本文提出了 SAM 3D Animal,这是第一个支持提示(Promptable)的多动物单目 3D 重建框架。该方法基于 SMAL+ 参数化模型,通过 DETR 式的集合预测机制实现了复杂野外场景下多个动物实例的联合三维姿态与形状恢复,在 Animal3D 等多个数据集上达到 SOTA 水平。
TL;DR
本文介绍了 SAM 3D Animal,这是业界首个支持交互式提示(Promptable)的单幅图像多动物 3D 重建框架。它不仅解决了传统方法难以处理的“多动物重叠”和“相互遮挡”痛点,还通过 DETR 式的端到端架构实现了高效的多实例联合恢复。配合同步推出的 Herd3D 大型多动物 3D 数据集,该模型在泛化性与精确度上均刷新了 SOTA 纪录。
背景:从“人类中心”转向“万物共生”
尽管人类 3D 重建(HMR)已取得长足进步,但动物 3D 重建仍面临巨大挑战。动物种类繁多、解剖结构差异巨大,且在自然界中常以“群体”形式出现。现有方法(如 AniMer, GenZoo)大多假设图像中只有一个被完美裁剪的动物,这种 Inductive Bias 在处理真实野外拥挤场景时会彻底失效。

核心动机:用“提示”破解歧义
受 Segment Anything (SAM) 的启发,作者提出:如果在复杂场景下给模型一个简单的指引(如点一下动物关节点,或给个简单的 Mask),是否能显著降低 3D 估计的搜索空间?
SAM 3D Animal 的核心逻辑在于:将 提示(Prompt) 作为一种额外的空间先验,引导 Transformer Decoder 聚焦于特定目标,从而解决实例关联歧义。
技术亮点详解 (Methodology)
1. 提示驱动的 Transformer 解码器
模型采用 ViT-Huge 作为 Backbone 提取特征,最核心的设计在于其 Decoder 结构。它不仅接收图像特征,还维护了一系列 Query Tokens,包括:
- 姿态与形状 Token (Q_params):预测 SMAL+ 参数。
- 位置 Token (Q_box):预测 Bounding Box。
- 关键点反馈 Token (Q_2D/3D):实现层级化的几何修正。
- 提示 Token (Q_prompt):融合用户输入的 Keypoints 或 Mask。
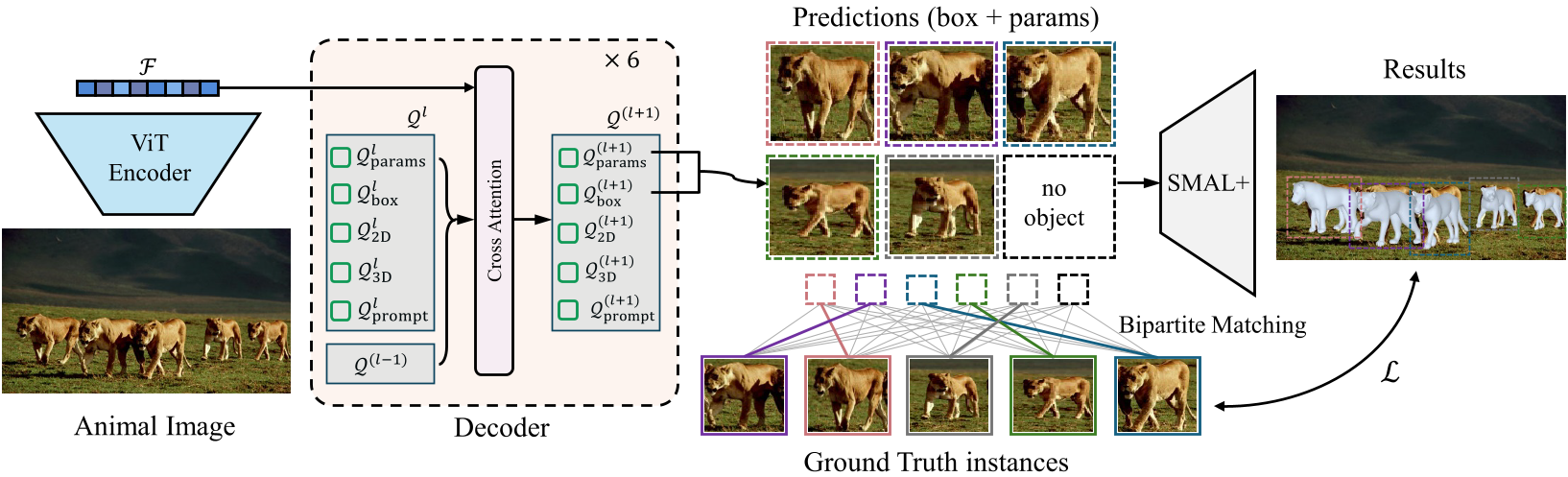
2. DETR 式的集合预测
不同于以往需要预先检测再裁剪的方法,SAM 3D Animal 采用 Set Prediction 范式。模型一次性输出 P=30 个候选实例,通过 匈牙利算法(Bipartite Matching) 将预测结果与 Ground-truth 进行最优匹配。这种设计天然支持多目标处理,且消除了对 NMS 的依赖。
3. Herd3D 数据集:补齐训练短板
为了训练这种多实例模型,作者开发了 Herd3D。利用生成式管道采样多达 8 个动物实例,并在共享的地平面上进行放置。这不仅极大地丰富了物种多样性,还提供了真实世界难以获取的“多动物重叠 3D 真值”。
实验战绩与消融分析
SOTA 对比
在多个基准测试中,SAM 3D Animal 展现了压倒性优势。特别是在 Animal Kingdom 数据集(OOD 场景)上,哪怕不给提示,其性能也优于专门针对单动物优化的 AniMer 和 GenZoo。

核心发现
- 提示的重要性:在重度遮挡(Low Visibility)下,加入提示带来的提升最为显著(mAP 提升约 57%)。随着可见部分增加,模型对提示的依赖程度自然下降,表现出极强的健壮性。
- 关键点 vs Mask:实验表明,关键点提示对 3D 重建的贡献远大于 Mask 提示,因为关键点直接契合了参数化模型的骨架约束。
总结与局限
SAM 3D Animal 填补了多动物联合 3D 重建的空白。它的成功归功于 “强大的生成式数据集 + 灵活的提示机制 + 端到端的 Transformer 架构”。
局限性:目前模型仍依赖 SMAL+ 模板,主要适用于四足哺乳动物(Quadrupeds)。对于长颈鹿等极端比例物种,或非四足动物,仍需更灵活的表示法(如 Model-free 技术)。此外,多动物间的显式深度排序(Depth Ordering)仍有待进一步优化,以避免严重的空间穿模现象。
本文由资深学术技术主编重构。