The paper introduces Cascade, a specialized Convolutional Neural Network (CNN) decoder for Quantum Error Correction (QEC). It leverages the geometric symmetry of Surface and Bivariate Bicycle (BB) codes to achieve near-optimal decoding accuracy and state-of-the-art throughput, particularly for high-rate Quantum Low-Density Parity-Check (qLDPC) codes.
Executive Summary
TL;DR: Researchers from Harvard have unveiled Cascade, a neural decoder that finally bridges the gap between accuracy and speed in Quantum Error Correction (QEC). By treating the QEC syndrome as a geometric data structure and applying specialized convolutions, Cascade uncovers a "waterfall" regime of error suppression, reaching logical error rates of with a to throughput improvement over previous methods.
Background Positioning: This is a seminal work in the "Neural Decoder" era of QEC. It moves beyond simple MLP/GNN approaches to a rigorous, geometric inductive bias framework. It proves that high-rate quantum LDPC codes (the current darlings of QEC theory) are finally practical for real-world hardware.
The "Decoding Gap" and the Waterfall Intuition
The standard way we measure "good" codes is through Code Distance (). Theoretically, a code should suppress errors as . However, there is a catch: this formula only considers the worst-case (minimum weight) errors.
In reality, especially for the new generation of Quantum LDPC codes, there are relatively few minimum-weight errors but a vast number of slightly higher-weight errors.
- The Problem: Standard decoders like Belief Propagation (BP) get "trapped" by these complex error patterns.
- The Result: We miss the "Waterfall" — a regime where errors drop much faster than the distance-limited slope suggests.
Cascade's core insight is that by increasing the expressive capacity of the decoder through deep CNNs, we can correctly classify these high-weight patterns, unlocking a steeper error suppression curve (the Waterfall) before eventually hitting the distance-limited floor.
Methodology: Geometry as a First-Class Citizen
Cascade isn't just a generic "AI" model; it is a Structure-Aware architecture. It treats the spatiotemporal syndrome (measurements over time) as a lattice and applies three design principles:
- Locality: Errors are local; information is processed in layers to reach a global "topological" conclusion.
- Translation Equivariance: A shift in physical errors results in a proportional shift in the syndrome. Cascade uses shared weights across the lattice to respect this.
- Anisotropy: Information in the temporal direction (measurement noise) is treated differently than spatial directions (gate noise).
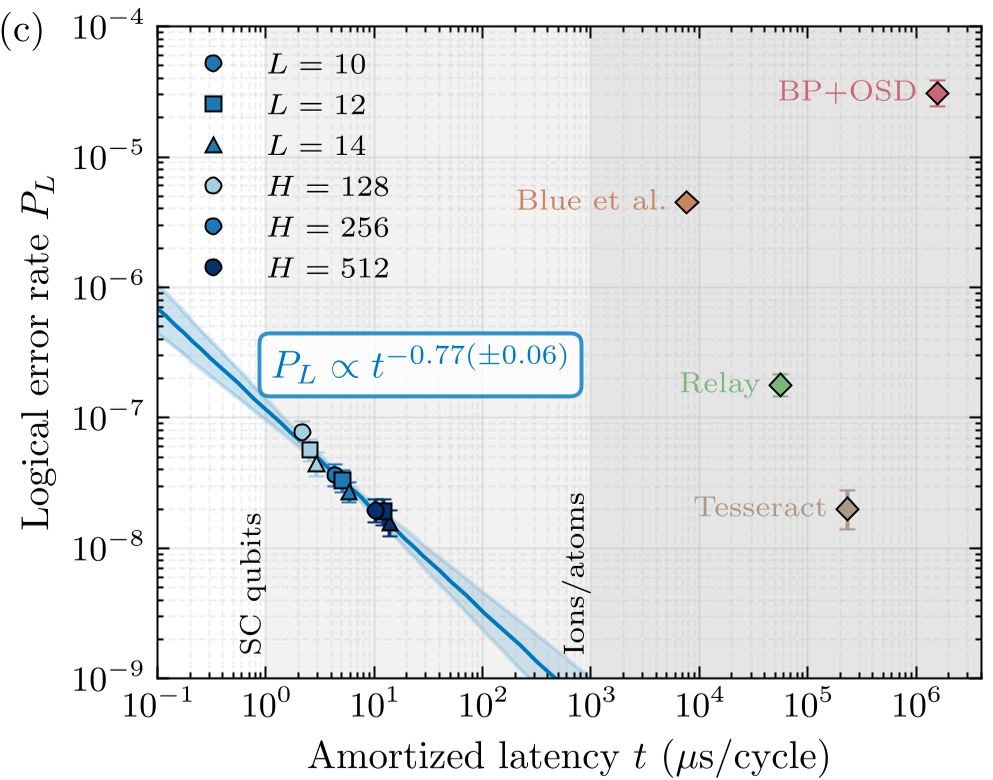 Figure 1: The Cascade pipeline. Syndromes are embedded, processed through convolutional layers respecting code geometry (3D for surface, toroidal for BB), and pooled to predict logical observables.
