The paper introduces SAW-INT4, a system-aware 4-bit KV-cache quantization framework for Large Language Model (LLM) serving. It identifies that while high compression ratios are possible, they often fail in production due to paged memory layouts and fused kernel constraints. The authors demonstrate that token-wise INT4 quantization combined with a lightweight block-diagonal Hadamard rotation (BDR) achieves near-lossless accuracy while matching the throughput of native INT4.
TL;DR
The memory bottleneck in LLM serving is no longer the model weights, but the KV-Cache. While many papers claim "lossless" 2-bit or 4-bit compression, they often break when deployed in optimized systems like vLLM or SGLang. SAW-INT4 proves that a simple Block-Diagonal Hadamard Rotation combined with standard INT4 quantization is the "Goldilocks" solution: it recovers nearly all accuracy lost to outliers while adding zero measurable overhead to serving throughput.
Background: The "System Gap" in Quantization
In the world of LLM serving, throughput is king. Modern engines use PagedAttention to manage memory and Fused Kernels to minimize GPU global memory access. Many advanced compression methods (like Vector Quantization or Mixed-Precision) require:
- Codebook lookups: Adding irregular memory latency.
- Separate page tables: Breaking the uniform layout of PagedAttention.
- Non-coalesced access: Destroying GPU memory bandwidth efficiency.
As a result, a "theoretically" 2-bit model might actually serve slower than a 16-bit model because it cannot leverage the most optimized system kernels.
The Problem: The Outlier Nightmare
Naive INT4 quantization fails because LLM activations (especially Keys) have "outlier channels"—dimensions where values are significantly larger than others. In a token-wise quantization scheme, these outliers force the quantization grid to be very wide, causing massive precision loss for all other "normal" values in that vector.
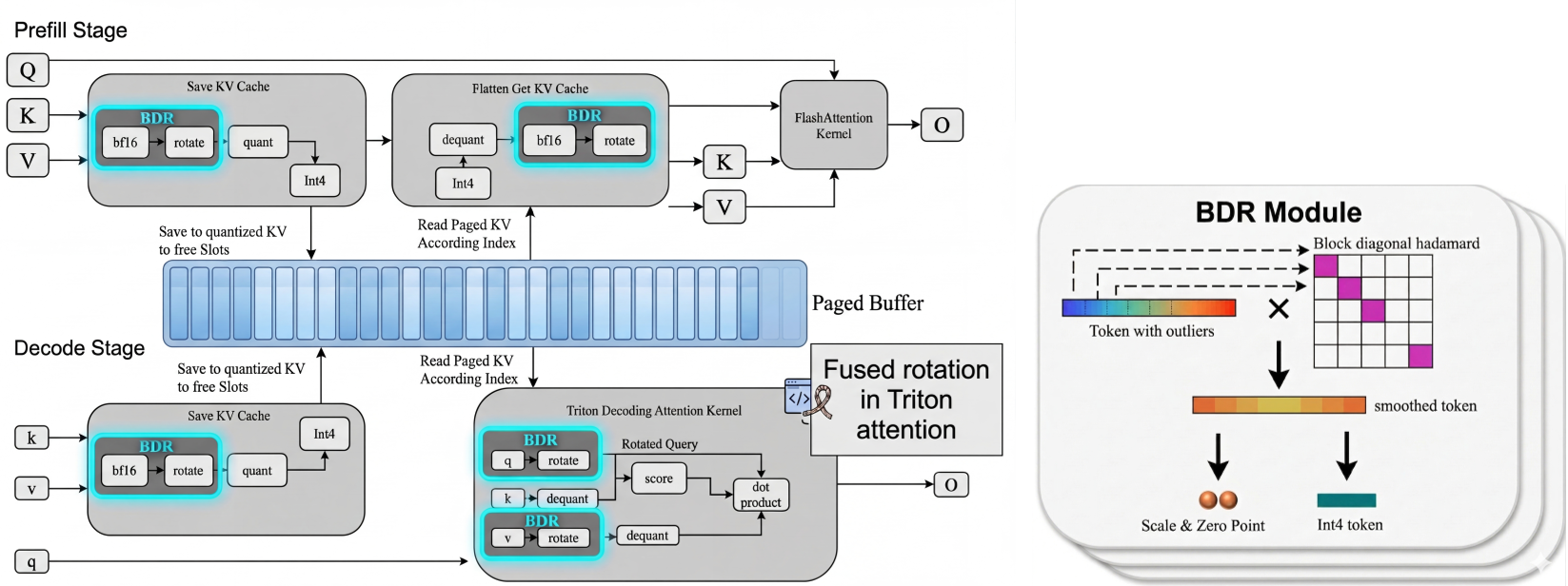
The Core Insight: Block-Diagonal Rotation (BDR)
Instead of complex outlier-aware schemes, SAW-INT4 uses a mathematical "smoothing" trick: Orthogonal Rotation.
