本文提出了 SimCT,一种针对异构分词器(Cross-Tokenizer)的策略内蒸馏(On-policy Distillation, OPD)方法。该方法通过构建包含“最小对齐单元”(Minimal Aligned Units)的共享监督空间,在保持标准 OPD 损失函数不变的情况下,实现了 SOTA 性能。
TL;DR
在大型语言模型(LLM)的蒸馏过程中,如果老大哥(教师模型)和小学弟(学生模型)使用的是不同的分词器(Tokenizer),传统的“手拉手”式对齐就会失效。SimCT (Simple Cross-Tokenizer OPD) 提出了一种极其优美且简单的方案:与其强行让两个模型在不兼容的 Token 层次上硬碰硬,不如寻找它们都能理解的“最小对齐单元”。该方法在数学和代码任务中显著提升了蒸馏效果,且几乎没有引入额外的计算开销。
痛点深挖:消失的监督信号
在**策略内蒸馏(On-policy Distillation, OPD)**中,学生模型边跑边练,教师模型则针对学生生成的每个前缀给出“锦囊妙计”(Next-token Distribution)。
然而,现实往往是残酷的:
- 词表错配 (Vocabulary Mismatch):教师和学生的词表交集可能很小,教师的高概率 Token 往往不在学生的备选名单里。
- 序列错配 (Sequence Mismatch):同一个单词(如 "happy"),教师可能切成