Figure 1: The Cascade pipeline. Syndromes are embedded, processed through convolutional layers respecting code geometry (3D for surface, toroidal for BB), and pooled to predict logical observables.
Experiments: Crushing the Baselines
The researchers tested Cascade against the "Gold Standard" decoders: BP+OSD (slow but accurate) and MWPM (the surface code standard).
1. The Waterfall Discovery
On the [[144, 12, 12]] Gross code, Cascade revealed a power-law contribution of in the waterfall regime, whereas BP+OSD was stuck at . This effectively makes a "small" code perform like a much larger one.
2. Efficiency and Latency
One of Cascade's most impressive feats is its Hardware-Friendliness:
- Throughput: orders of magnitude higher than CPU-based decoders.
- Latency: Single-shot latency of on an H100/H200 GPU. While still slightly above the requirement for superconducting qubits, it is perfectly suited for neutral-atom and ion-trap architectures which operate on millisecond timescales.
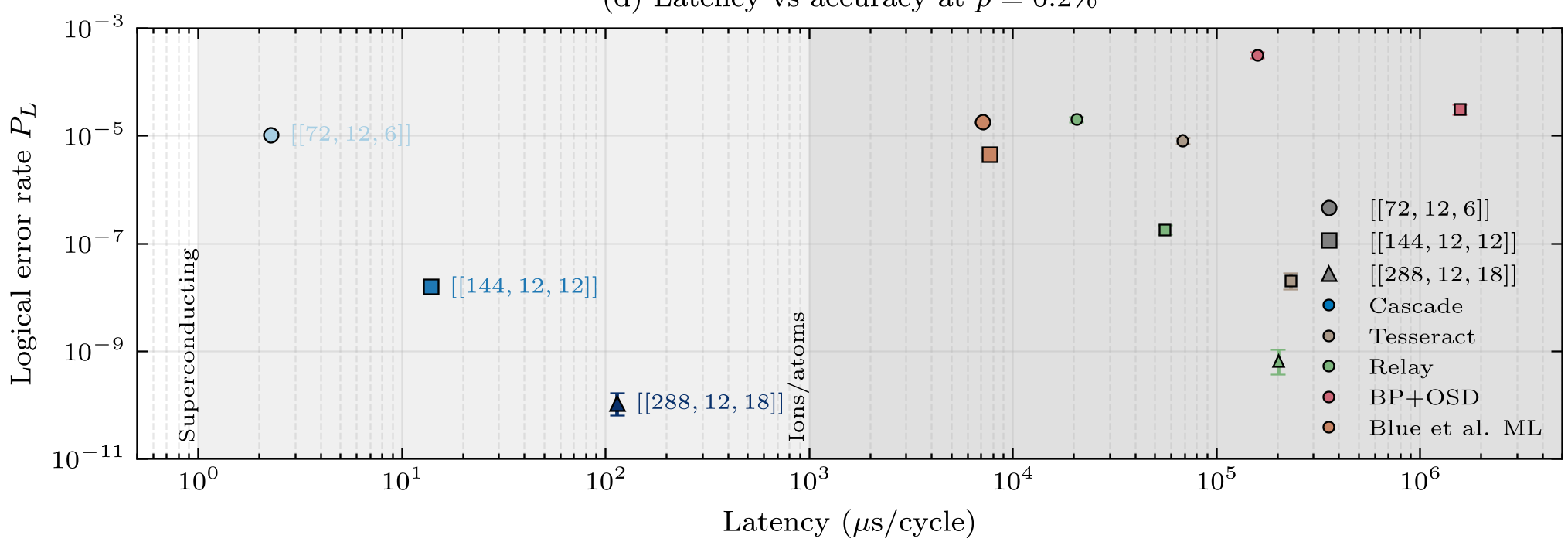 Figure 2: Performance on Bivariate Bicycle (BB) codes. Cascade (blue) consistently stays orders of magnitude below prior decoders across different code sizes.
Figure 2: Performance on Bivariate Bicycle (BB) codes. Cascade (blue) consistently stays orders of magnitude below prior decoders across different code sizes.
Critical Insight: Calibrated Confidence
Beyond just decoding, Cascade provides well-calibrated confidence estimates. In a "Repeat-Until-Success" protocol (like Magic State Distillation), if the decoder says "I'm only 60% sure about this correction," the system can choose to discard that round. Cascade's confidence is so accurate that it can reduce the "retry" overhead by 20x compared to existing post-selection methods.
Conclusion & Future Outlook
Takeaway: Cascade proves that the bottleneck for QEC isn't just the physical hardware—it's the classical algorithm's ability to "see" the code's full potential. By replacing rigid algorithms with learned, geometric convolutions, we can achieve a 40% reduction in physical qubit counts.
Limitations: Currently, training requires significant compute (though only done once per code). For the fastest quantum systems (superconducting), we still need the "unrolled" FPGA/ASIC implementation of these CNNs to hit the sub-microsecond mark.
As we move toward the logical error rate regime required for RSA-breaking or drug discovery, Cascade suggests the path forward is Decoder-Hardware Co-design, where the "brain" of the quantum computer is as specialized as its "qubits."