SegviGen is a unified multi-task framework that repurposes pretrained 3D generative models (specifically TRELLIS/SLAT architectures) for high-fidelity 3D part segmentation. By reformulating segmentation as a conditional colorization task within a structured 3D latent space, it achieves SOTA results in interactive, full, and 2D-guided segmentation tasks.
TL;DR
SegviGen introduces a paradigm shift in 3D part segmentation by "repurposing" large-scale 3D generative models. Instead of training a segmenter from scratch or lifting 2D masks into 3D space, SegviGen treats segmentation as a colorization task. It achieves a 40% boost in interactive accuracy and 15% in full segmentation while utilizing a staggering 0.32% of the typical training data.
Background: The Native 3D vs. 2D Lifting Dilemma
In the 3D world, segmentation has long been stuck between two worlds:
- 2D-to-3D Lifting: Projecting Segment-Anything (SAM) results onto 3D shapes. This is flexible but produces "fuzzy" boundaries and suffers from "stitching" errors between views.
- Native 3D Training: Training models like P3-SAM on point clouds. This is spatially consistent but requires millions of manually annotated shape-part pairs—a bottleneck for the industry.
The Insight: 3D generative models (trained on unlabelled 3D assets) must understand parts (wheels, legs, handles) to synthesize realistic textures and geometry. SegviGen unlocks this "hidden" structural knowledge.
Methodology: Segmentation as Part-wise Colorization
SegviGen's core innovation is formulating the segmentation problem to match the input/output space of generative models.
1. The Structured Latent Space
It builds upon the Omni-Voxel (O-Voxel) representation. Each asset is a set of sparse voxels containing geometry and texture features. A Sparse Compression VAE (SC-VAE) maps these to a compact latent .
2. Multi-Task Conditioning
The model is a Diffusion Transformer (DiT) using Flow Matching. It can handle three input modes:
- Interactive: User clicks are encoded as "Point Tokens" via RoPE (Rotary Positional Embeddings).
- Full Segmentation: The model generates a random color palette to distinguish parts.
- 2D-Guided: A 2D segmentation map is injected via cross-attention, allowing users to "paint" 3D parts from a 2D view.
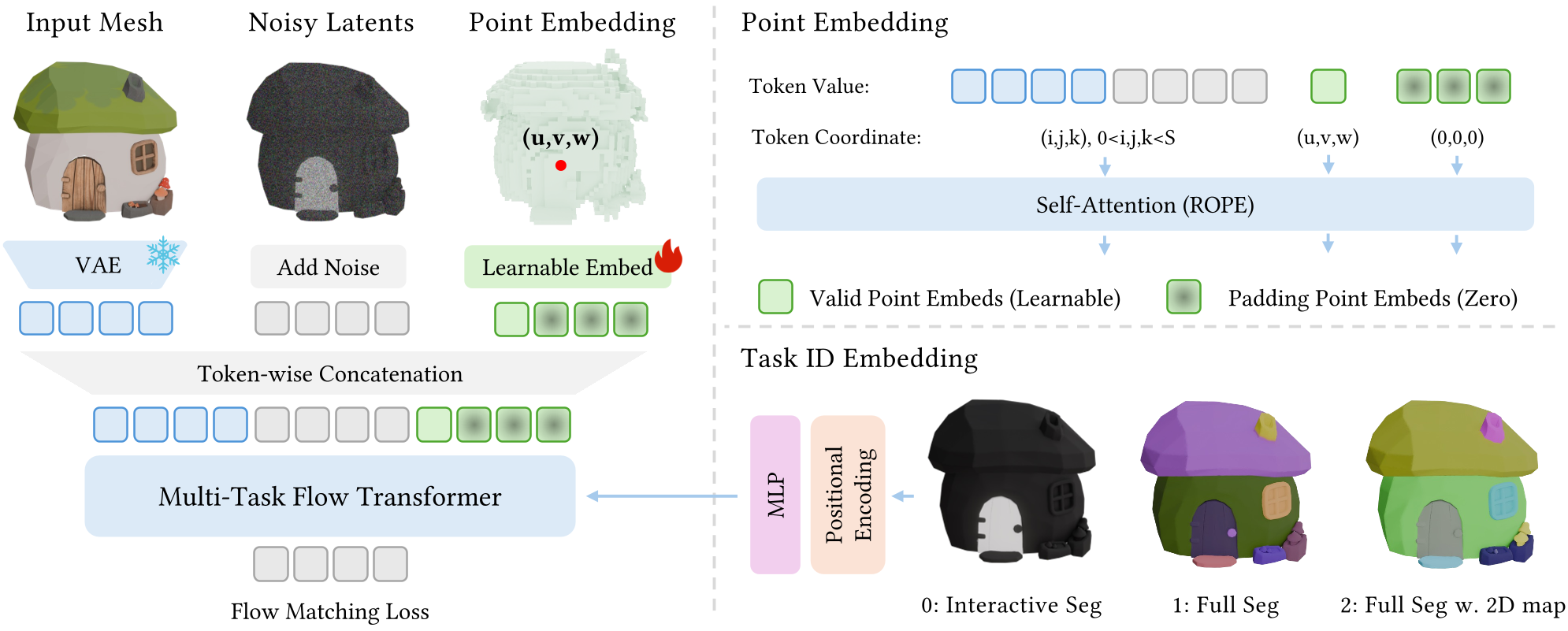 Figure 1: The unified pipeline where geometry latents and noisy color latents are fused with task embeddings to predict part boundaries.
