本文推出了 SkillLearnBench,这是首个专门用于评估大语言模型(LLM)智能体在真实任务中“持续学习”技能生成能力的基准测试。该基准涵盖 15 个子领域的 20 个验证任务,通过对比 One-Shot、Self Feedback 等四种持续学习方法,揭示了自动生成技能与人类专家水平之间的显著差距。
TL;DR
随着大语言模型智能体(LLM Agents)在复杂任务中的应用,**“技能”(Skills)**已成为连接模型能力与定制化工作流的事实标准。然而,当智能体遇到从未见过的新任务时,它能否通过经验自我进化出新技能?卡内基梅隆大学(CMU)与亚马逊 AGI 团队推出的 SkillLearnBench 填补了这一领域的空白。研究发现:生成的技能虽强,但仍不及人类专家的“神来之笔”,且过度依赖自我反馈会导致严重的性能退化。
痛点深挖:为什么 Agent 很难“自学成才”?
在现有的 Agent 框架中,技能通常是预定义的 Markdown 文档或代码块。但在真实的持续学习背景下,Agent 必须具备 Generate-Store-Reuse(生成-存储-复用)的能力。
作者指出,目前的自动技能生成面临三大痛点:
- 鲁棒性缺失:针对单个实例生成的技能,换个参数就失效(Overfitting)。
- 执行偏差:生成的技能描述很丰满,但 Agent 在执行时往往“视而不见”或是“会错意”。
- 递归漂移:在没有外部干预的情况下,Agent 越改越偏(Self-revision Drift)。
方法论详解:三位一体的评估框架
为了拆解 Agent 在学习过程中的具体表现,SkillLearnBench 设计了严密的评估漏斗:
1. 架构解析
评估从三个维度展开:
- Level 1: Skill Quality(静态评估):通过 LLM Judge 检查生成的文档是否涵盖了解决任务的 Key Points。
- Level 2: Trajectory Analysis(动态过程):观察 Agent 的轨迹是否与 Oracle(专家轨迹)对齐。
- Level 3: Task Outcome(最终战绩):验证任务是否真正通过。
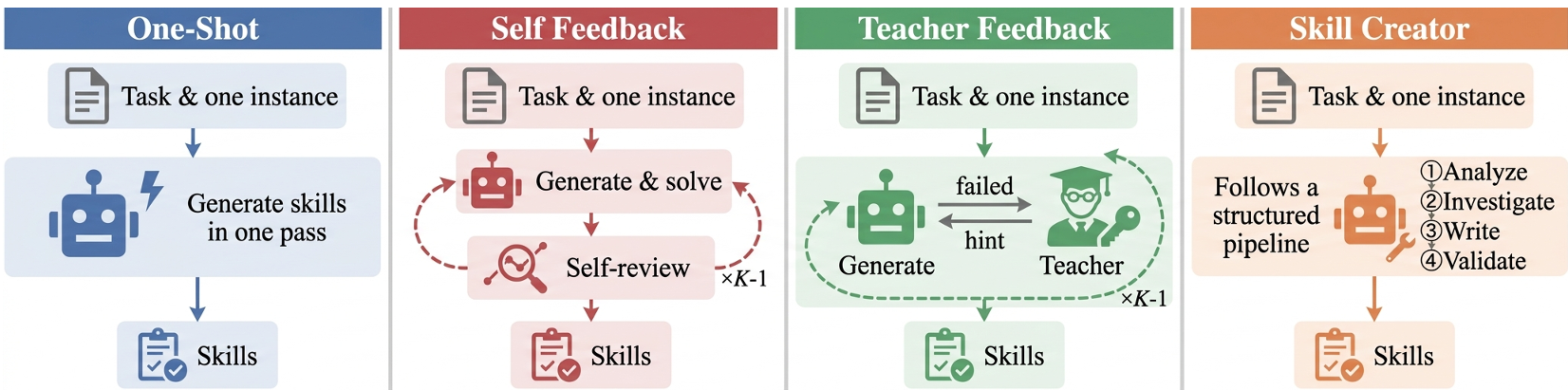 图 1:四种持续学习方法的对比工作流:One-Shot, Self Feedback, Teacher Feedback, 和 Skill Creator
