字节跳动发布了 Seed1.8 模型,这是一个旨在实现“通用真实世界智能体(Generalized Real-World Agency)”的基础模型。该模型在保持顶尖 LLM 和 VLM 能力的同时,重点增强了多轮交互、工具调用(如视频回放工具 VideoCut)及 GUI 操作能力,不仅在常规基准测试中表现卓越,更在金融、法律、科研等高经济价值领域展现了极强的实用性。
TL;DR
字节跳动近日发布的 Seed1.8 模型不仅是一个强大的多模态底座,更是对“通用智能体(General Agency)”的一次深度实践。它通过统一感知、推理与工具调用,在 GAIA、OSWorld 等多个智能体榜单上刷写了 SOTA。最令人关注的是其灵活的 Thinking Modes(思维模式)和针对长视频理解的 VideoCut 机制,这标志着 AI 从“只会说话”进化到了“能看、会算、懂执行”的新阶段。
痛点深挖:为什么 SOTA 无法代表“好用”?
在学术坐标系中,我们习惯用 MMLU 或 GSM8K 来衡量模型,但在真实世界里,一个合格的智能体需要面对:
- 交互的连贯性:能否在多轮搜索、代码修改和反馈中坚持目标?
- 感知的细粒度:当 API 不可用时,能否像人一样直接从 GUI 截图或高帧率视频中提取线索?
- 成本的边界感:对于简单的查询,能否低成本秒回?对于复杂的科研项目,能否通过增加“思考时间”来换取深度?
Seed1.8 的出现,正是为了弥合这些“学术表现”与“经济价值”之间的鸿沟。
核心机制:三位一体的 Agency 架构
1. 动态思维模式 (Configurable Thinking Modes)
