本文提出了 Skill Neologisms,一种通过在 LLM 词汇表中集成可优化的软标记(Soft Tokens)来扩展模型技能的方法。该方法在不更新模型权重的前提下,实现了新技能的获取、与分布外(OOD)技能的灵活组合,以及多技能间的零次学习(Zero-shot)协作。
TL;DR
研究人员提出了一种名为 Skill Neologisms 的新方法,不再通过修改模型权重来增加功能,而是像人类语言中创造“新词”一样,向 LLM 的词汇表中注入代表特定技能的软标记(Soft Tokens)。这种方法不仅避免了灾难性遗忘,更神奇的是,这些新学到的“技能词”能够与模型原有的技能、甚至互不相识的新技能在零样本(Zero-shot)的情况下完美协作。
背景:为什么现有的微调总是不够好?
在大模型领域,我们经常面临一个权衡:
- 微调(Finetuning/LoRA):训练快成效好,但代价是模型可能会“变傻”,忘掉以前的知识(灾难性遗忘)。
- 提示工程(ICL):安全、不用改模型,但上下文窗口是有限的,而且在处理多步骤、复杂的程序性逻辑时,模型的表现往往差强人意。
本文作者提出了一个深刻的直觉:既然预训练模型本身就具有强大的技能组合能力(Compositionality),我们为什么不直接给每种新技能起个“名字”(软标记),让模型学会如何通过这个名字来调用它体内的计算电路呢?
核心机制:Skill Neologisms
