本文提出了 SAW-INT4,一种面向真实 LLM 推理系统的 4-bit KV-Cache 量化方案。核心方法是“Token-wise INT4 量化 + 块对角 Hadamard 旋转 (BDR)”,在 Qwen3、GLM-4 等模型上实现了近乎无损的精度,并在 SGLang 框架下保持了 4x 的显存压缩比与 SOTA 吞吐量。
TL;DR
随着 LLM 上下文长度迈向数百万甚至千万级,KV-Cache 显存占用已取代模型权重成为推理吞吐量的头号杀手。SAW-INT4 是一项旨在缩合“学术指标”与“工业部署”鸿沟的研究。它证明了:无需复杂的向量量化或动态保留,仅需块对角 Hadamard 旋转 (BDR) 配合 Token-wise INT4,并深度融合进 SGLang 算子中,即可在保持 SOTA 吞吐量的同时,将长文本 KV-Cache 显存压缩 75% 且精度几乎无损。
1. 痛点:为什么学术界的 SOTA 方案在生产环境“跑不动”?
目前许多高效的 KV-Cache 压缩论文在离线测试(Offline Accuracy)中表现惊艳,但在集成到 vLLM 或 SGLang 等高性能推理引擎时,往往会遭遇“系统墙”:
- 内存布局冲突:PagedAttention 要求内存以固定大小的页面存储,而诸如 KIVI 或 Kitty 等混合精度方法会破坏这种一致性,导致页面管理极其复杂。
- 算子融合代价:高性能解码依赖 FlashAttention。向量量化(VQ)需要的 Codebook 查询或复杂的残差计算会增加寄数器压力,导致 kernel 执行变慢。
- 不规则访问:通道量化(Channel-wise)在分页内存中涉及非连续跳转,严重拖累 GPU 带宽利用率。
