This paper introduces SimCT (Simple Cross-Tokenizer OPD), a method for on-policy distillation between models with different tokenizers. By expanding the supervision space to include Minimal Aligned Units, SimCT recovers teacher signals lost during exact token matching, achieving SOTA performance in mathematical reasoning and code generation across heterogeneous model families.
TL;DR
On-policy distillation (OPD) is a powerful way to train smaller "student" LLMs by letting them learn from their own generations. However, if the teacher and student use different tokenizers (e.g., Qwen vs. Llama), they effectively speak different languages at the token level. SimCT solves this by finding "Minimal Aligned Units"—the smallest pieces of text both models agree on—to ensure no teacher knowledge is "lost in translation."
The Hidden Tax of Tokenizer Mismatch
Modern LLM distillation often pairs a powerful teacher (like Qwen2.5) with a nimble student (like Phi-4 or Gemma-2). But there’s a catch: these models rarely share a vocabulary. This creates two primary hurdles:
- Sequence Mismatch: The same word (e.g., "happy") might be split into
["hap", "py"]by the teacher and["ha", "pp", "y"]by the student. - Vocabulary Mismatch: Even if they align on the text, the teacher's preferred next token might not even exist in the student's dictionary.
Existing solutions often resort to heavy math (like Optimal Transport) or "coarse" matching (averaging over large chunks). These methods either slow down training significantly or blur the teacher's precise logic, leading to "hallucinated" reasoning in the student.
Methodology: Minimal Aligned Units
The core insight of SimCT is that we shouldn't force tokens to match; we should expand the space where we compare them.
1. Finding the Common Ground
SimCT identifies Minimal Aligned Units (A). As shown in the diagram below, these are the finest shared text continuations that both tokenizers can realize. By focusing on these units, SimCT creates a "supervision bridge" between the two models.
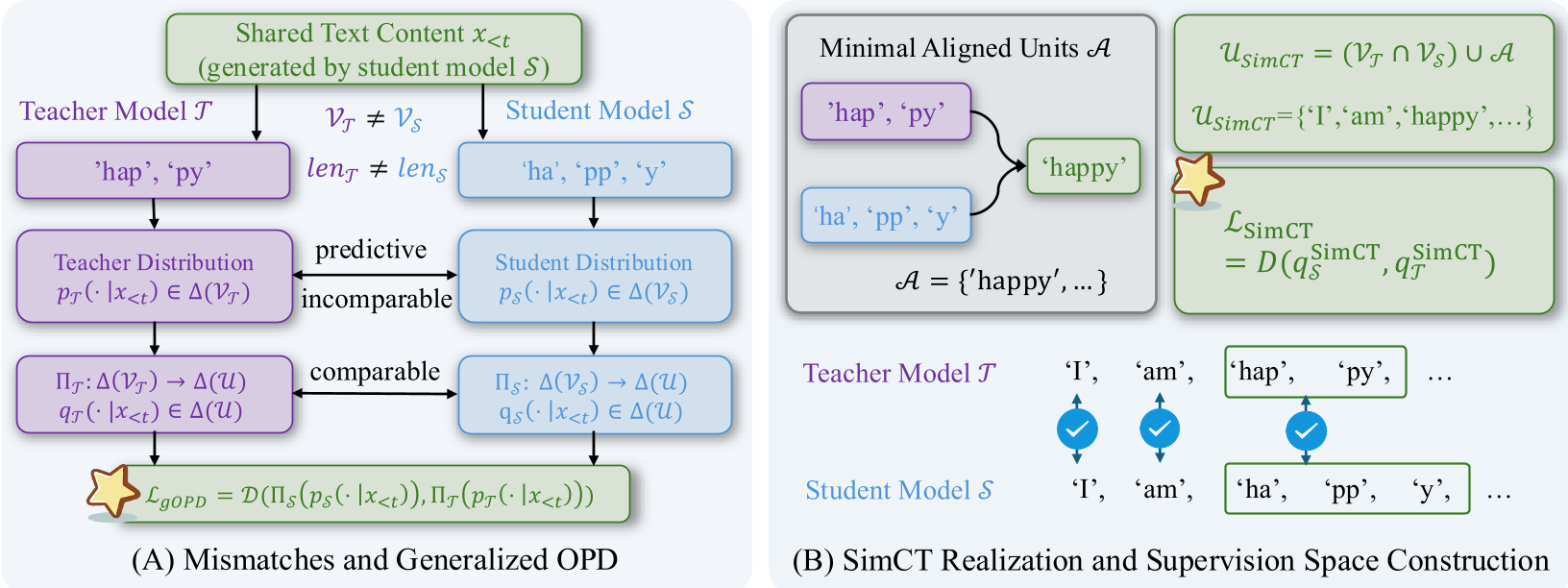
2. Scoring beyond Tokens
Instead of a simple token probability, SimCT uses an average log-likelihood for multi-token units. This prevents the model from unfairly penalizing units that happen to require more tokens in one model's vocabulary, ensuring a fair "preference" distribution.