Seed1.8 支持从 no_think 到 think-high 四种模式。这种设计允许用户根据任务难度灵活分配推理算力。实验表明,Seed1.8 在文本与多模态推理任务上展现出比前代更陡峭的 Scaling Law 曲线,在 MathVision 等极高难度任务中,通过增加推理步数获得了近 10% 的绝对提升。
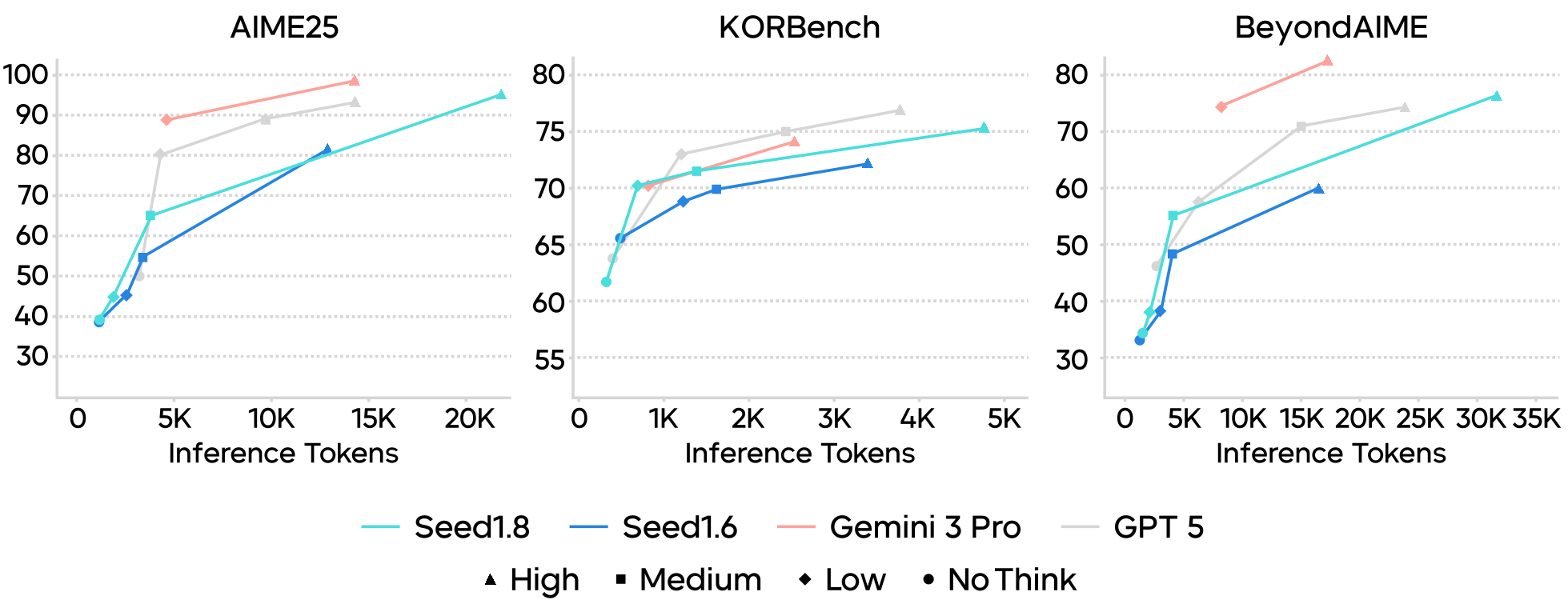 图 1:Seed1.8 在不同推理预算下的表现,显著优于 GPT-5.1 和 Gemini 3 Pro。
图 1:Seed1.8 在不同推理预算下的表现,显著优于 GPT-5.1 和 Gemini 3 Pro。
2. 视频感知的“慢动作”回放 (Video Tool-Use)
面对超长视频,模型通常容易丢失细节。Seed1.8 集成了名为 VideoCut 的工具,模型可以根据初步推理结果,主动调节片段的起始点和 FPS(高达 5 fps),实现对关键动态(如物理实验、城市导航)的细粒度复查。
 表 1:在 ZeroVideo 挑战集上,使用视频工具后 Seed1.8 的表现从 6.9 分飙升至 18.8 分。
表 1:在 ZeroVideo 挑战集上,使用视频工具后 Seed1.8 的表现从 6.9 分飙升至 18.8 分。
3. 原生 GUI 交互 (GUI Grounding)
不同于传统的基于文本解析的网页代理,Seed1.8 展现了极强的视觉定位于动作生成能力。它在 OSWorld(计算机使用)和 AndroidWorld(手机使用)中表现稳健,能够直接从屏幕截图中识别按钮、滑动条并执行 100 步以上的长链条任务。
