本文提出了 ShotStream,这是一种全新的因果(Causal)多镜头视频生成架构,专门用于交互式叙事。它将多镜头合成任务重新定义为受历史上下文约束的自回归“下一镜头”生成,在单个 GPU 上实现了 16 FPS 的实时生成速度。
TL;DR
传统的视频生成模型往往像是一个“黑盒”,你输入一串 Prompt,然后漫长地等待它吐出结果。ShotStream 改变了游戏规则。它通过将视频生成重构为因果自回归任务,配合创新的双缓存(Dual-Cache)机构和两阶段蒸馏策略,实现了在单个 GPU 上以 16 FPS 的速度生成具有高度逻辑一致性的多镜头视频。这意味着用户可以像“导演”一样,在视频生成的过程中随时输入新的指令,实时引导故事走向。
背景定位:从“一次性生成”到“流式交互”
目前的视频生成领域正从单镜头向长篇叙事演进。然而,现有的 SOTA 模型(如 HoloCine、LCT)大多基于双向架构,这意味着它们必须提前感知全局信息,导致生成延迟极高且无法中途干预。ShotStream 的核心价值在于它在生成效率与交互自由度之间找到了近乎完美的平衡点,属于长视频生成领域中“实时化”与“架构因果化”的先锋工作。
痛点深挖:为什么长视频生成这么难?
- 计算爆炸:双向注意力机制的复杂度是序列长度的平方。对于包含数百帧的多镜头视频,内存占用和计算延迟会迅速失控。
- 交互缺失:用户无法在生成过程中根据已有的视觉反馈调整下一镜头的剧情。
- 自回归的诅咒:如果采用自回归生成(Shot-by-Shot),微小的噪声误差会随着镜头推进不断累积,导致视频到后期完全“崩坏”(Exposure Bias)。
核心方法论:ShotStream 的三大法宝
1. 架构的华丽转身:从双向到因果
作者首先训练了一个双向的“下一镜头”教师模型,利用基于动态采样(Dynamic Sampling)的稀疏帧作为历史上下文。随后,通过 DMD (Distribution Matching Distillation) 技术,将需要 50 步迭代的慢速模型蒸馏为仅需 4 步推理的因果学生模型。
2. 双缓存机制 (Dual-Cache Memory) 与 RoPE 指标
为了在流式生成中同时兼顾“当前镜头的流畅”和“历史镜头的统一”,ShotStream 设计了两个缓存:
- Global Context Cache: 存储历史镜头的稀疏关键帧,确保角色身份、场景背景不走样。
