本文提出了 FLAIR,一种针对全双工语音对话模型(SDLM)的隐式推理框架。通过在用户说话时同步进行隐式空间(Latent Space)推理,FLAIR 实现了“边听边想”机制,在不增加推理延迟的情况下显著提升了语音响应的逻辑性和准确性,并在多项语音基准测试中达到 SOTA。
TL;DR
长期以来,语音助手在听你说话时通常是“大脑空白”的。本文提出的 FLAIR (Full-duplex LAtent and Internal Reasoning) 改变了这一现状。它通过在隐性向量空间中进行实时推理,让模型在听的过程中同步“思考”,不仅让回答更聪明,还完美解决了流式语音交互中的延迟与中断难题。
领域定位:这是首个将隐式推理(Latent Reasoning)引入全双工语音大模型(SDLM)的工作,是迈向类人实时对话交互的关键一步。
1. 痛点深挖:为什么“边听边说”这么难?
在人类交流中,我们会在听对方说话的同时构思回答。但在当前的语音 AI 中,存在两个极端:
- 复述模式:模型在听的时候只能重复输出
<SIL>(静默符),导致计算资源在最关键的构思阶段处于闲置。 - 显式 CoT 模式:虽然可以让模型在后台生成文字推理,但语音是流式的,你不知道对方什么时候停。如果模型正“想”到一半(生成文本标记中),强行中止会造成状态紊乱,继续想则会增加延迟。
FLAIR 的核心洞察 (Insight):既然文本太死板,为什么不直接在隐藏状态 (Hidden States) 里思考?
2. 核心方法论:基于 ELBO 的“潜意识”训练
FLAIR 的天才之处在于它将“思考”转化为一个变分推断问题。
架构解析
FLAIR 包含一个因果(Causal)模型和一个全局专家(Global-aware Expert)模型:
- 训练时:专家模型可以“偷看”完整的对话录音和最终的正确文本回答。利用 ELBO (证据下界) 目标函数,专家预测出理想的“思考向量”。
- 对齐时:通过 KL 散度,强迫只能实时听语音的因果模型去模仿专家的思考轨迹。
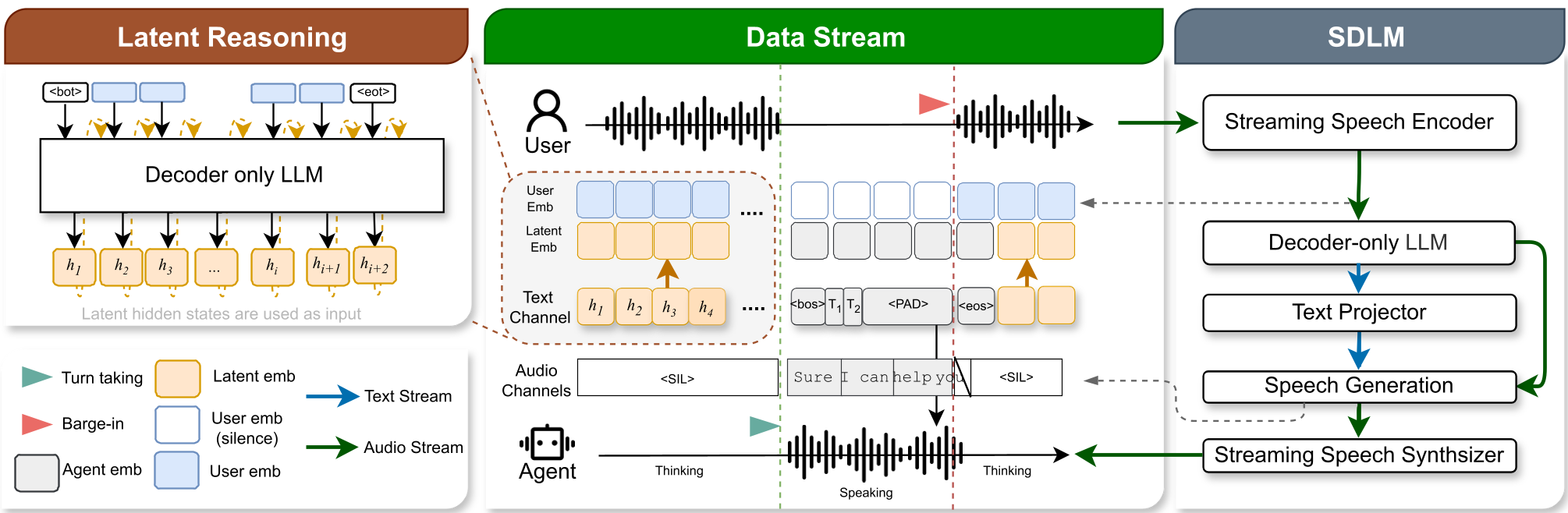 图注:FLAIR 流程展示。用户说话时,模型将上一步的 Logits 加权后作为下一步输入,实现连续空间的隐式推理。
