本文针对多模态专家混合模型 (MoE) 中出现的“视而不见 (Seeing but Not Thinking)”现象进行了深入研究,提出了路由分心 (Routing Distraction) 假设。通过路由引导干预方法(Routing-Guided Intervention),在 Qwen3-VL 和 Llama4 等模型上实现了复杂视觉推理任务最高 3.17% 的性能提升。
TL;DR
多模态混合专家模型(MoE)目前已成为 scaling 大模型的主流,但它们常陷入一种诡异的困境:看清了文字,却做不对题。本文揭示了其背后的物理直觉——路由分心 (Routing Distraction)。作者发现视觉输入会“带偏”模型的注意力,使其在中间层无法有效调用推理专家。通过一种简单的推理时路由干预,模型在不重新训练的情况下,复杂推理能力提升了高达 3.17%。
痛点深挖:模型为何“看见”了却没“思考”?
作者观察到一个有趣的现象(如图1):当给模型一张含有数学题的图片时,模型 OCR 识别出的数字完全正确,但逻辑推导却一塌糊涂;然而,一旦把同样的文字直接喂给模型,它就能秒出正确答案。
这种**“视而不见 (Seeing but Not Thinking)”**的现象说明了:
- 不是感知(Perception)的问题:模型能读懂图。
- 不是能力(Capability)的问题:模型本身具备解题逻辑。
- 真相是“分配”方案错了:在处理图像时,MoE 的路由机制(Router)未能把任务分发给最擅长推理的那批专家。