Skill Neologisms 的核心在于两个支柱:技能中心化数据集和词汇层集成。
1. 技术架构
作者将技能(Skill)定义为一种程序性知识。在训练时,模型参数 被完全冻结。开发者只需为新技能 初始化一组可学习的软向量 。
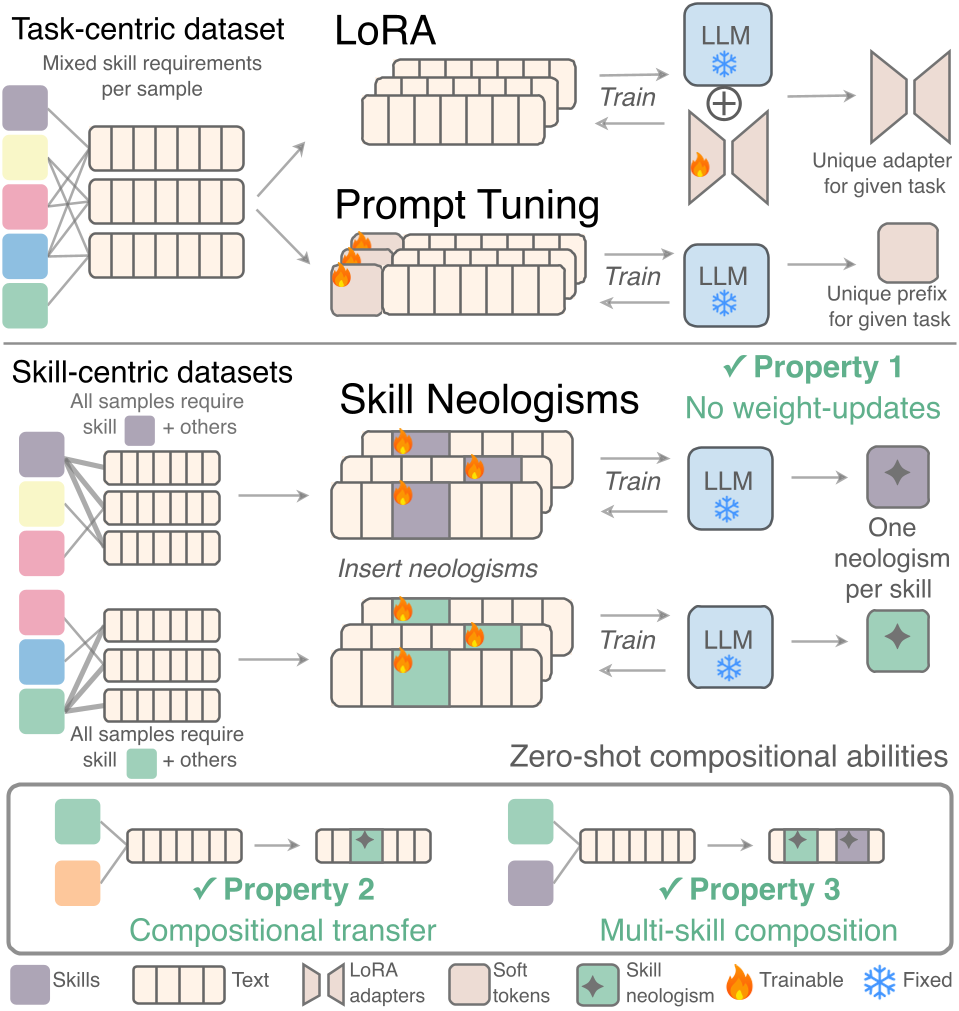
- 注入方式:通过
insertion function将[Skill Token]插入到提示语中,例如:将原本的指令“请排序”替换为“利用[SORT_SKILL]标记来排序”。 - 低参数启发:由于只优化几十个 Token 的向量(相比 LoRA 的数百万参数),模型被迫学习更加泛化、而非过拟合的技能表示。
实验发现:LLM 里的“隐藏开关”
有趣的是,作者首先在现成的模型(如 Llama-3, Phi-4)中发现:某些词汇(如 "XOR")天然地就像一个技能开关。只要在提示中提到这个词,模型执行逻辑运算的准确率会直线飙升,甚至超过了详细的自然语言描述。这证明了词汇级干预直接触达了模型的程序化电路。
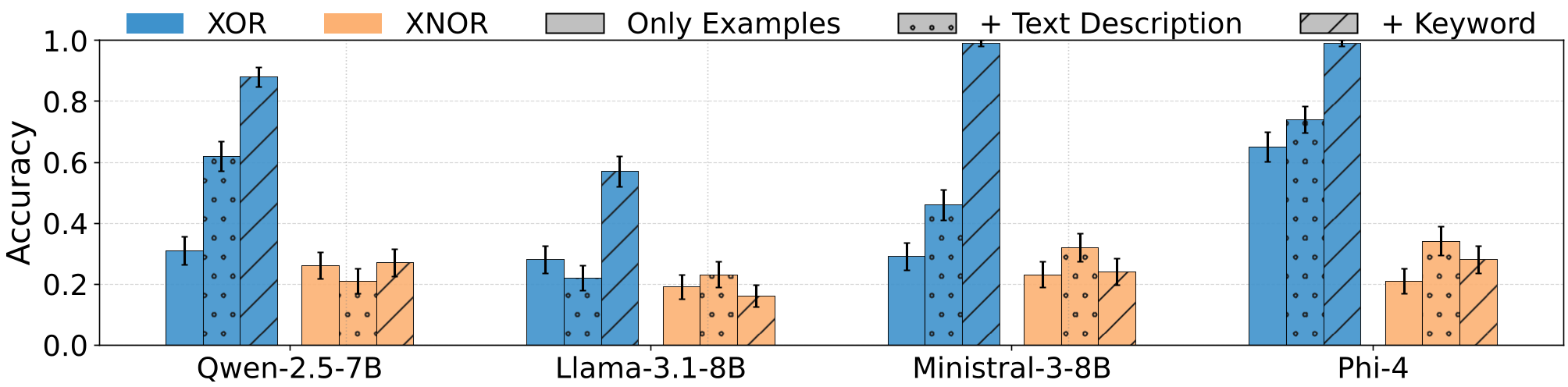
核心能力验证
作者在复杂的数字变换任务(涉及排序、加减、反转等多种技能组合)上验证了 Skill Neologisms 的两个关键属性:
P2:分布外迁移 (OOD Transfer)
