本文提出了 SIMART,一个统一的多模态大语言模型(MLLM)框架,旨在将静态 3D 扫描或生成的网格(Mesh)直接分解为可模拟的(Sim-ready)有铰接关系的资产。该方法引入了 Sparse 3D VQ-VAE 压缩技术,在保持高保真几何的同时将 token 数量减少了 70%,在 PartNet-Mobility 和 AIGC 数据集上达到了 SOTA 性能。
TL;DR
在 Embodied AI(具身智能)领域,高精度的“可交互 3D 资产”是稀缺资源。字节跳动 Seed 团队与南洋理工大学提出的 SIMART 框架,通过统一的 MLLM 架构,能够直接从一个静态的 3D 模型(Monolithic Mesh)中“读懂”它的机械结构,并自动输出包含部件分割、转轴位置、关节限位等信息的 URDF 文件。其引入的 Sparse 3D VQ-VAE 成功解决了 3D Token 冗余导致的内存爆炸问题。
1. 痛点:为什么“仿真就绪”这么难?
在物理仿真(如 NVIDIA Isaac Sim)中,一个物体不仅要有形状,还要有“逻辑”:
- 几何脱节:传统方法先做 2D 分割再投影回 3D,边缘往往模糊,导致抽屉拉不开、门关不严。
- 运动学失效:现有的 3D 生成模型(如 TRELLIS)生成的是一整块“死”的 Mesh,没有任何运动学元数据。
- 计算瓶颈:之前的 3D MLLM 试图用 或 的体素块,但其中 90% 的空间是空的,浪费了极大的上下文长度。
2. 核心技术:Sparse 3D VQ-VAE
SIMART 并没有暴力堆砌算力,而是意识到 3D 数据的本质是稀疏的。
几何压缩黑科技
