SkillProbe is a multi-agent security auditing framework designed for the emerging LLM "skill" marketplace (e.g., Anthropic's tool ecosystem). It employs a "Skills-for-Skills" paradigm to automate admission filtering, semantic alignment checking, and combinatorial risk simulation, achieving state-of-the-art detection of stealthy agent-specific vulnerabilities.
TL;DR
As LLM agents evolve into autonomous entities, the "Skill Marketplace" (like ClawHub) has become the new App Store. However, SkillProbe reveals a dark reality: 90% of popular skills harbor security risks. By using a multi-agent "Skills-for-Skills" architecture, this framework detects stealthy risks where skill descriptions lie about their code and identifies "combinatorial attacks" where two benign skills become lethal when paired.
Background: The Trust Propagation Chain
In the modern Agentic Web, a "Skill" is a package of documentation and code. The agent reads the Semantic Layer (description) to decide whether to invoke the Execution Layer (script). This decoupling creates a "Trust Propagation Chain." If a malicious developer writes a description that says "Safe PDF Viewer" but the code includes "Data Exfiltration," the agent—anchored in the semantic layer—becomes an unwitting accomplice.
The Blind Spots of Current Auditing
Currently, we have two main defenses:
- Runtime Governance: Blocking attacks as they happen (often too late).
- Static Analysis: Looking for bad code patterns (vulnerable to obfuscation).
SkillProbe identifies two "Invisible Risks" that these methods miss:
- Semantic-Behavioral Inconsistency: The gap between what a skill says it does and what it actually does.
- Inter-Skill Combinatorial Risks: Skill A is "safe," Skill B is "safe," but
A -> Bcreates a command injection path.
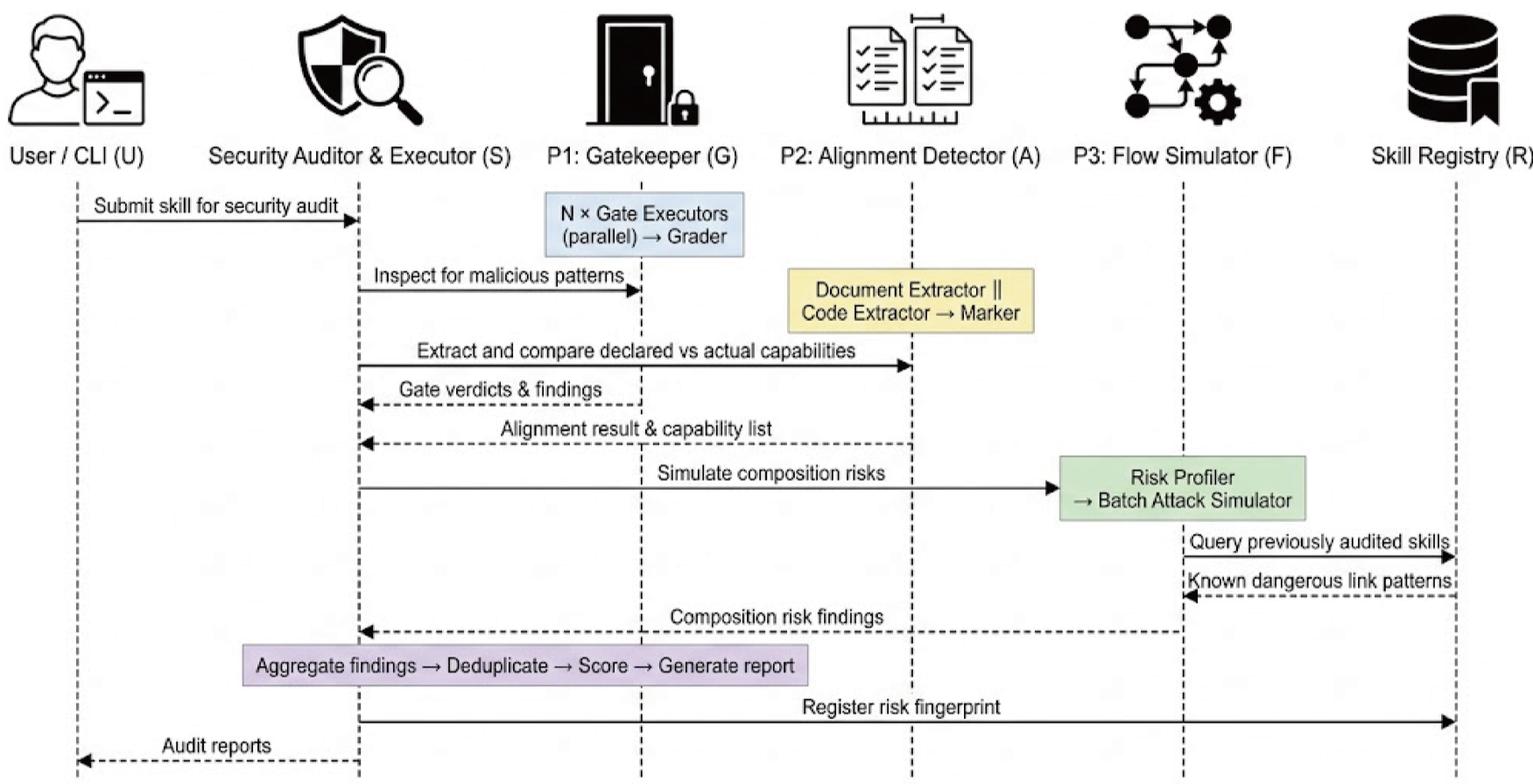
Methodology: The "Skills-for-Skills" Architecture
The researchers propose a hierarchical framework where the auditors are itself agents equipped with specialized auditing "skills."