图 1:四种持续学习方法的对比工作流:One-Shot, Self Feedback, Teacher Feedback, 和 Skill Creator
实验与结果:残酷的现实
研究评估了包括 Claude 4.5 和 Gemini 3.1 在内的多款顶级模型。
核心发现 1:方法论的局限
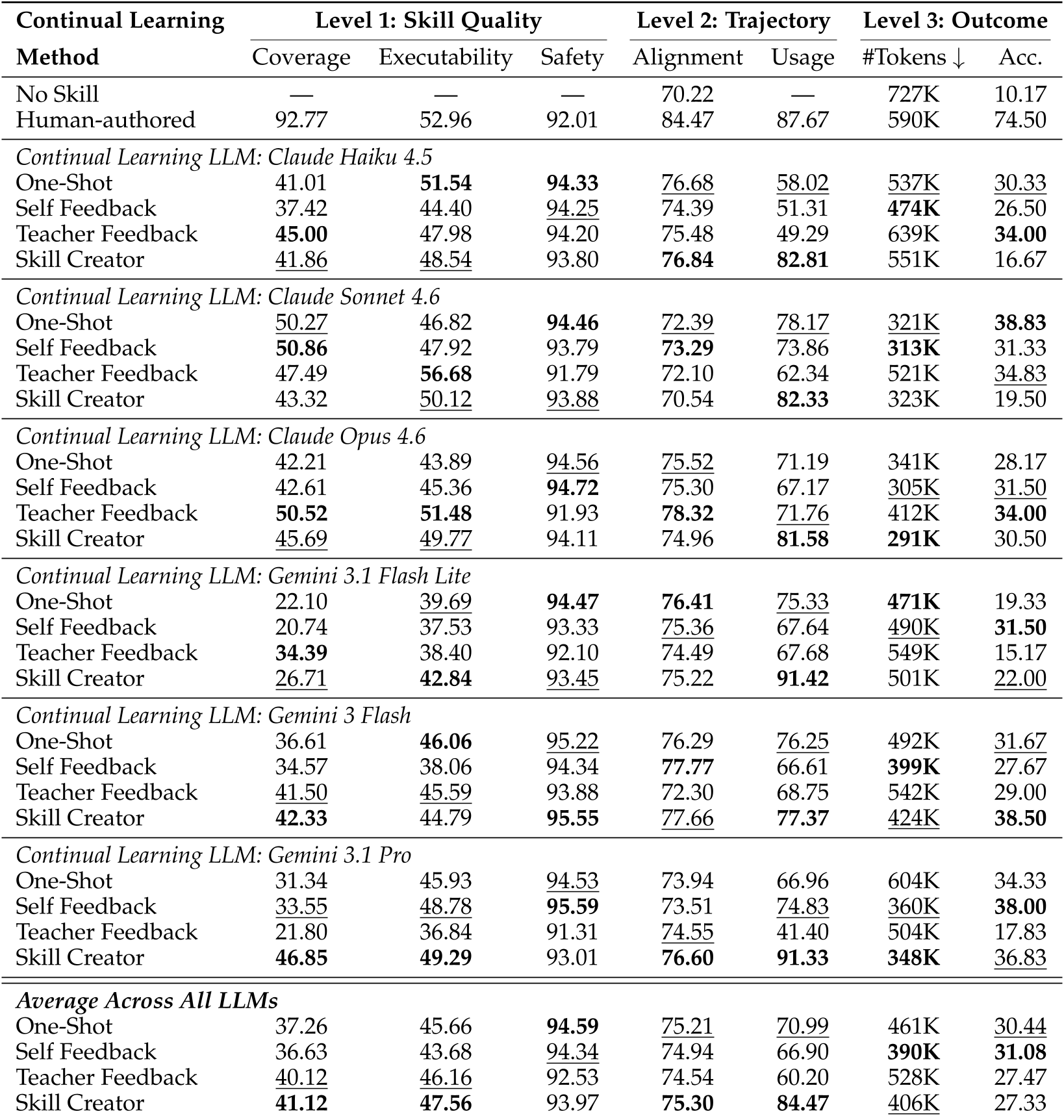
即便采用了复杂的 Skill Creator 管道,其平均表现甚至在某些任务中不如简单的 One-Shot 生成。实验结果显示,人类编写的技能(Human-authored)在 Level 3 的准确率可达 74.5%,而生成的最高水平仅在 30% 左右徘徊。
核心发现 2:自我修正的伪命题
论文的一个深度洞察是:Self Feedback(自我反馈)在多轮迭代后会失效。
- Self Feedback:覆盖率(Coverage)在多轮后持平,但对齐度下降,准确率在短暂上升后暴跌。
- Teacher Feedback:由于引入了外部专家信号,覆盖率和对齐度随轮次稳步提升。
这警示我们,闭环的自我迭代无法产生新知识,只会不断放大初始的偏见。
核心发现 3:模型规模不是万灵药
有趣的是,从 Haiku 升级到 Opus 或者从 Flash 升级到 Pro,技能生成的质量并没有显著的线性提升。强模型倾向于生成更**硬编码(Prescriptive)**的指令,这在处理多变的实际任务时反而降低了复用性。
深度洞察与总结
SkillLearnBench 的出现为智能体领域泼了一盆冷水,也指明了方向。
- 总结:生成有效技能的关键不在于文档的华丽程度,而在于其可执行的逻辑支撑(如 Case 3 中提到的 RMSE 计算支持)。
- 局限性:目前的生成方法大多局限于文本描述(Pattern A),缺乏对脚本(Pattern B)或子代理调用(Pattern C)的深度结合。
- 未来展望:未来的持续学习 Agent 需要更强的“环境感知”反馈,而非仅仅是基于文本的“自我感觉良好”。
对于开发者而言,这篇论文的启示是:如果你想让 Agent 具备持续进化的能力,请务必给它配一个“外部验证器”或“人类导师”,而不是让它在死胡同里自我反思。