作者发现,如果不考虑系统兼容性,量化精度再高也无法提升真正的系统吞吐量(TPSsys)。
2. 核心直觉:旋转——对抗离群值的“银弹”
为什么朴素的 INT4 甚至会让模型输出乱码?根本原因在于通道间的离群值 (Outliers)。极少数维度的超大值拉开了解码网格,导致大部分通道的信息在量化中丢失。
SAW-INT4 引入了块对角 Hadamard 旋转 (BDR)。
- 原理:利用正交变换的性质,在量化前将高能通道的能量“散射”到周围维度中,从而平滑特征分布。
- 块对角设计:不进行全维度的全局旋转(成本太高),而是将 Head Dimension 划分为 16 到 128 长度的小块独立旋转。这既保留了平滑效果,又极大地提升了 GPU 的并行加速比。
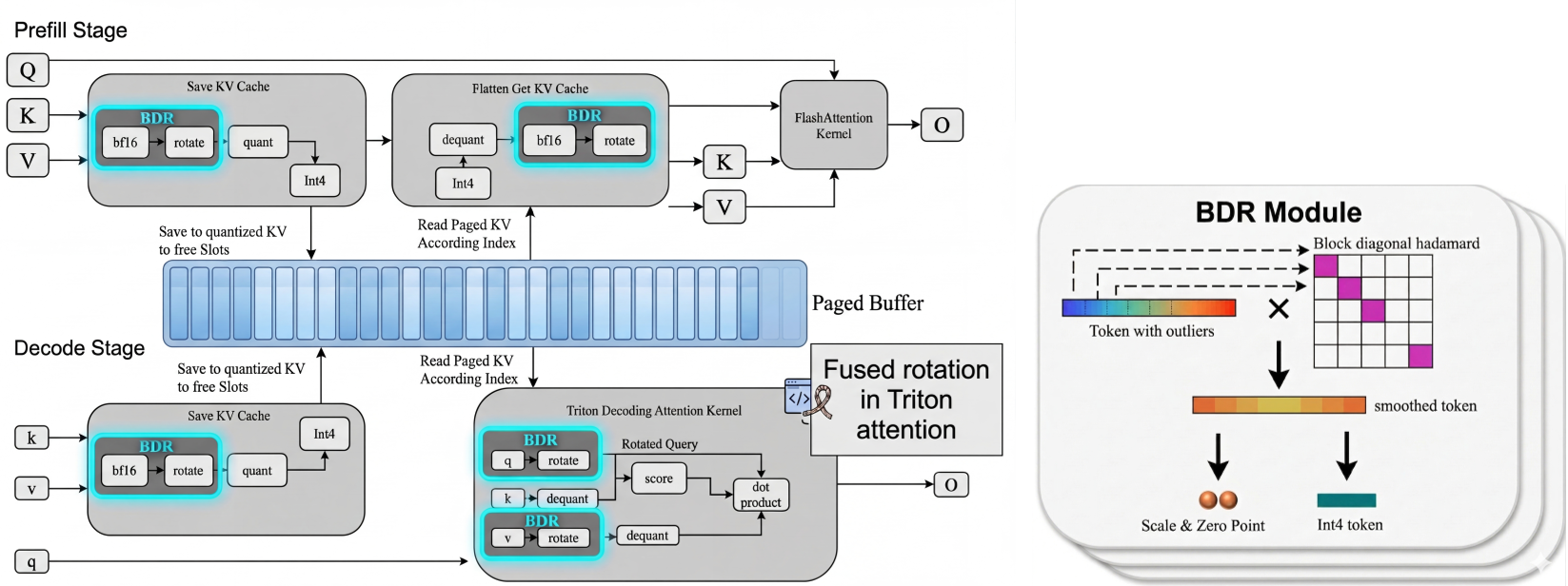
3. 方法论详解:系统与算法的协同设计
作者不仅仅提出了 BDR 算法,还开发了 Fused Rotation-Quantization Kernel。
核心公式背后的逻辑:
通过将旋转阵 变成块对角形式,计算开销被压缩到极低。关键在于,旋转过程被直接融合 (Fuse) 到了 KV-Cache 写入算子中。这意味着:
- 不再需要单独启动一个 Kernel 处理旋转。
- 计算开销被原本的显存绑定(Memory-bound)延迟所掩盖。
- 查询(Query)在推理时同步旋转,两者的点积结果与原始空间数学等价。
4. 实验与结果:实战中的降维打击
实验涵盖了 Qwen3 多种尺度及其“思考”模式。
精度恢复:在 Qwen3-4B 上,朴素 INT4 的结果几乎为 0,而应用 BDR-128 后,平均分从 0 分直接拉升至 73.78(BF16 基线为 75.64)。 吞吐量表现:在长文本、高并发场景下,SAW-INT4 的系统吞吐量(TPSsys)在所有被测模型中均优于 BF16,且由于计算融合良好,其性能几乎与不带旋转的朴素 INT4 完全重合。
