This paper identifies two distinct failure modes in LLM Post-Training Quantization (PTQ): Signal Degradation and Computation Collapse. It reveals that while 4-bit quantization typically suffers from cumulative noise, 2-bit quantization triggers a "performance cliff" due to the total breakdown of internal computational mechanisms.
TL;DR
Why does 4-bit quantization work so well while 2-bit often leads to a total model meltdown? This paper uncovers that these aren't just different degrees of the same problem. They are two different beast: Signal Degradation (noise in the system) and Computation Collapse (the system itself breaks). While we can "denoise" the former with clever tricks, the latter requires a complete structural rebuild.
The Problem: The Catastrophic "Performance Cliff"
In the world of Large Language Models (LLMs), Post-Training Quantization (PTQ) is the magic that lets us run massive models on consumer hardware. 4-bit is the "sweet spot," but moving down to 2-bit usually results in the model babbling incoherent nonsense or repeating stop words.
Prior research historically viewed this as a numerical problem—just "too much error." However, this paper argues that at 2-bit, the model's internal logic—how it recalls facts and processes tokens—actually physically breaks down.
The Two Failure Modes Hypothesis
The researchers propose a diagnostic framework to categorize these failures:
- Signal Degradation (Failure Mode I): Seen in 4-bit models. The "circuitry" is fine, but the data flowing through it is noisy. The correct answer is still there, buried under layers of cumulative precision loss.
- Computation Collapse (Failure Mode II): Typical of 2-bit models. The "gates" and "switches" (Attention heads and FFN layers) stop working entirely. The signal isn't just noisy; it's deleted in the very first layers of the model.
Methodology: Peering into the "Ghost in the Machine"
To prove this, the authors didn't just look at accuracy scores; they looked at the Logit Lens (mapping hidden states back to words) and Causal Tracing (patching "clean" data into a "broken" model).
1. Internal Representation Breakdown
Using Centered Kernel Alignment (CKA), they visualized how similar a quantized model's internal "thought process" is to the original FP16 version.
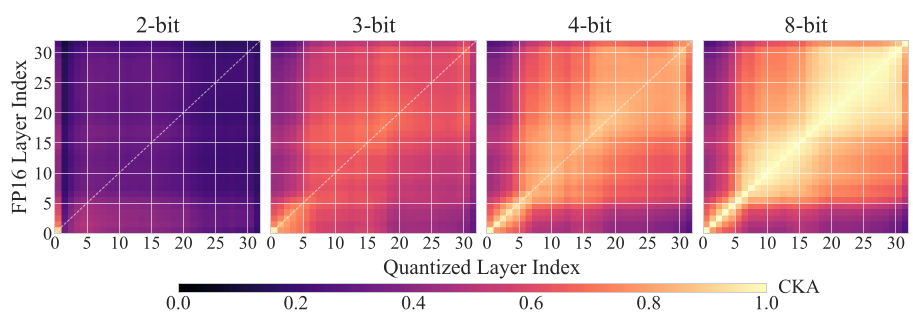 In the image above, the 4-bit model maintains a clear diagonal (meaning it's thinking similarly to the original), while the 2-bit model is a "pitch black" void, indicating total structural collapse.
In the image above, the 4-bit model maintains a clear diagonal (meaning it's thinking similarly to the original), while the 2-bit model is a "pitch black" void, indicating total structural collapse.
2. Component Malfunction
The study found that in 2-bit models:
- Attention Mechanisms lose their focus, with entropy skyrocketing. They stop "looking" at the right tokens.
- FFN (Feed-Forward Networks), which act as the model's memory, suffer from a high "Sign Flip Rate." Essentially, the "on/off" switches for neurons start flipping randomly, causing the model to retrieve entirely wrong concepts.
Experimental Proof: Repairability
The authors designed a "Two-Stage Repair" for the Signal Degradation mode:
- Source Protection: Keep the first two layers (the most sensitive ones) at a slightly higher precision.
- Peak Signal Amplification: Boosting the "confidence" of the internal signals at the layers where they are strongest.
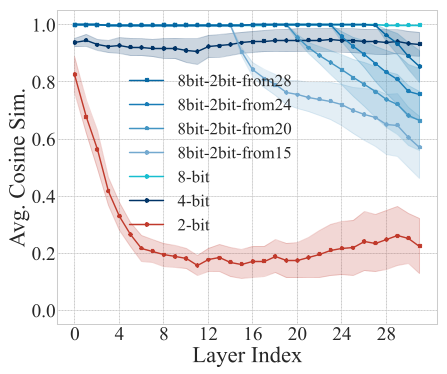 As seen above, the orange line shows how these interventions can "rescue" a 4-bit model's logic, bringing it close to the original FP16 baseline.
As seen above, the orange line shows how these interventions can "rescue" a 4-bit model's logic, bringing it close to the original FP16 baseline.
The Catch: These same interventions did nothing for 2-bit models. Even when the researchers gave 2-bit layers "perfect" input from an FP16 model, the 2-bit layers immediately destroyed the information. This proves that 2-bit components are fundamentally non-functional.
Critical Insight & Future Outlook
This work shifts the quantization conversation from "how much error is okay?" to "is the model's logic still intact?"
Key Takeaways for Engineers:
- 4-bit PTQ is highly salvageable. If your 4-bit model is failing, look at protecting the early layers or amplifying logits.
- 2-bit PTQ currently cannot be fixed by simple "calibration" or numerical tricks. If you need 2-bit, you likely need Quantization-Aware Training (QAT) or structural reconstruction to teach the model how to function with such low precision.
This diagnostic framework provides a roadmap for the next generation of "principled" quantization, moving away from trial-and-error toward a mechanistically grounded approach to model compression.