本文提出了 SAMA,一个基于 DiT 架构的长视频编辑框架。该方法通过将视频编辑分解为 Semantic Anchoring(语义锚定)和 Motion Alignment(运动对齐)两个解耦任务,实现了精准的指令遵循与高度的运动一致性,且在无需配对编辑数据的情况下即展现出极强的 Zero-shot 能力。
TL;DR
在视频编辑领域,精确执行“让这只猫穿上西装”这类指令的同时不让背景崩坏一直是个难题。百度与清华等机构联合提出的 SAMA (Semantic Anchoring and Motion Alignment) 框架,通过“化繁为简”的策略,将语义规划与运动建模解耦。它不依赖昂贵的深度图预测,仅凭自身内化的“运动直觉”和“语义锚点”,就在多项基准测试中超越了现有开源 SOTA,并直面硬刚商业闭源系统。
痛点深挖:语义与运动的“零和博弈”
目前的视频编辑模型(如基于 Stable Diffusion 改造的模型)在处理指令时,往往陷入两难:
- 过度编辑:为了遵循指令(如改变物体类别),模型破坏了视频原有的运动轨迹,导致物体漂移。
- 保守编辑:为了保持一致性,模型不敢做大幅度修改,导致编辑效果不明显。
作者认为,这是因为模型没有真正理解“什么该变”和“物理运动规律”。
核心方法论:SAMA 的双轮驱动
SAMA 的核心在于将复杂的视频编辑任务拆解为两个可学习的内在能力:
1. Semantic Anchoring (SA):寻找视觉定海神针
SAMA 不再盲目进行逐帧扩散,而是先在稀疏锚定帧(Anchor Frames)上预测语义 Token。
- 逻辑直觉:只要确定了第 1 帧和第 N 帧的语义结构(例如猫变成了穿西装的猫),中间帧的生成就有了参考系。
- 技术实现:利用 SigLIP 提取特征并投影到 DiT 的 Latent 空间,作为辅助预测任务,这大大增强了模型对复杂指令(如“左边的人变成机器人”)的方位感知能力。
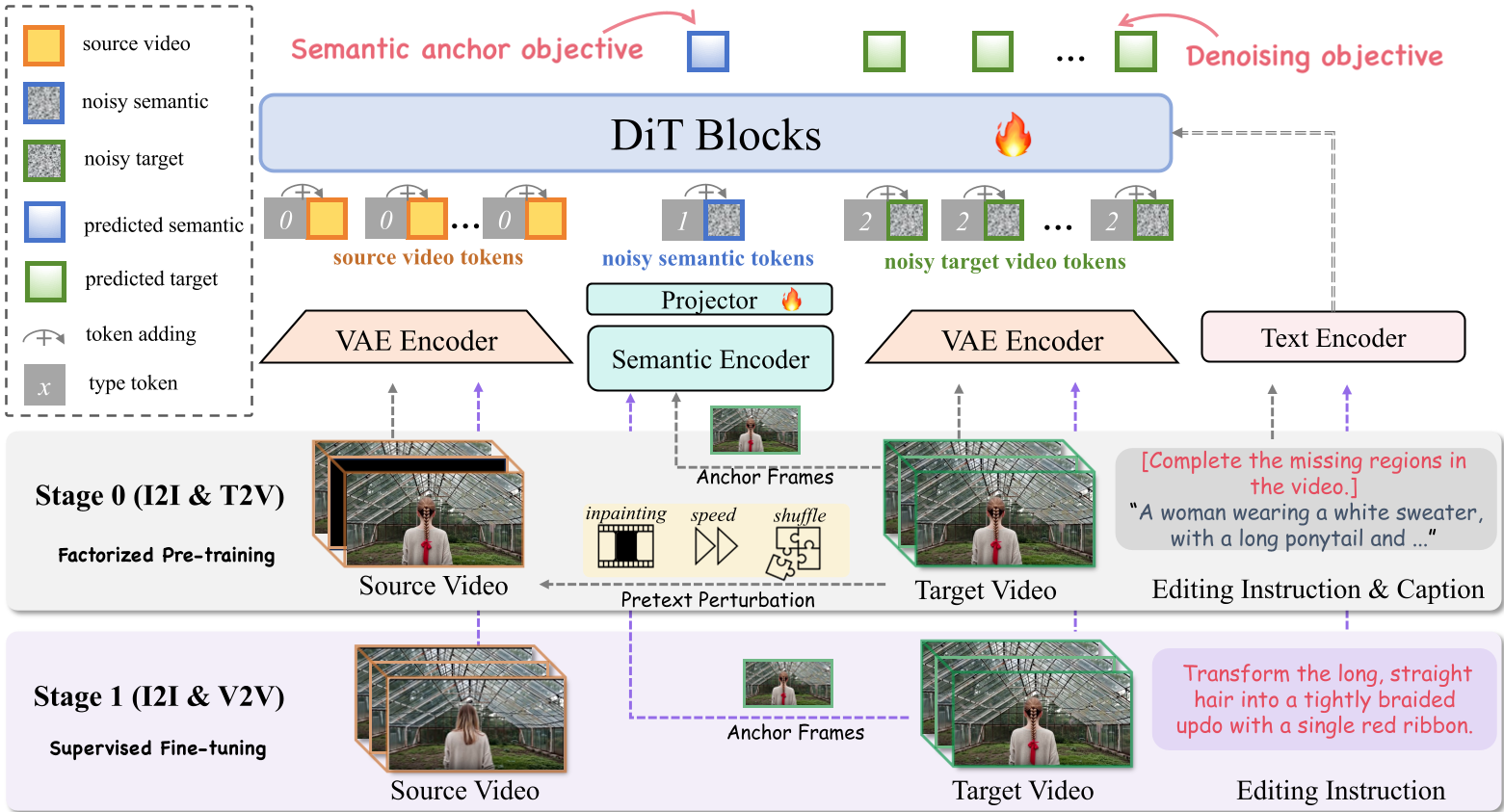
