本文提出了 GeoSkill,一个无需针对参数进行微调(Training-free)的视觉地缘定位(Visual Geolocation)框架。该方法通过构建一个可进化的“技能图谱”(Skill-Graph),将人类专家的推理直觉转化为可组合的原子技能,实现了 SOTA 级别的定位精度与推理忠实度。
TL;DR
视觉地缘定位(Visual Geolocation)要求 AI 仅凭一张图片就能报出经纬度。传统的黑盒模型虽然有时能“猜中”,但往往由于缺乏逻辑而产生毁灭性的定位偏差。GeoSkill 另辟蹊径,它不改模型参数,而是给大模型(VLM)配了一本可以不断更新的**“专家技能手册”。通过构建技能图谱(Skill-Graph)**,模型能实现从植被、车牌到建筑风格的环环相扣推理,并能通过失败案例自我学习,让定位精度与逻辑忠实度双双打破记录。
痛点深挖:为什么 AI 总在地理定位上“一本正经地胡说八道”?
目前的主流方法存在两大死穴:
- 黑盒匹配的不可解释性:传统的 Feature-based 方法(如 GeoCLIP)通过嵌入向量匹配查找地点。你看不到它的思考逻辑,一旦遇到相似的植被(如地中海气候在多国有相似性),模型就会在万里之外迷失。
- “参数化记忆”的幻觉:强行微调大模型(Paradigm 2/3)虽然植入了地理知识,但知识是隐式的。模型经常会出现“因为这里有棕榈树,所以这是格陵兰岛”式的逻辑断层——即所谓的 “答案正确,逻辑全错”。
核心方法论:GeoSkill 的三位一体架构
1. 从专家经验到“原子技能”的蒸馏
