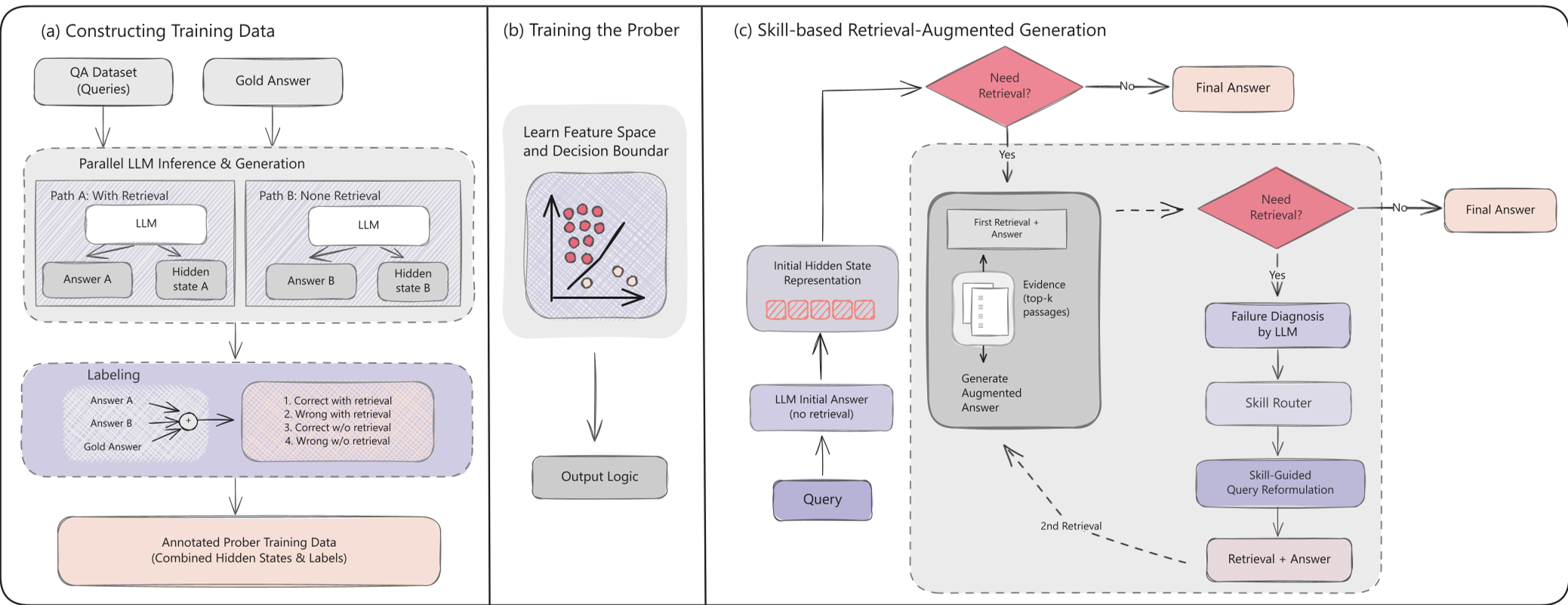
Skill-RAG is a failure-aware Retrieval-Augmented Generation (RAG) framework that introduces a hidden-state prober and a prompt-based skill router to diagnose and rectify query-evidence misalignment. By categorizing post-retrieval failures into specific "skills" like rewriting or decomposition, it achieves state-of-the-art performance, particularly on out-of-distribution (OOD) complex reasoning benchmarks.
TL;DR
Existing Retrieval-Augmented Generation (RAG) systems are often "blind" to why they fail. When they can't find an answer, they simply try again—often leading to the same mistakes. Skill-RAG changes this by introducing a diagnostic layer. By "probing" the model's internal hidden states, it detects why a retrieval step failed and selects a specific "skill" (like rewriting the query or breaking down a complex question) to fix the root cause. This approach results in a massive 13.6% accuracy boost on complex, out-of-distribution reasoning tasks.
The Motivation: The "Blind Spot" of Iterative Retrieval
Most current RAG research focuses on when to retrieve (Adaptive RAG) or how many times to retrieve (Iterative RAG). However, they treat the retrieval process as a black box.
If the first retrieval fails because the query was too vague, a second retrieval with the same context often results in Query Drift, where the model wanders off-topic. The authors of Skill-RAG observed that failures aren't just random luck; they are structural misalignments between what the model needs and what the retriever can see.
Methodology: Probing and Routing
Skill-RAG operates through a sophisticated two-stage pipeline:
1. Hidden-State Probing
Instead of relying on token probabilities (which can be unreliable), the authors train a lightweight Feed-Forward Network (FFN) to look at the LLM's hidden states. This "Prober" determines if the model's current state is "sufficient" to answer or if it's in a "failure state."