核心洞见:专家分布的层级隔离
为了验证这一直觉,作者对专家进行了分类统计:
- 视觉专家 (Visual Experts):集中在浅层(负责编码)和深层(负责模态输出)。
- 领域推理专家 (Domain Experts):密集分布在模型的中间层 (Middle Layers)。
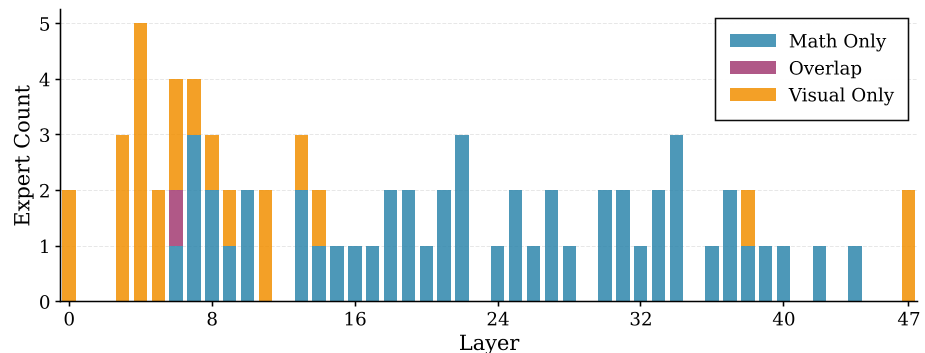
通过 JSD(Jensen-Shannon Divergence)散度分析,作者证实:在这些关键的中间层,视觉输入引发了剧烈的路由发散(Routing Divergence)。换句话说,视觉信号就像一个“噪音源”,让模型在处理复杂逻辑时,跑到了专门处理视觉特征的通道里,而忽略了真正的“大脑”。
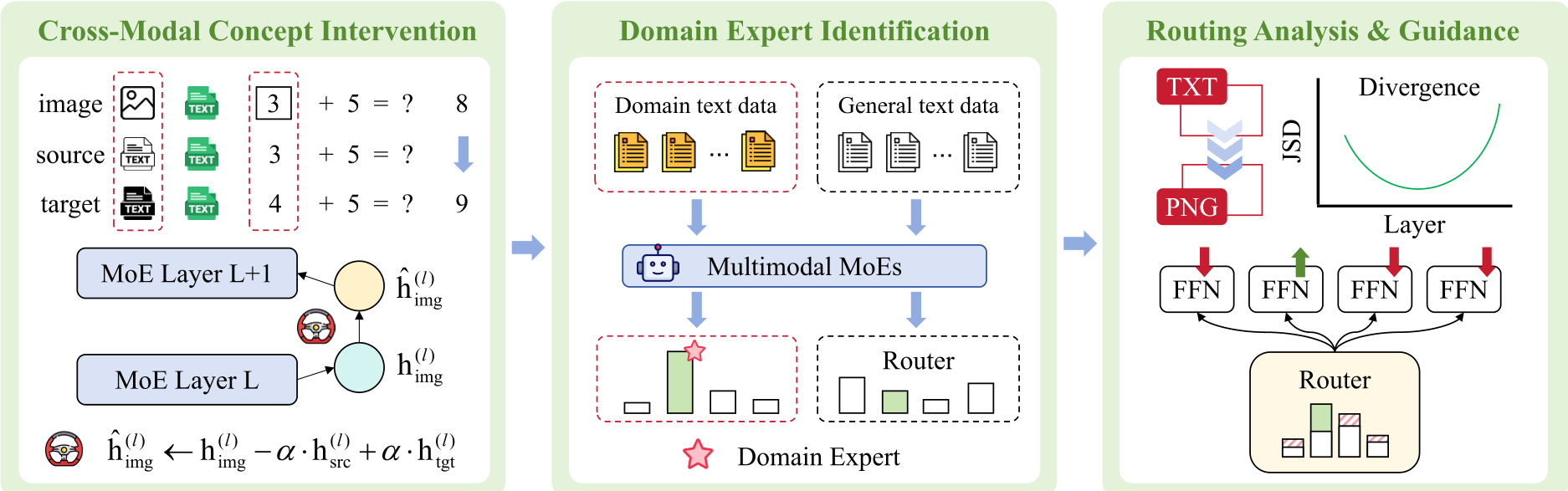
架构解析:如何把模型“拽回”正轨?
既然问题出在路由偏离,最直接的手段就是路由引导干预 (Routing-Guided Intervention)。
1. 寻找“大脑”:领域专家识别
作者先用 20 个纯文本样本(如 GSM8K)激活模型,观察哪些专家在处理这些逻辑题时最活跃,将其标记为 E_domain。
2. 推理时干预 (Soft Intervention)
在推理图像时,作者人为地微调了这些领域专家的路由权重。 这里的核心逻辑是:保留路由的灵活性,但给推理专家一个“拉力”。实验证明,这种“软干预”策略远比直接强行指定专家的“硬干预”有效,因为它平衡了视觉特征提取与逻辑推理的权重。