图注:FLAIR 流程展示。用户说话时,模型将上一步的 Logits 加权后作为下一步输入,实现连续空间的隐式推理。
物理直觉:隐式空间中的“桥梁”
作者通过 t-SNE 可视化揭示了 FLAIR 的工作原理:隐式推理向量实际上是在高维流形中,从“输入音频”向“目标答案”搭建的一座桥梁。 这种连续的演化比跳跃的文本 Token 更符合认知的物理直觉。
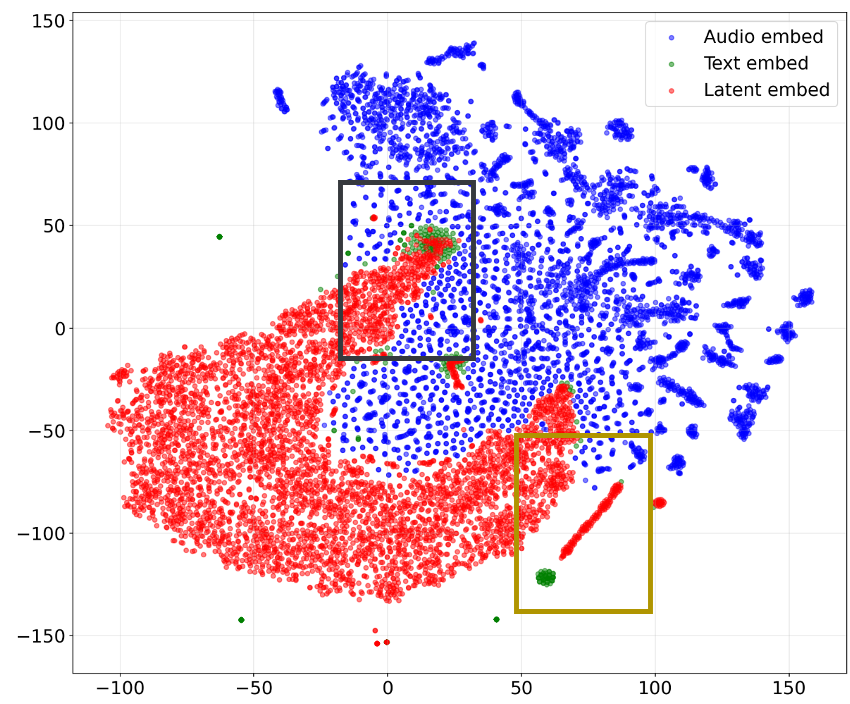 图注:可以看到隐式推理向量(蓝色)如何优雅地连接起音频输入(绿色)和文本回答(红色)。
图注:可以看到隐式推理向量(蓝色)如何优雅地连接起音频输入(绿色)和文本回答(红色)。
3. 实验战绩:高智商且低延迟
通过大规模合成数据(53万小时语音数据)训练,FLAIR 展示了极强的竞争力:
- 推理能力大幅提升:在 MMSU(复杂语音理解基准)上,带推理的版本显著优于基线。
- 交互丝滑:在全双工测试中,FLAIR 的平均响应延迟仅为 0.39s,能完美处理用户的插话。
 图注:FLAIR 与各大模型在 QA 任务上的对比,在保持全双工特性的同时,性能直逼半双工的标杆模型。
图注:FLAIR 与各大模型在 QA 任务上的对比,在保持全双工特性的同时,性能直逼半双工的标杆模型。
4. 深度洞察与总结
核心价值: FLAIR 证明了推理不需要非得变成“文字”。在语音这种对时间高度敏感的领域,隐式推理展现出了比显式 CoT 更高的稳健性和效率。它不仅能够提升回答质量,还能让模型更“懂”什么时候该插话,什么时候该闭嘴。
局限性: 目前这种“思考”仍是黑盒化的,人类无法直接解释模型在听的过程中到底“想”了什么(因为它没有输出文字)。如何让隐式推理既高效又可解释,将是下一个研究热点。
未来展望: 这种“边听边想”的架构可能会成为下一代语音交互助手的标准配置,甚至可能推广到多模态视频交互中,让 AI 真正具备实时观察、思考并反馈的能力。
参考文献:Wu, D., et al. (2025). The Silent Thought: Modeling Internal Cognition in Full-Duplex Spoken Dialogue Models via Latent Reasoning. arXiv.