FLAIR (Full-duplex LAtent and Internal Reasoning) is a novel speech-to-speech dialogue framework that introduces a "think-while-listening" mechanism. By performing continuous latent reasoning during user speech perception, it achieves SOTA performance on benchmarks like MMSU and OpenbookQA without adding inference latency.
Executive Summary
TL;DR: FLAIR is a breakthrough in Full-Duplex Spoken Dialogue Language Models (SDLMs) that allows AI to "think while listening." By replacing useless silence tokens with continuous latent reasoning embeddings during the user's turn, the model prepares its response internally before the user even finishes speaking.
Background: Historically, spoken AI followed a "Stop-and-Think" sequential pattern. Even recent full-duplex models like Moshi mostly "idled" while the user spoke. FLAIR is a SOTA-refining work that introduces a variational inference framework to give speech models a "subconscious" reasoning capacity, significantly boosting intelligence without the latency tax of traditional Chain-of-Thought (CoT).
Problem & Motivation: The "Idle" Listening Window
In human conversation, we don’t wait for a speaker to finish before we start processing information. We think concurrently.
Current SDLMs face a trilemma:
- The Padding Problem: Most models just predict
<SIL>tokens while listening, wasting 50% of the conversation's computational window. - The CoT Mismatch: Generating explicit text thoughts (Chain-of-Thought) during a user's speech is non-causal and risks "locking" the model into a thought chain when the user suddenly stops or changes the subject.
- Latency Constraints: Real-time interaction requires near-zero delay; any explicit "thinking step" after the user finishes is a UX failure.
The Insight: Authors hypothesize that reasoning doesn't need to be linguistic. By maintaining an information-rich latent state that evolves with the streaming audio, the model can accumulate "reasoning cues" implicitly.
Methodology: ELBO and the Global-aware Expert
The core challenge of latent reasoning is supervision: how do you train a model to "think" when there are no "thought labels"?
1. The Architecture
FLAIR uses an "Always-on" LLM backbone. During the user's speech phase (), the model takes its previous hidden state, projects it to vocabulary logits, and computes a weighted average of the embedding matrix to serve as the next input.
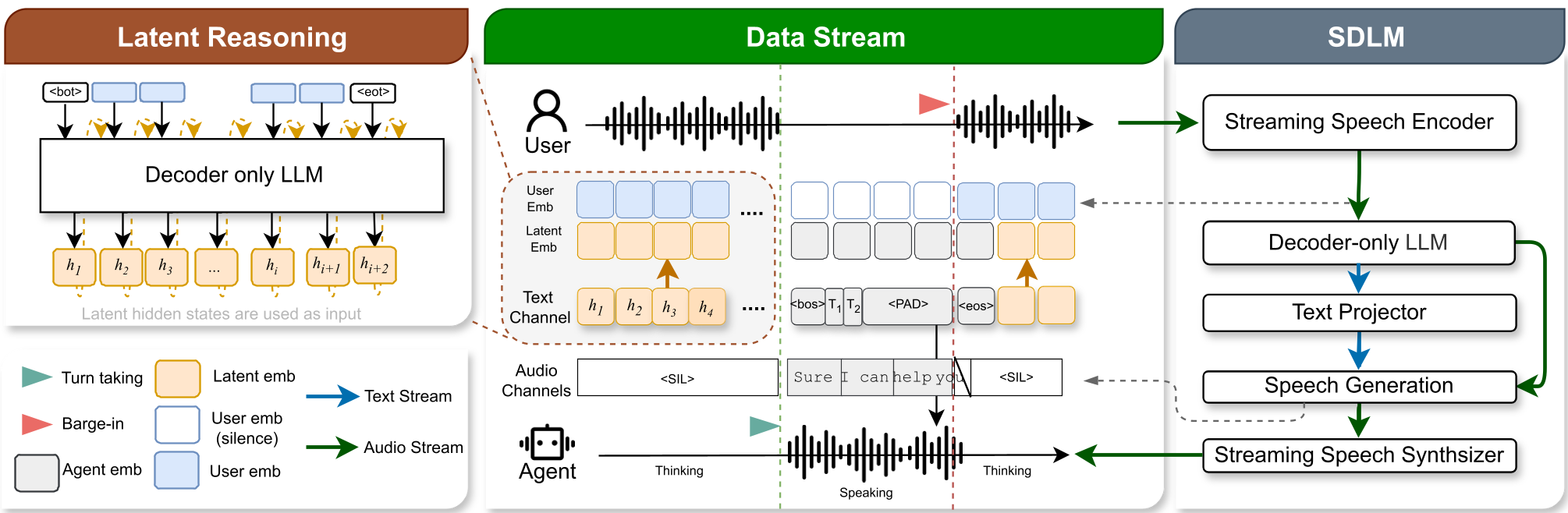
2. Variational Training (ELBO)
To supervise these "internal thoughts," FLAIR employs Variational Inference:
- The Global-aware Expert: A non-causal model that sees the entire dialogue (including the future response). It generates the "ideal" latent reasoning embeddings.