作者设计了一个稀疏 VQ-VAE 架构。关键在于 Zero Token (ezero) 机制:
- 在编码阶段,识别非占据(空的)体素并分配专门的零索引。
- 仅对占据表面几何特征的区域进行向量量化。
- 这种策略让输入给 MLLM 的 Token 数量减少了 70%。
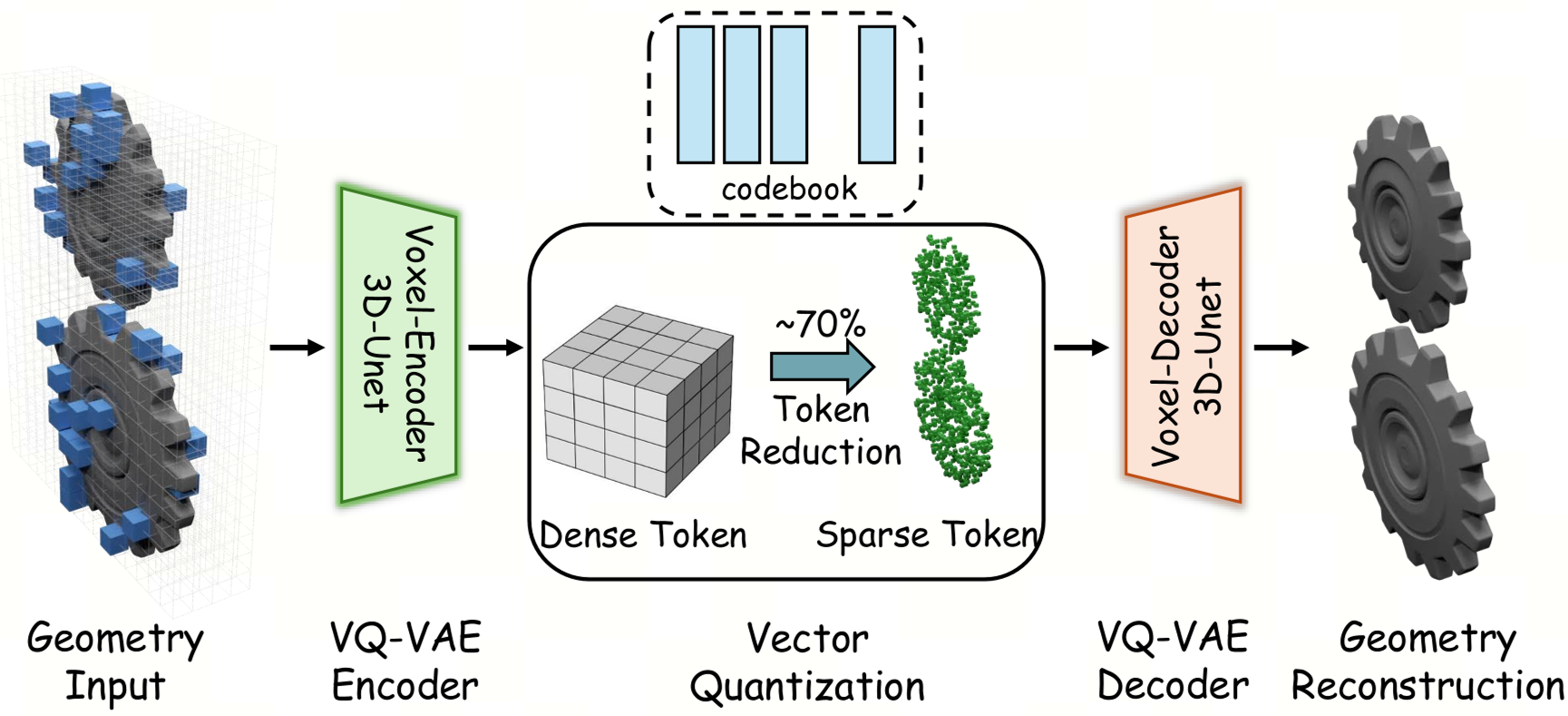 图 1:Sparse 3D VQ-VAE 架构,通过 3D-UNet 实现高保真的几何编码与稀疏化。
图 1:Sparse 3D VQ-VAE 架构,通过 3D-UNet 实现高保真的几何编码与稀疏化。
3. 统一的 MLLM 推理流
SIMART 使用 Qwen3-VL-8B 作为大脑,将视觉图像、稀疏几何 Token 和文本指令对齐:
- Input:物体的多视图渲染 + 坐标感知(Coordinate-aware)的稀疏 Voxel 序列。
- Reasoning:模型需要思考“基于这个物体的语义,它的把手在哪里?转轴应该垂直还是水平?”
- Output:同时生成 Part-level Voxel Seeds 和 URDF JSON(包含关节类型、轴线、物理密度、摩擦系数等)。
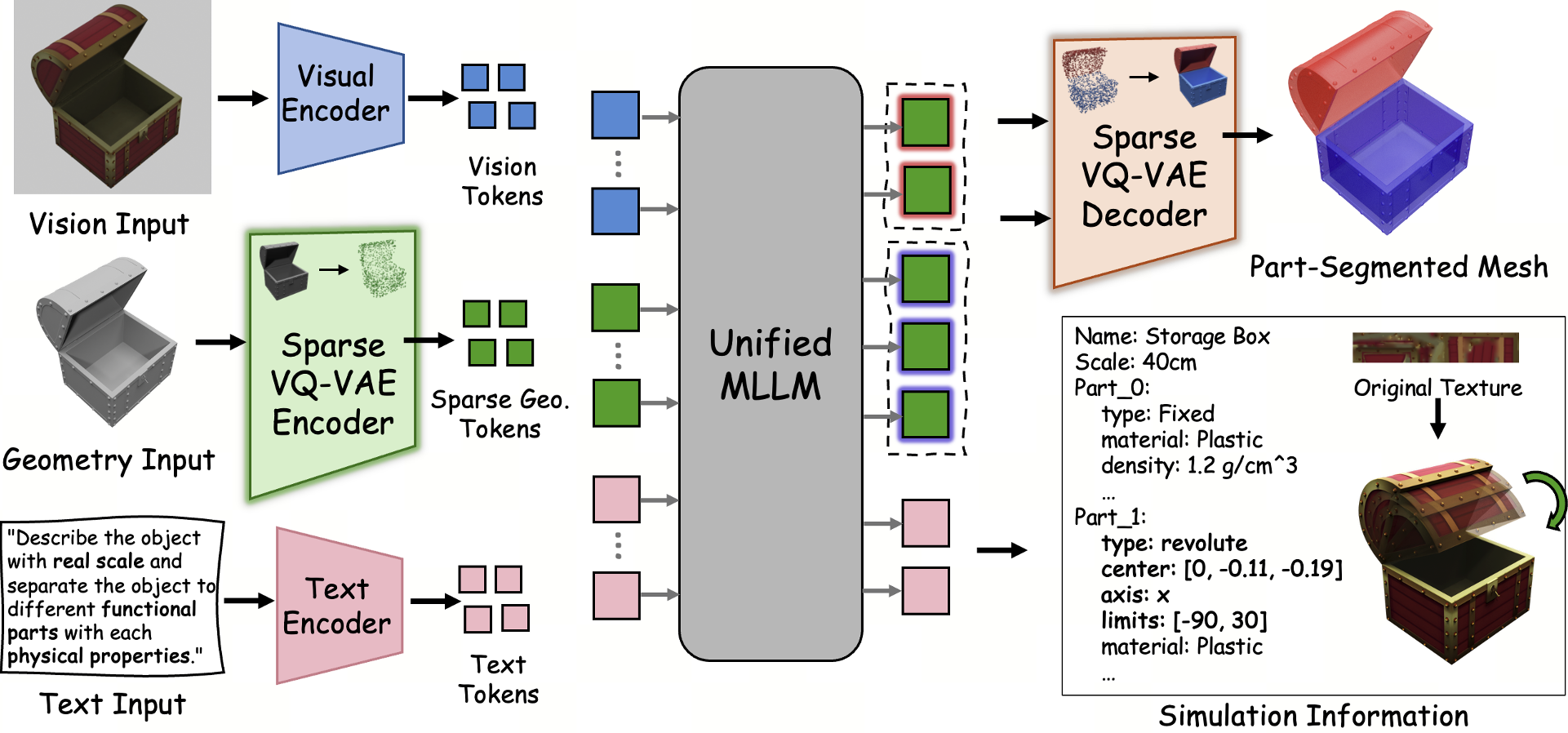 图 2:SIMART 整体流程:从几何编码到 MLLM 推理,再到最终的仿真部署。
图 2:SIMART 整体流程:从几何编码到 MLLM 推理,再到最终的仿真部署。
4. 实验验证:SOTA 级别的性能表现
为了公平对比,作者推出了 SIMART-Bench,其中包含了大量 AI 生成的、形态怪异的 OOD(分布外)物体。