2. Motion Alignment (MA):赋予模型“运动常识”
如何让模型学会视频里的物理规律?SAMA 借鉴了自监督学习的思想,在 Stage 0 阶段让模型做“视频找茬/修复”:
- Cube Inpainting:遮住一坨区域让模型补全,学习空间一致性;
- Speed Perturbation:改变播放速度让模型还原,学习速度感;
- Tube Shuffle:打乱时空块让模型排序,学习运动连续性。
这种方法让模型直接从大量原始视频中学习运动先验,从而在编辑时即使面对剧烈相机运动也能保持背景稳定。

实验战绩:开源界的领跑者
SAMA 在 VIE-Bench 和 ReCo-Bench 等权威榜单上展现了恐怖的统治力。特别是在 Swap/Change(物体替换) 和 Remove(移除) 任务上,它比许多商业模型还要稳。
- Zero-shot 奇迹:即便在没有任何“成对编辑数据”的情况下,仅完成 Stage 0 预训练的模型就已经具备了极强的视频编辑能力。
- 效率提升:SA 机制的引入不仅提升了效果,还显著降低了训练时的 Loss 震荡,让大型 Transformer 模型收敛得更快。
 可以看到,加入 MA 后,快节奏运动下的背景文字依然锐利,而 Baseline 已经模糊。
可以看到,加入 MA 后,快节奏运动下的背景文字依然锐利,而 Baseline 已经模糊。
深度洞察与总结
SAMA 的成功标志着视频编辑正在从“依赖外部工具(ControlNet/VLM)”转向“模型原生理解”。其 Type Embedding 的设计巧妙地避开了位置编码(RoPE)在不同角色 Token 切换时的混乱,保证了 Source 和 Target 视频序列的精准对齐。
局限性:尽管 SAMA 非常强大,但在处理物体“消失再出现”的极端遮挡场景时,仍可能存在微小的 Ghosting 效应。未来的长视频编辑领域,SAMA 的这种解耦思想无疑将成为主流。