当模型学习一个新技能(如:循环移位 SHIFT)后,能否直接与从未在训练中一起出现的原有技能(如:求极性 POL)配合? 结果显示,Skill Neologisms 的表现优于传统的 Prompt Tuning。
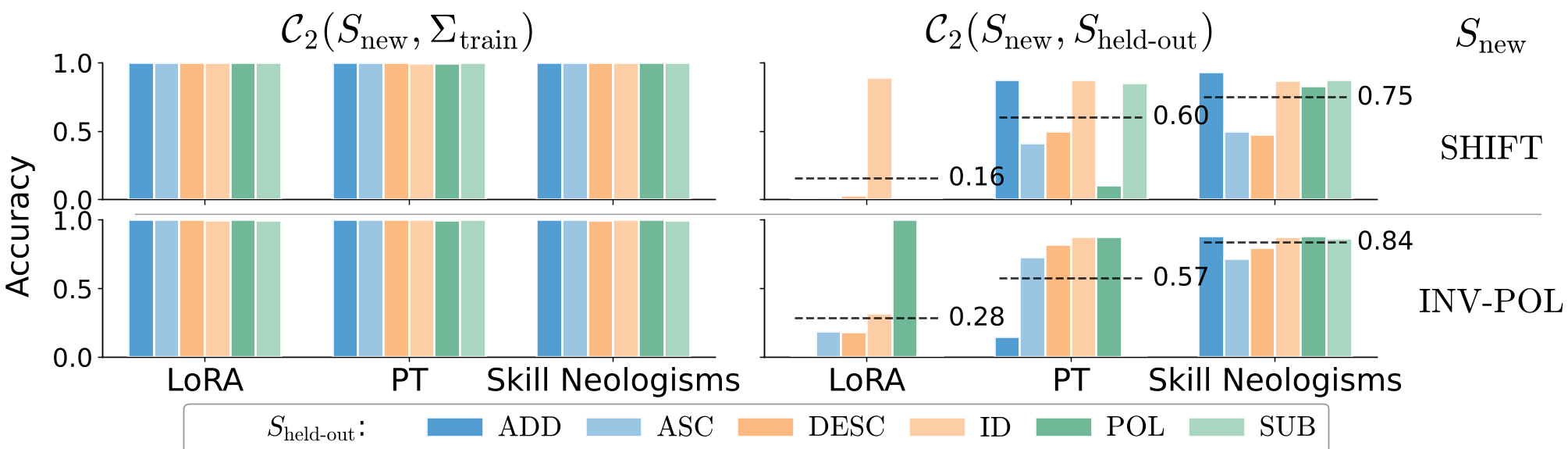
P3:多技能零样本组合
如果分别训练了“技能 A”和“技能 B”的软标记,能否直接把它们一起丢进 Prompt? 实验证明,Skill Neologisms 的零样本组合能力显著超过了 In-context Learning(ICL),在高难度任务下表现极其稳健。
深度洞察:约束即自由
论文中一个极具启发性的结论是:技能软标记的长度(Token Length)并不是越长越好。 实验中,当 Token 长度增加到 200 以上时,OOD 泛化性能反而下降。这意味着,通过限制参数容量,实际上是给模型施加了一个 感纳偏置 (Inductive Bias),强制其学习通用的技能逻辑,而不是死记硬背训练集的分布。
总结与未来
Skill Neologisms 为我们展示了另一种持续学习的可能:模型不再是需要被不断重写的硬盘,而是一个拥有强大预存能力的解释器。我们只需要不断扩充它的词汇库(Vocabulary),为每一个新技能精准“建档”。
局限性:目前该研究主要集中在定义明确的算法任务上。如何在语义更加模糊、开放的自然语言任务中精准提取“技能中心化数据集”,将是迈向工业化应用的下一个挑战。