既然 LVLM 容易产生幻觉,作者决定采用“冷启动”策略。他们分析了《GeoGuessr》世界冠军的比赛轨迹,将其非结构化的推理过程拆解为**原子技能(Atomic Skill)**三元组:⟨推理指令, 地理启发式逻辑, 置信度⟩。
2. 在线推理:动态构建技能图谱
不同于死记硬背,当 GeoSkill 看到一张新图时,它会经历四个阶段:
- 场景解析(Scene Parsing):识别路牌文字(OCR)、道路线、波杆风格等。
- 技能检索:从库中捞出最相关的地理规则(如:这种车牌属于安道尔)。
- 图谱合成:将零散技能组装成一张从“全球区域”到“细粒度坐标”的技能图谱。
- 双重锚定推理:每一条推论必须同时有“视觉证据”和“技能支撑”。
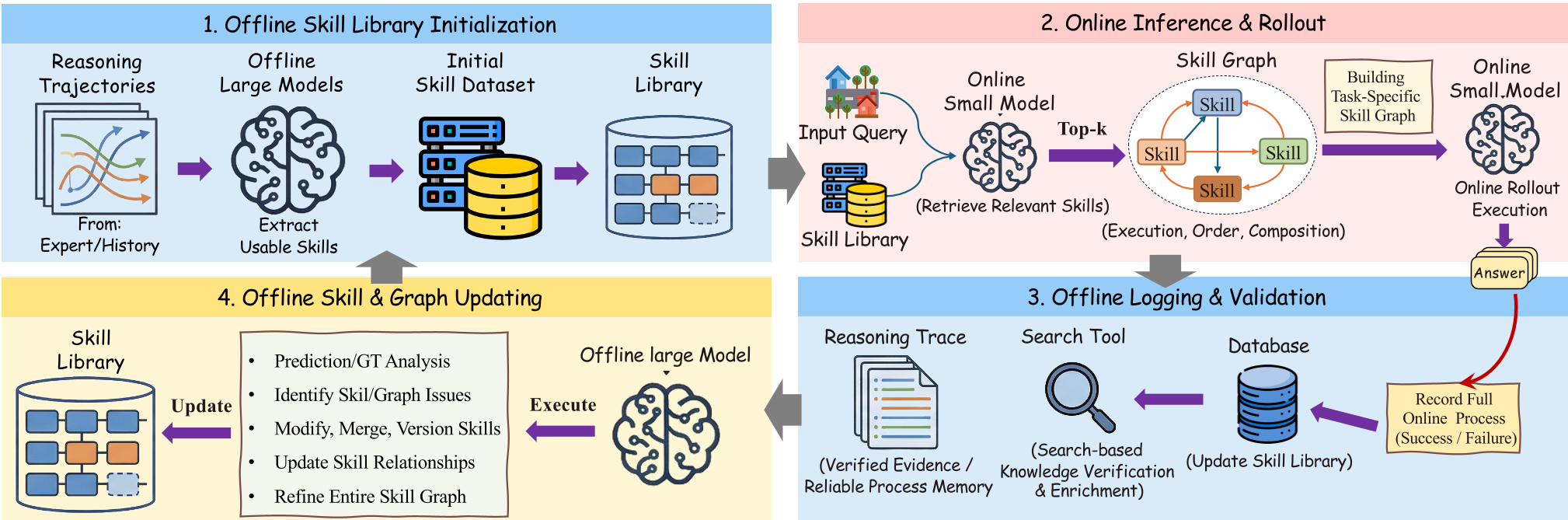 图1:GeoSkill 系统概览:从专家初始化到在线图谱构建与自进化闭环
图1:GeoSkill 系统概览:从专家初始化到在线图谱构建与自进化闭环
3. 自进化:训练外的自我修正
这是 GeoSkill 最具前瞻性的设计:它利用大型模型(如 GPT-5.2)作为“导师”,对小模型的错误轨迹进行诊断。
- 合成(Synthesis):针对失败案例自动编写并添加新技能。
- 合并(Merging):通过语义相似度压缩冗余规则。
- 修剪(Pruning):剔除那些导致高错误率的“坑爹”逻辑。
实验与结果:不仅准,而且“讲道理”
在 GeoRC(强调推理链的测试集)上,GeoSkill 的表现令人惊艳:
- 高精度:在 750km 级别精度上比强细调模型 GAEA 提升显著。
- 逻辑忠实度(Faithfulness):F1 分数达到 60.31,这意味着它的推理过程与人类专家高度对齐。