2. The Skill Router
Once a failure is detected, the Skill Router (a prompt-based diagnostic tool) chooses the best surgical intervention:
- Query Rewriting: For when the surface form doesn't match the corpus.
- Question Decomposition: For multi-hop logic that needs to be broken down.
- Evidence Focusing: For narrowing down broad searches to specific slots.
- Exit: To stop wasting compute when the information is truly missing.
Empirical Evidence: Geometry of Failure
One of the most profound insights of this paper is the Failure Representation Space Analysis. Using t-SNE visualizations, the authors proved that different types of failures actually cluster together in the model's internal geometry.
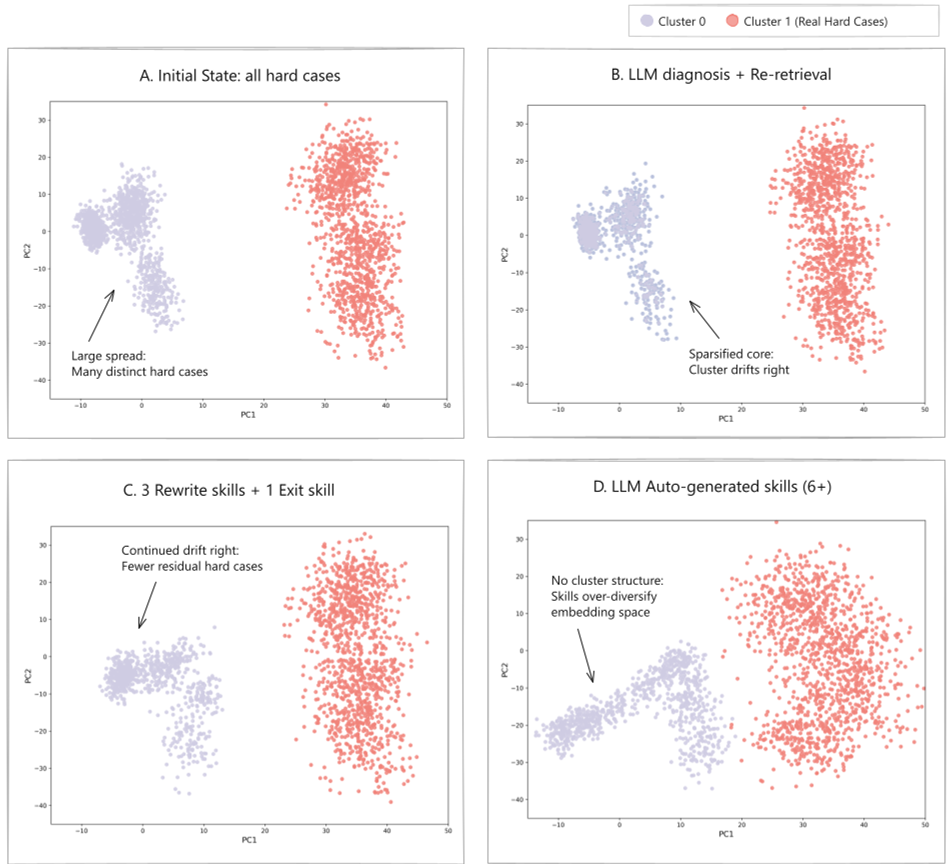
- Cluster 0: Represents fixable alignment gaps.
- Cluster 1: Represents irreducible failures (missing knowledge). As the model applies the "skills," the fixable cluster systematically shrinks, proving that the skills are effectively moving the model out of the failure zone.
Key Results
Tested on the Gemma2-9B backbone, Skill-RAG showed its real strength in Out-of-Distribution (OOD) scenarios—the ultimate test for any AI:
- Accuracy Boost: +13.6% on the 2WikiMultiHopQA dataset.
- Efficiency: Early termination via the prober prevents unnecessary "Round 3" retrievals, saving inference costs.
Critical Analysis & Conclusion
The Takeaway: Skill-RAG represents a shift from quantitative retrieval (more data) to qualitative retrieval (better alignment). It treats the LLM's internal states as a diagnostic dashboard.
Limitations: Currently, the router relies on prompting, which might struggle with smaller, less capable models. Furthermore, the four-skill taxonomy—while elegant—might need expansion for specialized domains like legal or medical research.
Future Outlook: The discovery that failure modes have a "geometric signature" opens the door for training smaller, specialized models that can automatically correct themselves without expensive multi-turn prompting. Skill-RAG is a major step toward making RAG systems truly self-aware and robust.