["hap", "py"],学生切成["ha", "pp", "y"]。
传统的做法(如 SimpleOPD)由于无法在 Token 级别对齐,往往会直接丢弃这些位置的反馈。这就像是一个只会背字典的老师,因为学生写了一个生僻词(即使语义是对的),就无法给出批改意见,导致大量教学机会被浪费。
核心直觉:寻找“最小对齐单元”
SimCT 的核心贡献在于它重新定义了监督空间。它提出了一个理论:在任何分词器错配的文本区域,都存在一个共同的、最细粒度的对齐边界。
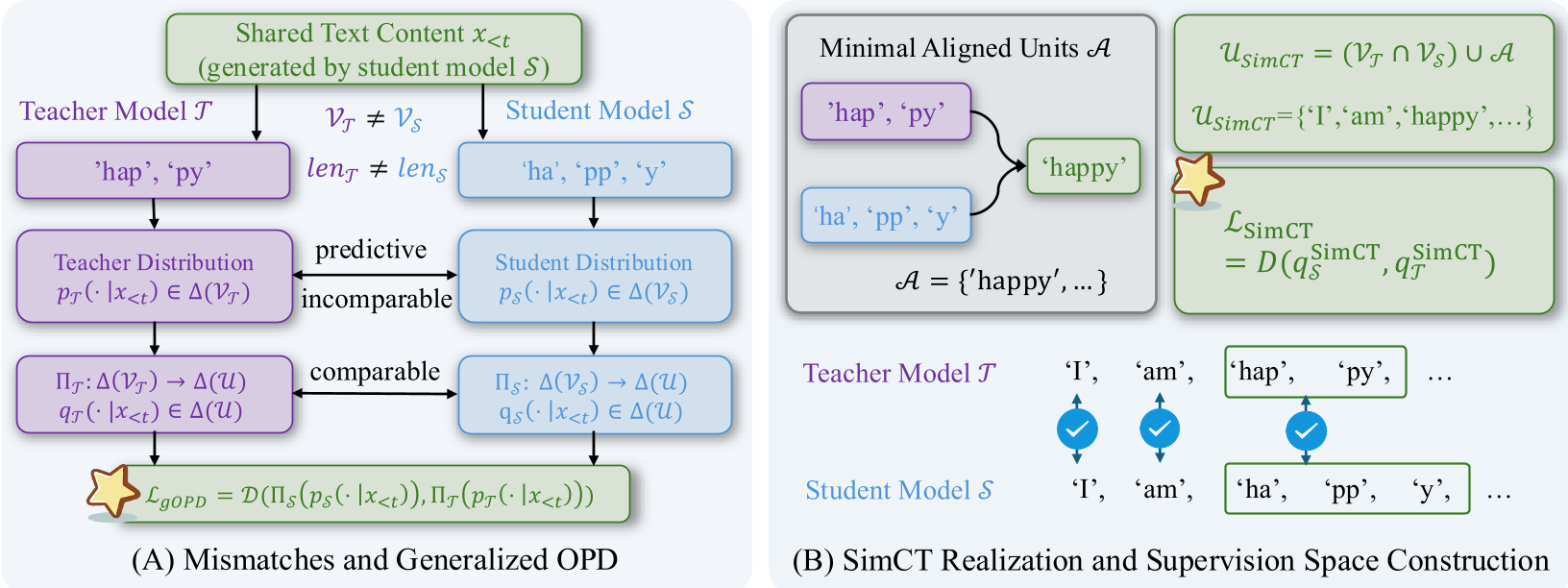
SimCT 的工作流程:
- 构建空间:将完全一致的 Token 和这种“最小对齐单元”(Minimal Aligned Units)结合,形成一个新的监督空间 。
- 打分机制:对于多 Token 组成的对齐单元,使用平均对数似然(Average Log-likelihood)来计算分数,避免因长度不同产生的偏差。
- 无缝集成:将这些分数归一化后,直接输入到标准的 Reverse-KL 损失函数中。
这种方法精妙在它不需要额外的参数(如 DSKD 需要投影层),也不需要复杂的计算(如 GOLD 需要的最优传输),它完美的保留了局部的、精细的教师偏好信号。
实验战绩:全线飘红
作者在 Qwen2.5-7B、Phi-4-mini 和 Gemma-2 等异构模型对上进行了严苛的测试。