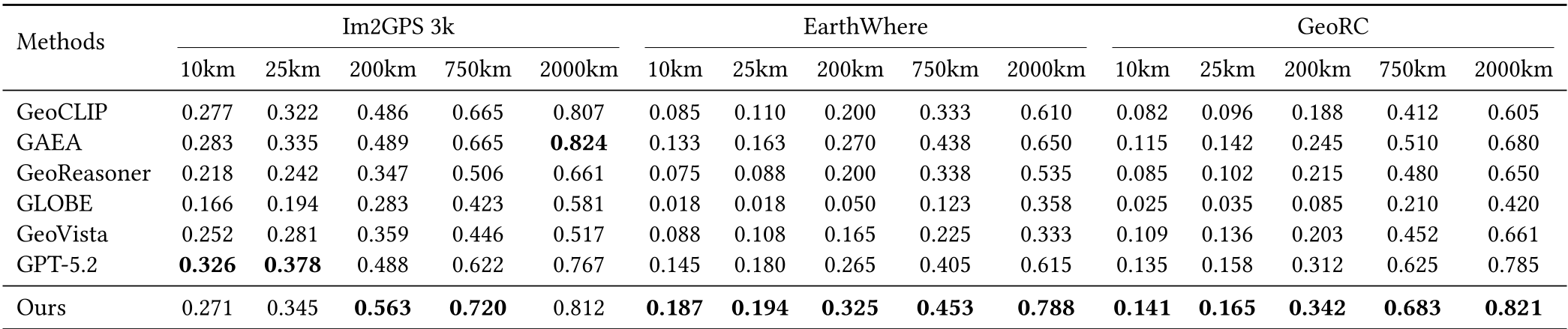 表1:不同模型在三大主流地理定位数据集上的性能对比
表1:不同模型在三大主流地理定位数据集上的性能对比
案例分析:安道尔的逻辑链
在处理一个复杂的安道尔(Andorra)案例时,GeoSkill 首先通过“Camí”路牌识别出加泰罗尼亚语系,接着识别出比利牛斯山脉的石木结构建筑,通过技能图谱排除了相似的希腊或加拿大干扰项,最终精准锁定街道位置。
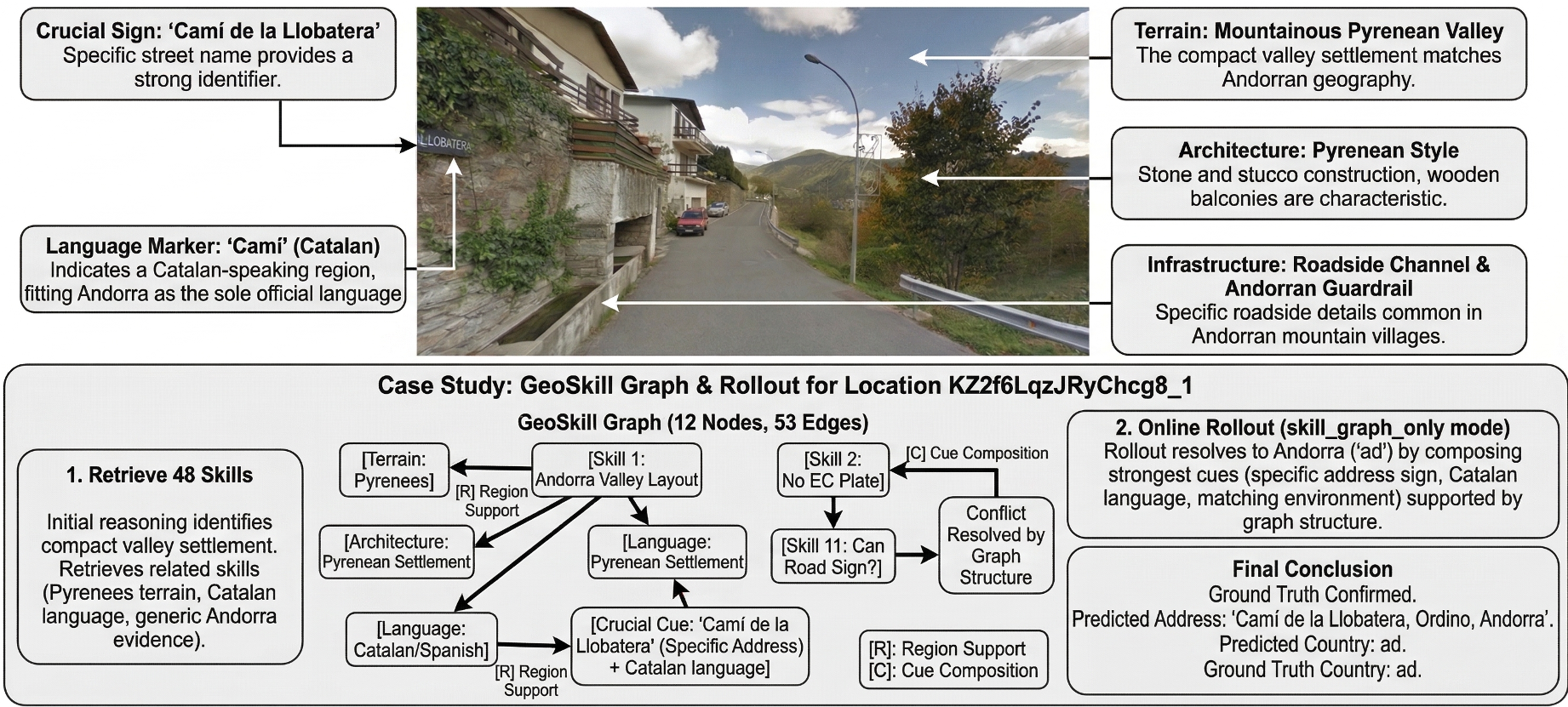 图2:GeoSkill 解题过程:通过技能约束成功规避了视觉干扰项
图2:GeoSkill 解题过程:通过技能约束成功规避了视觉干扰项
深度洞察与总结
核心价值(Takeaway): GeoSkill 的成功标志着符号化 Agent 在垂直领域的回归。虽然端到端的训练(SFT/RL)是目前的主流,但在地理定位这种对“事实准确性”极度挑剔的领域,维护一套可解释、可审计、可人工修正的技能库可能比单纯增加模型参数更为可靠。
局限性与展望: 目前的瓶颈在于跨模态检索的精度。如果第一步视觉特征解析错误,后续的技能加载可能会产生“南辕北辙”的效果。未来的研究重点将在于如何让“技能库”更好地与图像中的微小细节(如特定植被分布)实现更精准的对齐融合。
引用信息: Yang, C., et al. (2026). Skill-Conditioned Visual Geolocation for Vision-Language Models. ACM Reference.