This paper presents a comprehensive technical overview of self-improving Large Language Models (LLMs), proposing a unified closed-loop framework called the "self-improvement lifecycle." It categorizes existing research into five core stages: Data Acquisition, Data Selection, Model Optimization (via the GRO framework), Inference Refinement, and Autonomous Evaluation, aiming to move beyond human-limited supervision toward autonomous scalability.
TL;DR
As we approach the limits of the "human-in-the-loop" paradigm, the next frontier for AI is Self-Improvement. This landmark technical overview from Stony Brook University formalizes the shift from human-annotated datasets to autonomous, closed-loop systems where LLMs acquire their own data, select the most informative signals, optimize their own parameters via a Generation-Reward-Optimization (GRO) framework, and refine their reasoning at inference time.
The Motivation: The "Human Ceiling"
The current AI trajectory faces a looming crisis: we are running out of high-quality human data. More importantly, if a model's performance is permanently capped by the quality of human feedback (RLHF), it can never truly become "super-intelligent." To solve this, researchers are building systems where the model acts as its own coach, student, and examiner.
The Unified Architecture of Self-Improvement
The paper organizes the chaotic landscape of self-improvement into five tightly coupled modules.
1. Data Acquisition: Synthesizing the Future
Instead of scraping the web, models are now:
- Environment Interaction: Using code executors and web browsers to "earn" experience through trial and error.
- Synthetic Generation: Leveraging "textbook-quality" synthetic data (like the Phi series) to inject reasoning-intensive signals that broad web crawls lack.
2. The GRO Framework: The Engine of Optimization
The "how" of self-improvement is distilled into the Generation–Reward–Optimization (GRO) cycle:
- Generation: The model explores diverse reasoning paths.
- Reward: Logic is verified via external compilers (Code) or internal consistency (Majority Voting).
- Optimization: The policy is updated using Direct Preference Optimization (DPO) or Group Relative Policy Optimization (GRPO) to reinforce "correct" self-thought.
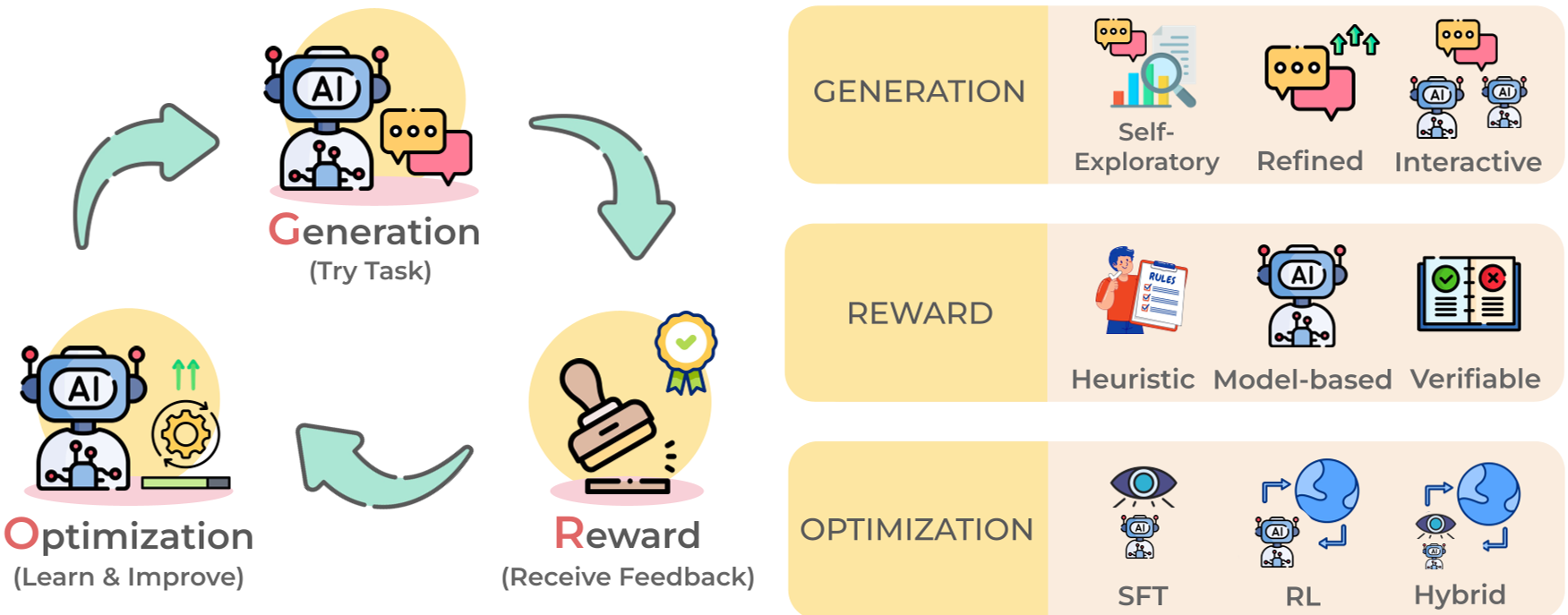 Figure: The GRO loop illustrates how a model iteratively "climbs" its own quality gradient.
Figure: The GRO loop illustrates how a model iteratively "climbs" its own quality gradient.
3. Inference Refinement: Thinking Before Speaking
A critical insight here is that we can scale Test-Time Compute instead of just model parameters. Approaches like Tree-of-Thought and Self-Refine allow a model to backtrack and correct its mistakes mid-stream, essentially performing a local optimization for a specific query.