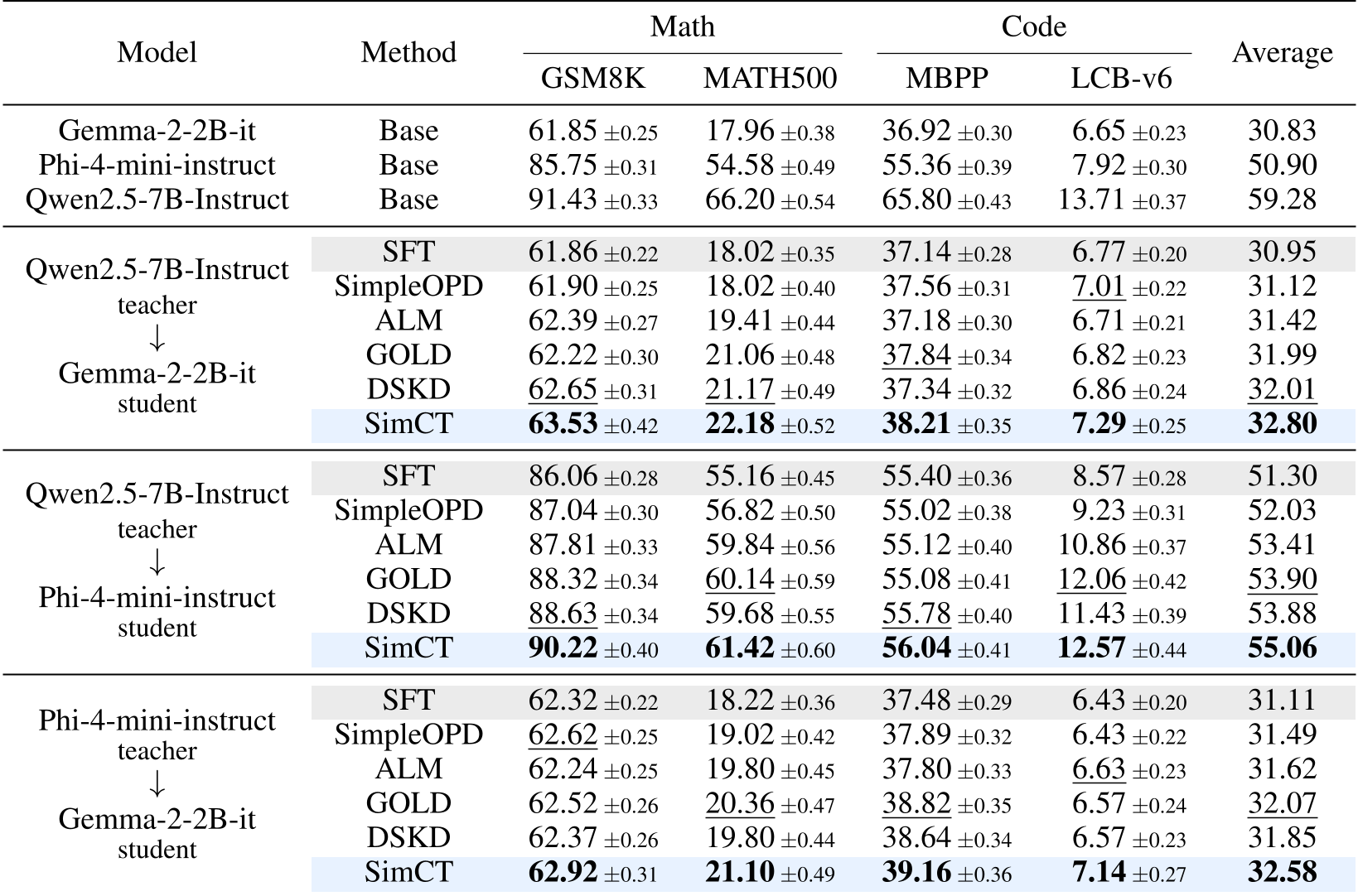
- 数学推理:在 MATH-500 和 GSM8K 上,SimCT 显著超过了 SFT 和各种跨分词器 baseline。
- 代码生成:在 MBPP 等任务中,SimCT 展现了更强的算法逻辑捕获能力。
深度消融:为什么越细越好?
论文提供了一个非常有趣的观察(如下图右侧):如果你把这些“最小单元”合并成更粗的块(Coarsening),蒸馏效果会随之下降。
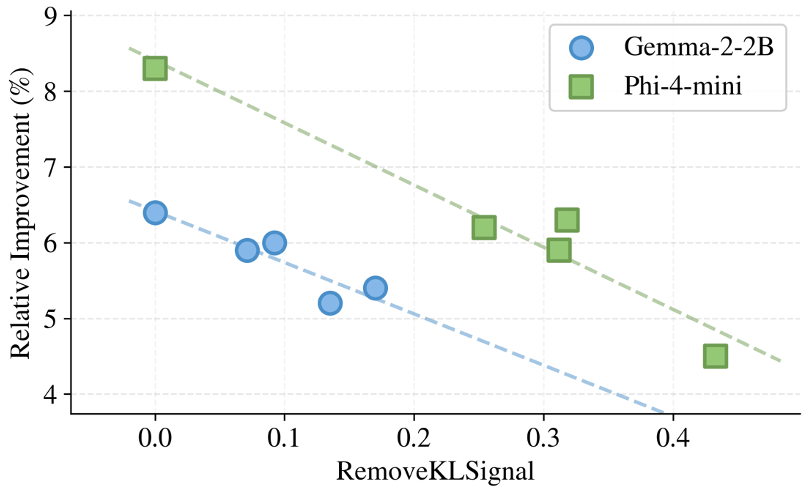
分析结论:粗粒度的对齐会抹杀“单元内部”的细微概率差异,而这些差异正是模型学习逻辑和精确度的关键。正如 Proposition 1 证明的那样:合并单元会由于 KL 散度的性质直接导致监督信号的损失。
总结与洞察
SimCT 证明了一个朴素的真理:在 AI 研究中,好的数据/监督界面设计(Interface Design)往往比更复杂的算法更有效。
它没有修改核心的 OPD 优化目标,而是通过找回被物理切分(Tokenizer)掩盖的语义关联,让跨模型族的“知识传递”变得前所未有的顺畅。对于那些想要把自己训练的大模型“压缩”到特定移动端芯片(通常分词器完全不同)的团队来说,SimCT 提供了一个高性能且低成本的“标准插件”。
局限性:目前主要针对类 BPE 的分词器。如果遇到基于字节(Byte-level)或其他完全不同范式的分词器,对齐算法可能需要进一步优化。