- Local Context Cache: 存储当前镜头已生成的帧,确保动作的连贯。
为了防止模型在查询时混淆这两个缓存,作者引入了 RoPE Discontinuity Indicator。通过在时间旋转编码中加入位移项 ,在镜头边界处制造逻辑上的“跳变”,让模型能清晰分辨“过去”与“现在”。
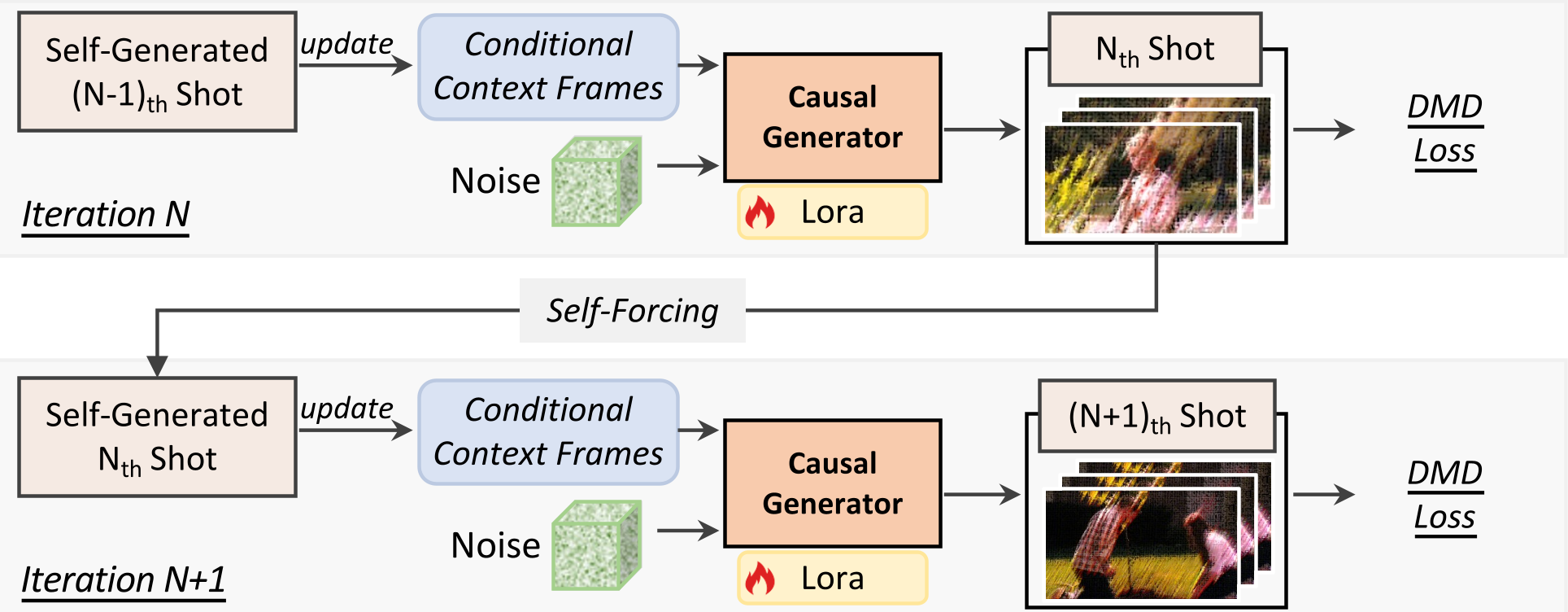 图 1:ShotStream 的因果架构与两阶段蒸馏流水线
图 1:ShotStream 的因果架构与两阶段蒸馏流水线
3. 两阶段蒸馏:对抗误差累积
- 阶段一 (Intra-shot):利用 Ground-truth 历史进行镜头内自强迫训练,建立基础生成能力。
- 阶段二 (Inter-shot):模拟真实的推理环境,让模型基于自己生成的(可能带误差的)历史镜头进行训练。这种“自产自销”的模式极大地弥合了训练与测试的 Gap。
实验与结果:快,而且稳
ShotStream 在实验中展现了令人惊叹的性能。在视觉质量不输于甚至超过双向模型的前提下,其推理效率实现了数量级的飞跃。
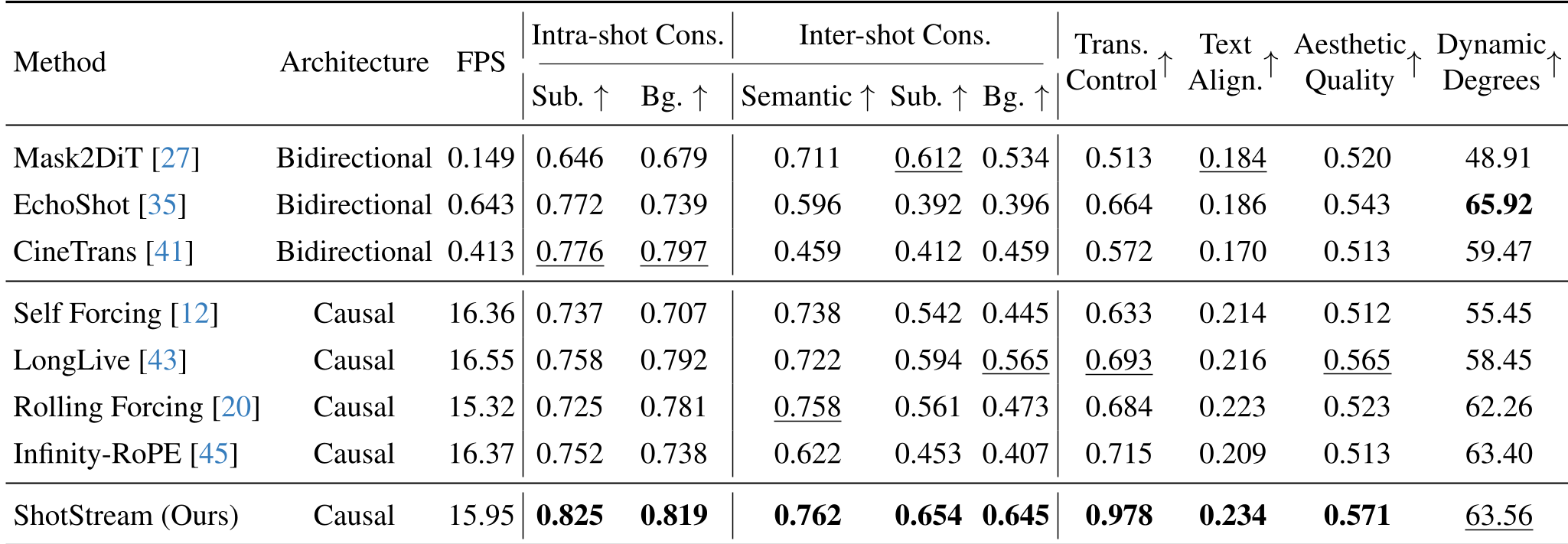 表 1:与主流模型的定量对比,注意其在 FPS 上的巨大优势
表 1:与主流模型的定量对比,注意其在 FPS 上的巨大优势
从可视化结果(图 5)可以看出,ShotStream 能够完美处理“分镜头”脚本。例如在生成一段两名女性在办公室内交互的视频时,它能精准保持两人的角色特征(如眼镜、衣着)在多次镜头切换(Shot Cut)中保持稳定,而对比方法(如 LongLive)则出现了角色身份错乱的问题。
深度洞察:未来的交互式电影
ShotStream 的出现意味着我们距离“实时互动电影”更近了一步。虽然它目前在处理极度复杂的 Prompt 时仍有提升空间,但其展示的因果蒸馏和双缓存策略为视频生成模型的大规模部署提供了教科书级的参考。
局限性
- 骨干网限制:目前的 1.3B 参数量还是偏小,在大规模复杂场景下偶有变形。
- 加速空间:虽然达到 16 FPS,但距离极致的流畅互动(如 30+ FPS)仍有优化余地,未来可结合 Sparse Attention 进一步压榨性能。
总结:如果你正在寻找一种既能保证叙事连贯,又能实时跑在单张显卡上的长视频生成方案,ShotStream 无疑是目前的最佳答案。