4. Autonomous Evaluation: The Evolving Judge
Static benchmarks (like MMLU) are easily "leaked" into training sets. The survey highlights Dynamic Benchmarking—systems that generate fresh, timestamped questions (e.g., LiveCodeBench) to ensure the model is actually reasoning, not just memorizing.
Experimental Evidence & SOTA Performance
The paper highlights a paradigm shift:
- DataComp-LM (DCLM): Proved that model-based data selection is the single most important factor in training, outperforming standard heuristic filters.
- Self-Play Fine-Tuning (SPIN): Demonstrated that a model can improve by competing against its previous version, distinguish self-generated responses from ground truth, and progressively refine its policy.
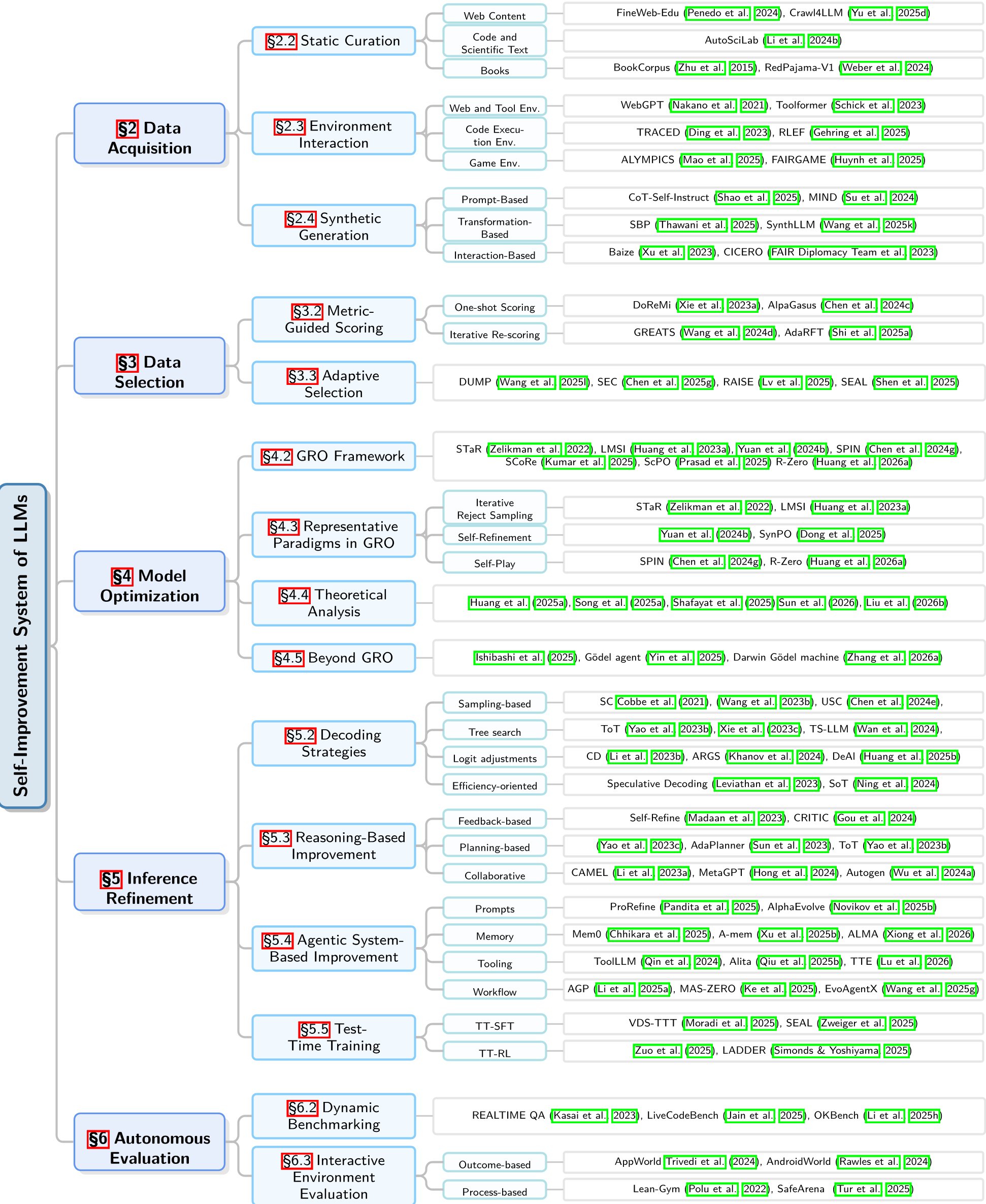 Figure: Categorizing the various methodologies from data curation to agentic systems.
Figure: Categorizing the various methodologies from data curation to agentic systems.
The "Data Autophagy" Challenge: A Warning
Despite the excitement, the authors warn of Data Autophagy. If a model trains too much on its own low-entropy synthetic data without "fresh" external signals, it suffers from Model Collapse—a degenerative process where it loses the diversity of the original data distribution and begins to produce repetitive "mush."
Conclusion & Future Outlook
The transition from a "Passive Model" to an "Active Agentic System" is the ultimate takeaway. Future architectures like the Darwin Gödel Machine—modular agents that can recursively modify their own code—suggest that the boundary between training and inference is dissolving.
The goal is no longer just a "smarter" model, but an autonomous system capable of sovereign development: an AI that can learn, verify, and grow without needing a human to hold its hand.