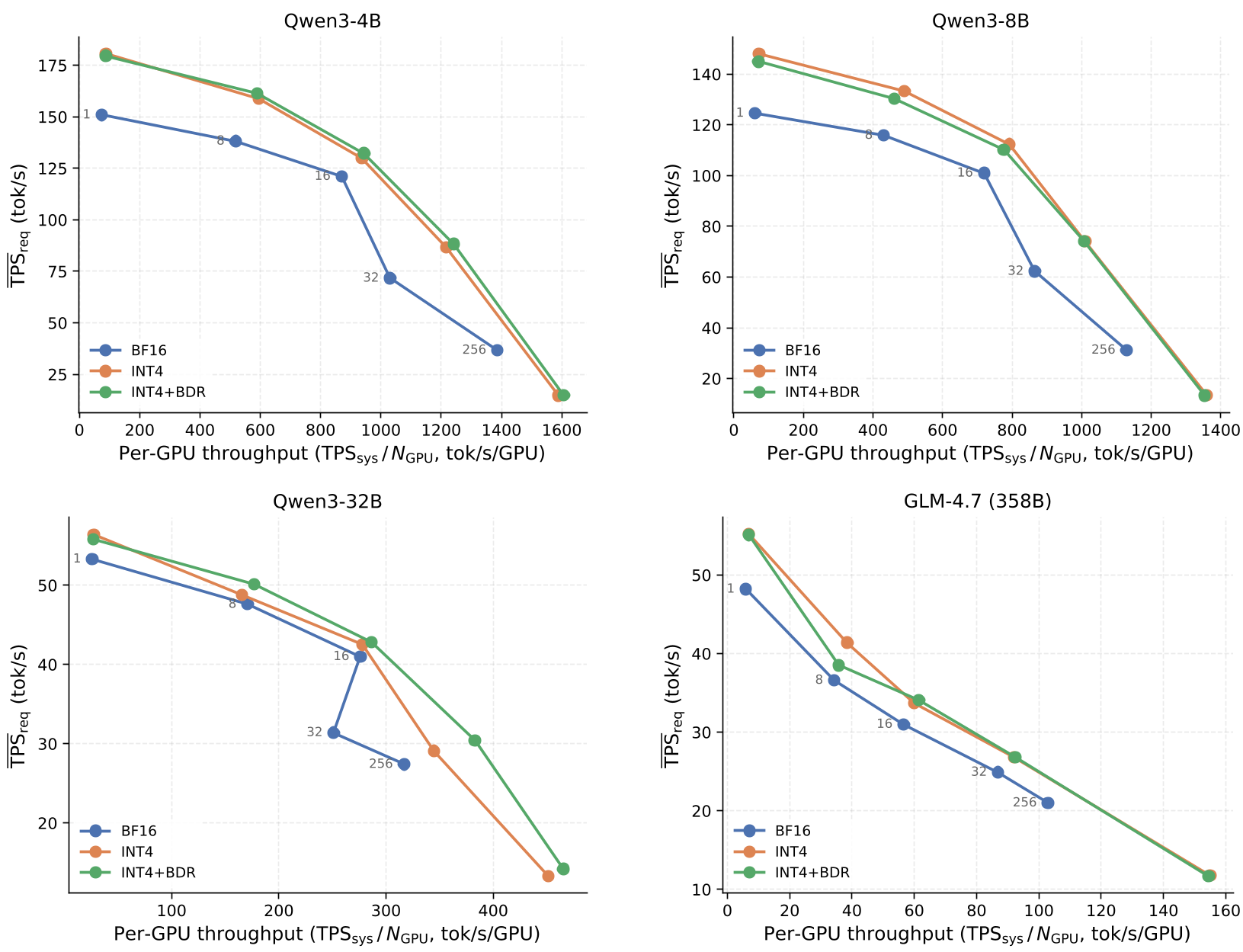 上图显示,在 Qwen3-4B/8B/32B 及 GLM-4.7 上,INT4+BDR (绿色曲线) 在不同请求速率下均能提供与朴素 INT4 相近的超高吞吐,远超 BF16 基线。
上图显示,在 Qwen3-4B/8B/32B 及 GLM-4.7 上,INT4+BDR (绿色曲线) 在不同请求速率下均能提供与朴素 INT4 相近的超高吞吐,远超 BF16 基线。
消融研究:
- 应用旋转于 Key 缓存比同时旋转 KV 更划算。
- 块大小(Block size)设为 128 时,精度和算子效率达成了最佳平衡。
5. 深度洞察:给未来研究的启示
SAW-INT4 的成功给 LLM 推理优化提供了两个重要启示:
- 局部优化的陷阱:单纯追求 Kernel 微观带宽(Micro-benchmark)的极致没有意义。朴素 INT4 单算子更快,但因为它精度烂掉导致无法使用,所以必须接受旋转带来的微小开销。
- 拒绝过度工程:实验显示,更复杂的 KMeans 向量量化或 Hessian 感知量化在 BDR 面前边际收益极低。这提醒研究者,在已经平衡了特征分布后,增加量化器的复杂度往往得不偿失。
局限性:虽然目前在 4-bit 表现卓越,但当比特数进一步下探至 2-bit 时,BDR 是否还能维持精度仍需结合混合精度技术进一步探索。
总结 (Takeaway)
SAW-INT4 是一款为生产环境量身定做的 KV-Cache 压缩利器。它告诉我们,最高级的算法往往是简单的、能够与现有系统架构完美“合体”的方案。