- The Causal SDLM: The real-time model that only sees the past. It is trained to minimize the KL Divergence between its latent prior and the Expert's posterior.
This effectively "distills" the wisdom of hindsight into a real-time, causal model.
Experiments & Results: Intelligence Without Delay
FLAIR was tested against heavyweights like Moshi, GLM-4-Voice, and Qwen2-Audio.
Reasoning Performance
The "think-while-listening" mechanism provided a massive boost in tasks requiring deep logic. On the MMSU (Massive Multi-task Spoken Understanding) benchmark, FLAIR jumped from 50.2% (without thinking) to 56.2%.

Conversational Dynamics
Crucially, this "thinking" doesn't make the model slow. FLAIR maintains a Turn-taking Latency of ~0.39s, outperforming Gemini Live’s reported ~1.3s.
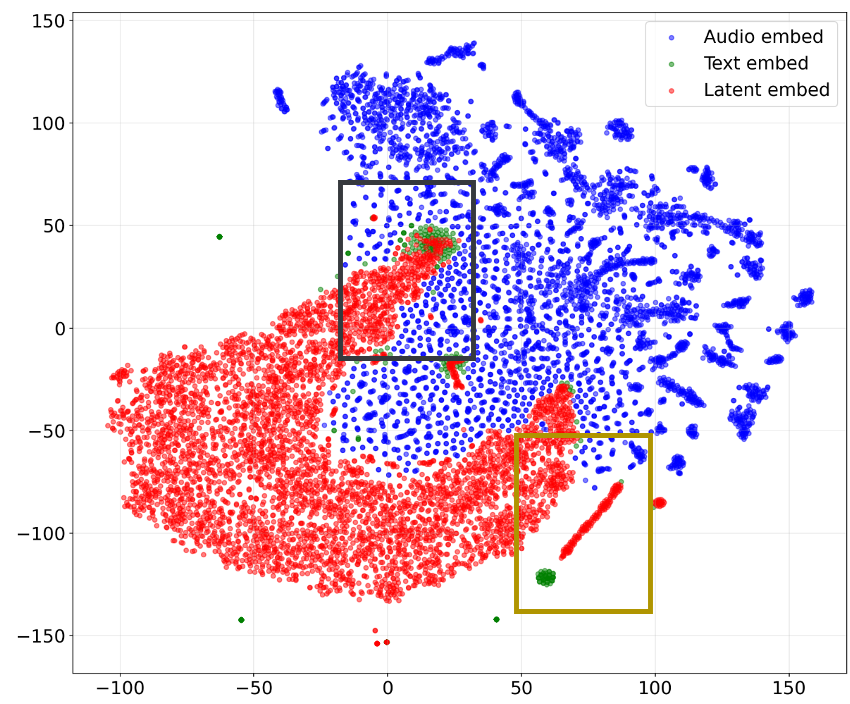
Visualization: The Manifold Bridge
Using t-SNE, the authors showed that latent embeddings act as a physical bridge in the manifold space, moving from the "Audio Input" cluster toward the "Target Text" cluster before the response even begins.
Critical Analysis & Conclusion
Takeaway: FLAIR proves that thinking is not necessarily speaking. By shifting CoT from the discrete token space to the continuous latent space, we solve the synchronization and latency issues of real-time AI.
Limitations:
- The model relies on synthetic data; performance on extremely noisy or overlapping multi-speaker environments remains a frontier.
- The "Expert" model requires a non-causal view, which adds complexity to the training pipeline even if it is discarded during inference.
Future Outlook: This work opens the door for "subconscious" multimodal models—AI that processes vision, touch, and sound in a continuous latent stream, forming a world model that is always one step ahead of the explicit response.