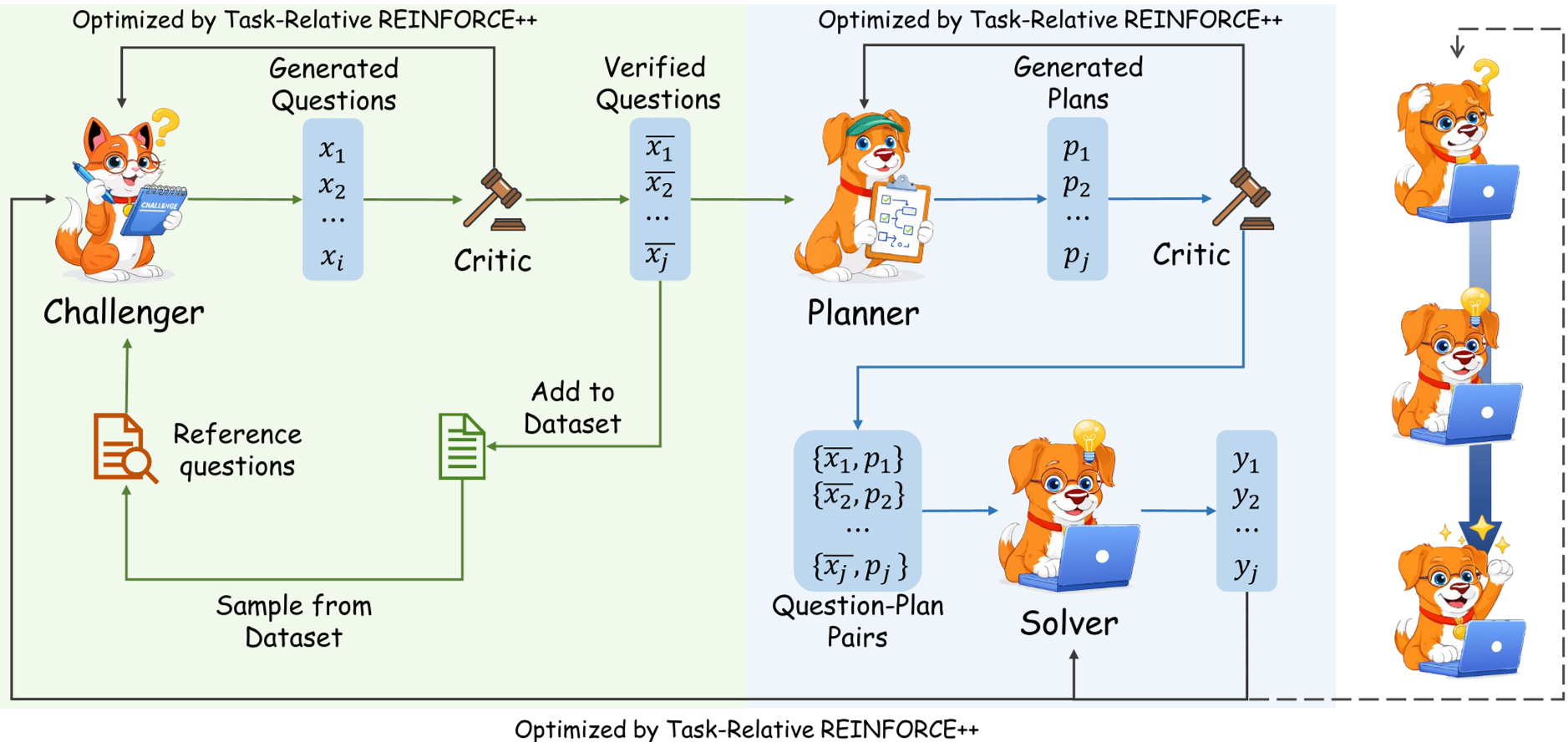
Methodology: The Self-Evolving Loop
The evolution follows a rigorous pipeline:
- Challenge Phase: The Challenger expands the dataset. The Critic ensures these new problems are high-quality.
- Plan-Solve Phase: The Planner creates a strategy. If the Critic approves of the plan (score 0.3), the Solver uses it. Otherwise, the Solver tries to solve it "zero-shot."
- Verification: The output is checked against a hard verifier (e.g., Python unit tests or math ground-truth).
Experimental Performance & SOTA Results
SAGE was tested on various model scales, including Qwen-2.5-3B, 7B, and the new Qwen-3-4B-Base.
- OlympiadBench: The 7B model saw a +10.7% absolute gain.
- LiveCodeBench: A rigorous OOD benchmark where SAGE consistently outperformed standard self-play baselines (like Absolute Zero) and multi-agent baselines (like MAE).
- Zero-Data Efficiency: Remarkably, the model expanded its training set from 500 items to over 20,000 valid questions autonomously.

Key Insight: The Necessity of Role Specialization
Ablation studies revealed that removing the Challenger caused code reasoning performance to tank (from 16.9% to 9.0% on LCB). Without a "Level Designer" creating new curriculum, the model simply overfits to its own existing knowledge and stops growing.
Critical Analysis & Future Outlook
Takeaway: Role-based decomposition is the future of LLM self-improvement. By separating "planning" from "execution," SAGE provides a template for solving tasks that are too complex for a single prompt.
Limitations: SAGE currently requires verifiable domains (where a compiler or math engine can check the answer). The "Holy Grail" for this tech will be moving it into non-verifiable domains like "strategic alignment" or "creative reasoning," where the "Verifier" itself must be a learned model.
Conclusion: SAGE proves that as long as we have a tiny seed of truth and an automated way to verify results, LLMs can "bootstrap" themselves into high-level reasoning experts without further human intervention.