本文探讨了自蒸馏(Self-Distillation)对大语言模型(LLMs)推理能力的影响,提出了 Epistemic Verbalization(认识论言语化) 缺失是导致性能下降的关键因素。研究发现,虽然自蒸馏在某些领域能缩短推理链并提升效率,但在数学推理中往往会导致模型过度自信,进而损害 OOD(分布外)泛化表现。
TL;DR
自蒸馏(Self-Distillation)通常被视为一种让模型“更聪明、更高效”的炼金术。然而,微软亚洲研究院(MSRA)等机构的最新研究揭示了一个令人警惕的现象:在数学推理领域,自蒸馏虽然让模型学会了“快准狠”地给出答案,却因剥夺了模型表达“犹豫”(Epistemic Verbalization)的能力,导致其在面对未见过的问题时泛化能力剧降(最高跌幅达 40%)。
核心直觉:上帝视角带来的“盲目自信”
在自蒸馏框架中,Teacher 模型通常可以访问标准答案(GT),从而产生极其简洁且自信的推理链。Student 模型被要求模仿这种“上帝视角”下的推理风格。
作者的深刻洞察是:推理过程中的 "Wait", "Hmm", "Actually" 等看似废话的词汇(Epistemic Tokens),实际上是模型在处理不确定性、尝试不同假设、进行自我纠错的物理体现。当 Student 模仿 Teacher 这种不需要纠错的简洁风格时,它在推理阶段就失去了“思考”的中间支架。
实验架构:信息丰富度与性能的对决
作者设计了一套严密的实验体系,通过改变 Teacher 的 Conditioning Context(上下文约束)来控制信息量,观察对 Student 的影响。
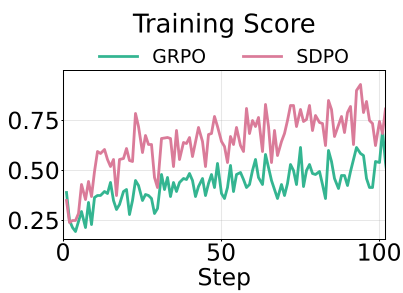 (图 1:在化学领域自蒸馏表现良好,而在数学领域,其性能随着推理长度的缩短而发生崩塌)
(图 1:在化学领域自蒸馏表现良好,而在数学领域,其性能随着推理长度的缩短而发生崩塌)
关键发现:
- 信息单调性:Teacher 获得的信息越丰富(如包含详细的
<think>过程),产生的推理轨迹就越少出现不确定性标记。 - SFT 的假象:即便只在完全正确的推理路径上进行 SFT,如果这些路径被过度压缩,模型在 OOD 测试中的表现依然会大幅下滑。
为什么数学任务更特殊?
研究揭示了 任务覆盖度(Task Coverage) 的关键作用:
- 窄域任务(如化学实验):问题模式固定,模型通过自蒸馏学会了特定模式的捷径,简洁性代表了效率。
- 博大精深的数学:任务覆盖面广,泛化要求极高。在这种场景下,压缩推理路径等同于删除了处理复杂逻辑所需的“内存位”。
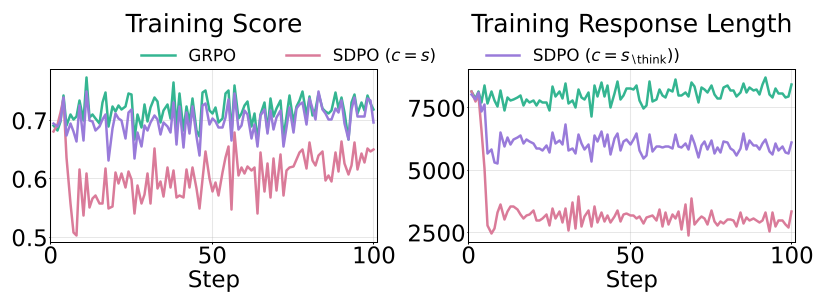 (图 2:DeepSeek-R1-Distill 和 Qwen3 的实验结果,显示自蒸馏 SDPO 后的准确率明显低于基线,而 GRPO 通过增加推理长度提升了性能)
(图 2:DeepSeek-R1-Distill 和 Qwen3 的实验结果,显示自蒸馏 SDPO 后的准确率明显低于基线,而 GRPO 通过增加推理长度提升了性能)
深度洞察:Epistemic Tokens 的价值
在表 1 中,作者展示了不同引导设置下的 Epistemic Token Count。当模型完全自主生成时,这些标记的数量最高。这说明:优秀的推理模型本质上是“多疑”的。它们需要这些标记作为锚点,来平衡不同的假设。
自蒸馏算法(如 SDPO)强制模型消除这些标记,本质上是在进行一种“有损压缩”。对于简单的任务,这种压缩去处的是冗余;对于复杂的 OOD 任务,这种压缩去除的是 Inductive Bias 的核心灵活性。
结论与启示
这项研究对当前的 LLM Post-training 具有重要的警示意义:
- 拒绝病态简洁:不要一味追求更短的 Reasoning Trace,简洁有时是泛化能力的杀手。
- 保护“犹豫”:在设计 Reward Function 时,应当奖励那些能体现模型自我修正逻辑的表达,而非仅仅奖励最终答案的正确性。
- Teacher 的局限:自蒸馏中的 Teacher 不应表现得像个“全知全能的先知”,由一个具备适度不确定性的 Teacher 引导出的 Student 可能更具鲁棒性。
局限性与未来展望
目前的研究主要集中在数学领域,未来的挑战在于如何在保持模型高效推理的同时,动态地调整其 Epistemic Verbalization 的密度。如何找到“冗余废话”与“认知必要步骤”之间的精确界限,将是下一代高性能推理模型的关键。