1. The Physics of the Hadamard Transform
By multiplying the KV vectors by a Hadamard matrix, the energy of a single outlier channel is redistributed across all channels in a block. This "smooths" the distribution, making the vector much easier to quantize into 4 bits.
2. Why "Block-Diagonal"?
A full rotation over a 128-dimension head is computationally expensive. SAW-INT4 uses Block-Diagonal Rotation (BDR), breaking the rotation into independent smaller blocks (e.g., size 64 or 128). This allows for massive parallelism and fits perfectly into GPU register constraints.
3. System-Aware Fusion
The authors don't just add a rotation step; they fuse it. The rotation happens "on-the-fly" inside the Attention kernel as the data is streamed from memory. This means the GPU never has to write intermediate rotated values back to global memory, keeping the operation memory-bandwidth bound and practically "free" in terms of time.
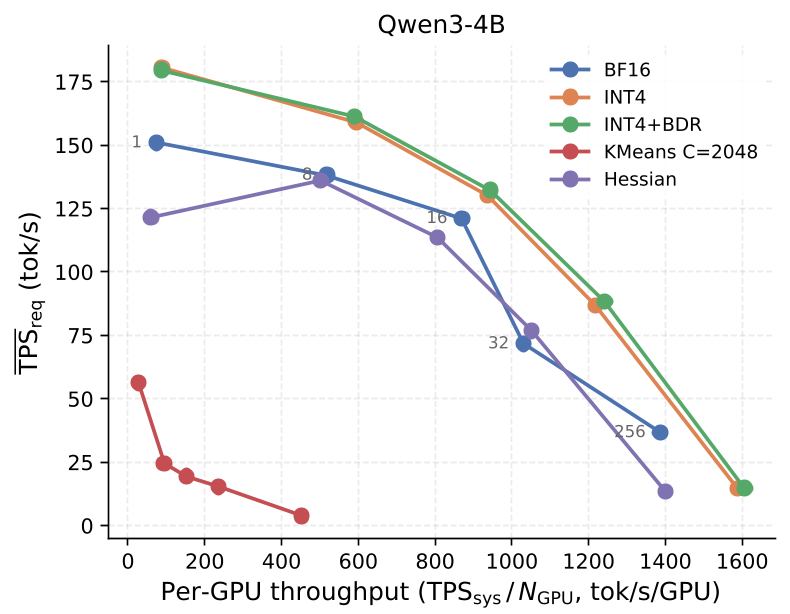
Performance: Accuracy vs. Efficiency
The results are striking. On sensitive models like Qwen3-4B, naive INT4 essentially produces gibberish (0% accuracy). Adding BDR-128 brings it back to 73.78%, nearly matching the BF16 baseline of 75.64%.
When looking at throughput (TPS), more complex methods like Kitty or K-means struggle to keep up with optimized unquantized baselines. In contrast, SAW-INT4 (Green) tracks the performance of plain INT4 (Red) perfectly, both significantly outperforming BF16 (Blue) as the number of concurrent users increases.
Detailed Experimental Breakdown
The paper reveals that:
- Rotation on Keys is enough: Values (V) are more robust; rotating only Keys (K) captures most of the gain.
- Complexity yields diminishing returns: Adding K-means or Hessian-aware logic on top of rotation adds significant deployment friction for only ~0.5% accuracy gain.
Critical Analysis & Takeaways
The brilliance of SAW-INT4 lies in its pragmatism. It acknowledges that an algorithm's value is capped by its "implementability."
- The Lesson: In the race for LLM efficiency, we should look for "system-friendly" math. Orthogonal transforms are ideal because they preserve the L2 norm and attention scores while making the data "quantization-friendly."
- Limitations: While 4-bit is now rock-solid, pushing to 2-bit still requires more complex "Residual" or "Vector" schemes that BDR alone cannot fully solve without high overhead.
- Future Work: This methodology paves the way for 4-bit serving to become the default standard in production engines like vLLM, potentially doubling the number of users a single H100 can support.
Final Thought: If you are deploying LLMs today, stop looking for complex compression; just rotate your Keys and quantize to INT4. Your throughput—and your users—will thank you.