3. The Power of "Fineness"
The authors prove mathematically that these minimal units are the finest possible interface. If you make the units any larger (coarsening), you lose the "within-unit" distinctions that help the student understand why the teacher picked a specific reasoning path.
Experimental Results: Precision Matters
SimCT was tested on grueling benchmarks for mathematical reasoning (GSM8K, MATH-500) and coding (MBPP, LiveCodeBench).
- Consistency: Across all teacher-student pairs, SimCT was the only method to consistently beat the Supervised Fine-Tuning (SFT) baseline.
- Efficiency: It adds negligible overhead compared to the simplest "shared-only" distillation, making it much faster than complex alternatives like DSKD or GOLD.
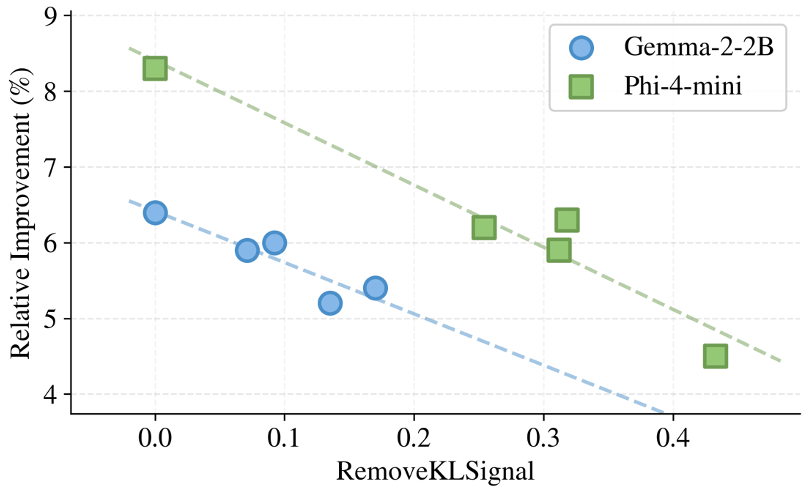 The figure above demonstrates that the more mismatch supervision we recover, the better the performance. Conversely, "coarsening" the units (making the supervision interface larger) directly leads to a loss of the KL signal and lower accuracy.
The figure above demonstrates that the more mismatch supervision we recover, the better the performance. Conversely, "coarsening" the units (making the supervision interface larger) directly leads to a loss of the KL signal and lower accuracy.
Case Study: Why Logic Fails
In math problems, a single digit error in a long division can ruin the whole answer. SimCT’s fine-grained supervision preserves the teacher’s "arithmetic precision." In the paper’s case studies, baselines often got the logic right but failed the calculation because the supervision was too coarse to correct small token-level deviations.
Critical Analysis & Conclusion
Takeaway
SimCT proves that in LLM distillation, the interface is as important as the objective. By simply allowing the teacher to supervised "mismatched" segments, we unlock a massive amount of training signal that was previously being thrown away.
Limitations & Future Work
- Tokenizer Diversity: While it works for BPE/WordPiece, it might need adjustments for character-level or byte-level models.
- Scale: The current study focuses on models up to 7B. How the "Minimal Aligned Unit" concept scales to 70B+ models with massive vocabularies remains an open question.
- Black-Box Distillation: SimCT currently requires access to the teacher's logits (white-box). A black-box version (using only samples) would be a game-changer for proprietary models.
In conclusion, SimCT offers an elegant, "simple" (as the name implies) fix to a pervasive problem in LLM deployment, ensuring that the next generation of small models can truly inherit the wisdom of their larger predecessors.