| Method | Axis Error (↓) | IoU (↑) | CD (↓) | | :--- | :---: | :---: | :---: | | Articulate-Anything | 0.315 | 0.202 | 0.239 | | PhysX-Anything | 0.312 | 0.128 | 0.278 | | SIMART (Ours) | 0.080 | 0.690 | 0.087 |
消融研究 (Ablation Study) 表明,如果使用传统的 Dense Token 方案,系统会直接 OOM (Out-of-Memory);只有 Sparse 方案能处理包含 4 个以上复杂部件的物体。
 图 3:定性对比显示,SIMART 生成的铰接状态(State-1)远比基线模型更符合物理逻辑。
图 3:定性对比显示,SIMART 生成的铰接状态(State-1)远比基线模型更符合物理逻辑。
5. 深度洞察与总结
SIMART 的成功在于它意识到 “物理认知比几何重建更重要”。通过将几何特征编码为可学习的离散 Token,它让语言模型能够像处理单词一样处理 3D 关节。
局限性与未来
- 数据匮乏:高质量带标注的铰接资产依然稀缺。作者提出未来可以用 SIMART 作为一个伪标签生成器,实现数据生成的闭环。
- 动态复杂度:目前主要针对简单运动链,对于柔性物体或复杂的齿轮联动仍有待探索。
Takeaway:如果你正在为机器人训练寻找多样化的仿真环境,SIMART 提供了一种将互联网上海量静态 3D 模型一键转化为“仿真教具”的工业级方案。