Figure 1: The unified pipeline where geometry latents and noisy color latents are fused with task embeddings to predict part boundaries.
Experiments: Doing More with Less
The most striking result is the Data Efficiency. SegviGen was trained on the PartVerse dataset (12k objects), whereas previous SOTA models require massive scale.
Interactive Accuracy
In the "1-click" (IoU@1) scenario, SegviGen hits 54.86% IoU on PartNeXT, compared to just ~35% for P3-SAM. This proves the generative prior already "knows" where a part ends even before the user provides a second click.
| Method | IoU@1 (PartNeXT) | Data Used | | :--- | :--- | :--- | | P3-SAM | 35.61 | 100% | | SegviGen | 54.86 | 0.32% |
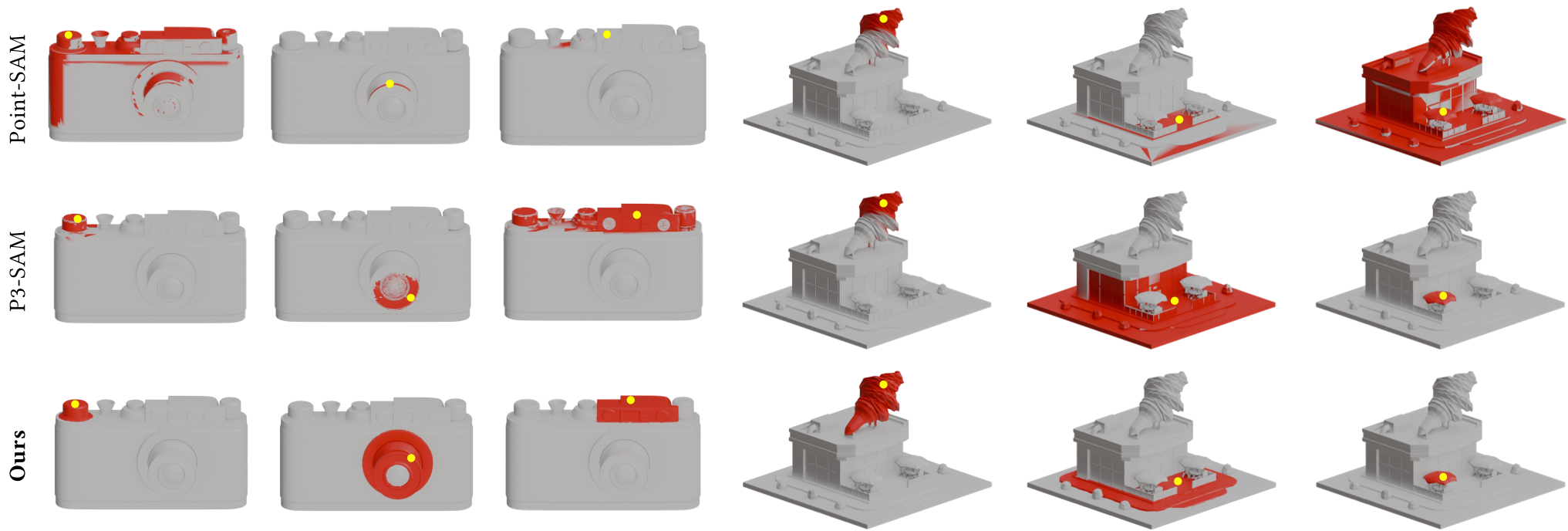 Figure 2: Visual comparison of interactive segmentation. Note the sharper, more semantically accurate boundaries in SegviGen compared to Point-SAM.
Figure 2: Visual comparison of interactive segmentation. Note the sharper, more semantically accurate boundaries in SegviGen compared to Point-SAM.
Downstream Utility
Beyond benchmarks, SegviGen serves as a backbone for 3D Editing. By providing precise masks, it allows models like VoxHammer to perform local edits (e.g., changing the legs of a chair) while preserving the rest of the geometry.
 Figure 3: SegviGen enabling local 3D mesh editing through precise part mask generation.
Figure 3: SegviGen enabling local 3D mesh editing through precise part mask generation.
Critical Insight & Conclusion
Why does "Colorization" work for segmentation? In generative modeling, color follows structure. To color a "car door" correctly, the model must understand the manifold of the door separate from the window. SegviGen essentially "hacks" this learned manifold to output part IDs instead of RGB values.
Limitations: The model is bound by the quality of the base 3D generative model. If the generator cannot reconstruct fine-grained geometry (like tiny screws or thin wires), SegviGen will likely fail to segment them.
Future Outlook: SegviGen proves that the next generation of 3D perception models won't be trained on labels alone—they will be fine-tuned versions of world-scale 3D generators.