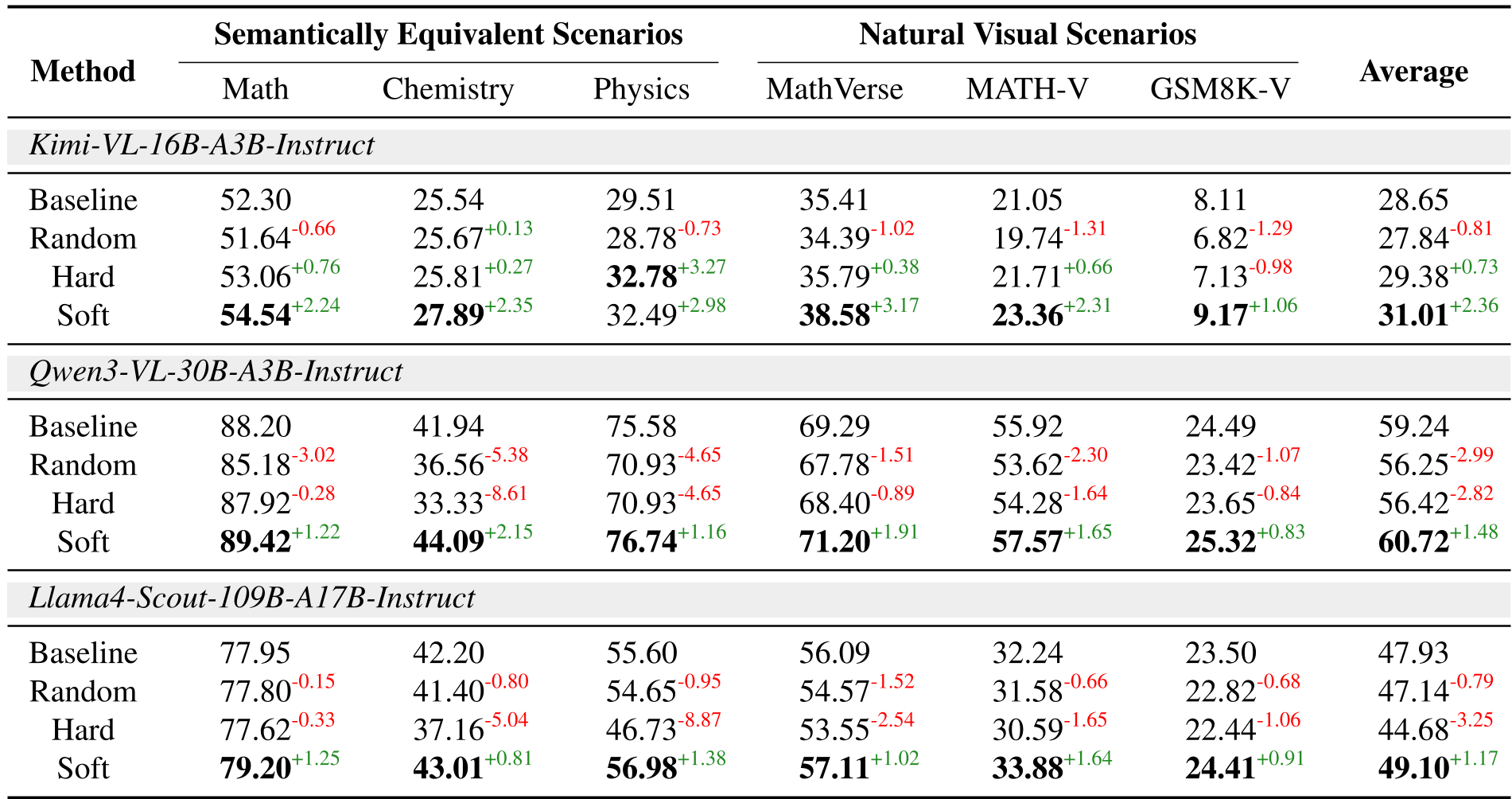
实验战绩
研究团队在 Qwen3-VL-30B, Kimi-VL-16B 和 Llama4-Scout-109B 三大前沿模型上进行了验证。
- 复杂视觉推理 (MathVerse):Kimi-VL 提升了 3.17%,Qwen3-VL 提升了 1.91%。
- 鲁棒性验证:即使用于识别专家的文本参考并不完全等于图片内容(信息不完整),干预依然有效。这证明了模型识别出的是**“认知功能模块”**,而非简单的记忆路径。
深度洞察与总结
这项工作的真正价值在于:它打破了“多模态性能差是因为模态对齐不好”的固有认知。
Takeaways:
- 语义中枢假说成立:MoE 模型在中间层已经实现了跨模态语义共享,真正的瓶颈在于路由策略的鲁棒性。
- 计算资源分配不均:视觉信号在当前架构中具有过高的“路由干扰权重”,未来的模型设计应考虑如何通过训练手段实现“路由去噪”。
局限性分析: 虽然这种方法在推理端非常有效,但它仍属于“事后补救”。它需要针对不同任务预先构建参考文本。未来的方向应该是如何将这种“引导”内化到模型的预训练训练目标中,让模型在看到图片的一瞬间,就能自发地激活其最深层的推理潜力。
本文基于论文《Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts》整理。