战绩分析:当 AI 走进实验室与办公室
Seed1.8 的核心野心在于内核的**“可变现价值”**:
- 金融领域:在 FinSearchComp 中,它能从非结构化报告中提取名义与实际 GDP,并进行多步复杂计算。
- 科研领域:在 AInstein-SWE-Bench 中,它展现了在 Docker 容器中修复复杂数值相对论 C++ 代码的能力。
- 法律与教育:通过集成的 SOP 流程,Seed1.8 在处理合同合规审查和 K-12 物理受力分析(LaTeX 格式)时表现出极高的专业度。
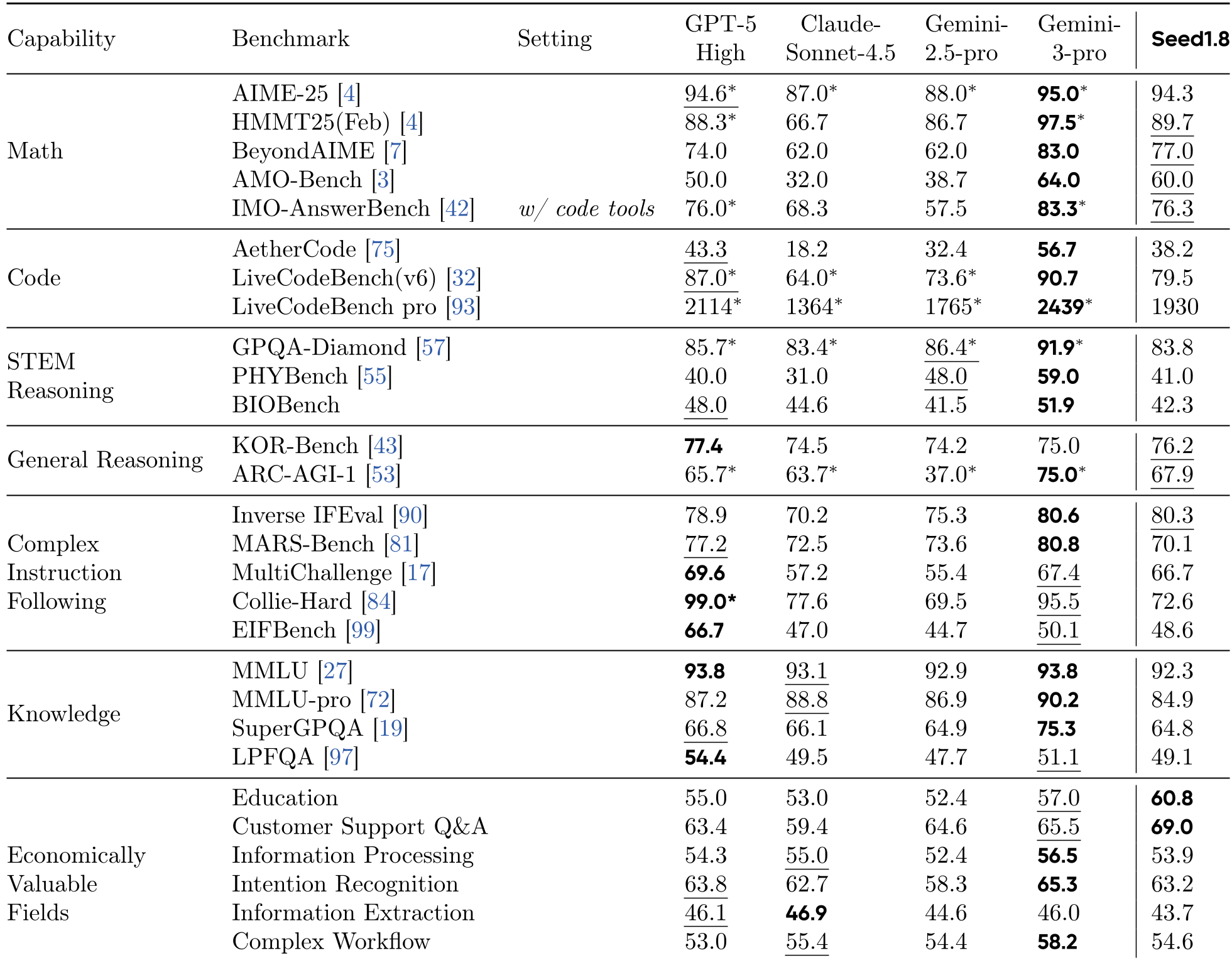 图 2:Seed1.8 在逻辑推理、代码及经济高产领域与闭源顶流模型的对比。
图 2:Seed1.8 在逻辑推理、代码及经济高产领域与闭源顶流模型的对比。
局限性与洞察
尽管在感知和搜索上达到了巅峰,作者坦言 Seed1.8 在某些学科领域(如 VideoMMMU 等专业知识库)相比 Gemini 3 Pro 仍有追赶空间。此外,对于高度复杂的运动感知,虽然比起前人有巨幅提升,但与人类 95% 以上的基准相比,AI 仍显得有些“近视”。
总结
Seed1.8 不再仅仅是一个回答问题的“聊天框”,它更像是一个配备了眼睛、双手和决策权的大脑。它的推出预示着未来的智能体将更加注重 Token Efficiency(如 32K 视频 Token 达到他人 80K 的精度)与 Visual Proactivity(视觉主动性)。对于开发者而言,如何在实际应用中利用好 Seed1.8 的四档思维开关,将成为落地业务的关键。