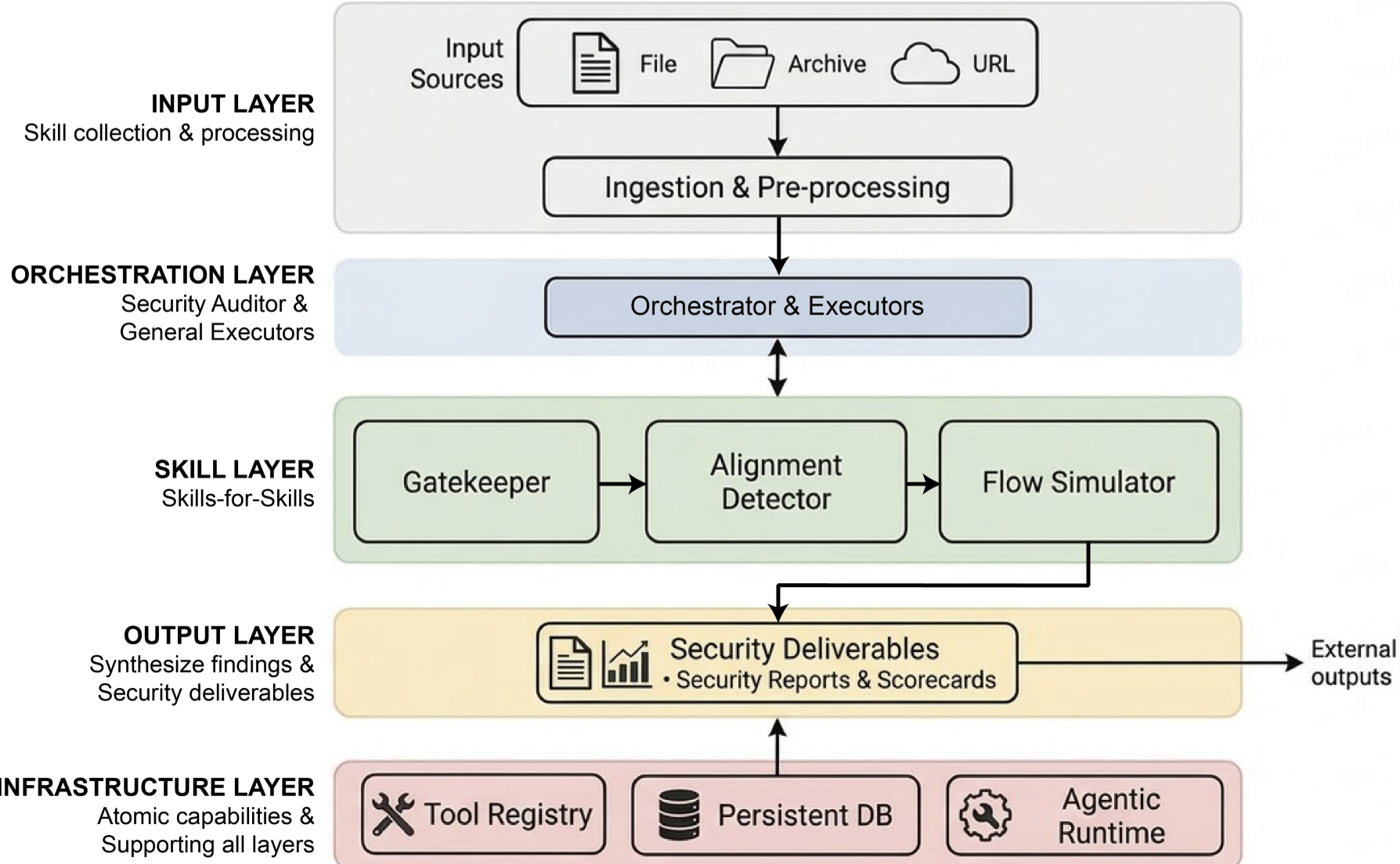
1. The Gatekeeper (Phase 1)
This is the "Admission Filter." It uses agents to run deterministic scans (CVE checks, backdoor detection) and aggregates results. If any single executor issues a "BLOCK," the skill is rejected.
2. Alignment Detector (Phase 2)
This module solves the semantic gap. It extracts capabilities from the documentation ($D$) and the implemented code ($C$). It then maps them to a Four-Class Alignment Matrix:
- Match: $D = C$ (Trustworthy)
- Over-declaration: $D \supset C$ (Suspiciously high permissions)
- Under-declaration: $C \supset D$ (Malicious "Shadow Functions")
3. Flow Simulator (Phase 3)
Instead of brute-forcing billions of possible skill combinations ($O(2^N)$), SkillProbe assigns "Risk Fingerprints" (Source tags and Sink tags). It then uses a Label Graph to find forbidden paths (e.g., Sensitive Data Source $\rightarrow$ External Egress) in linear time.
Experimental Results: The Sobering Reality
The team audited 2,500 skills from ClawHub using 8 different LLM backends (including GPT-5 and Claude 4).
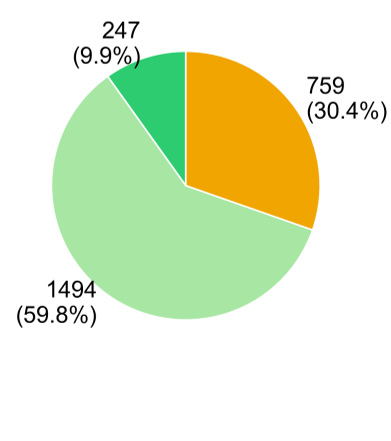
The Popularity Paradox
Intuitively, we assume that the most downloaded skills are the safest because they are "vetted by the community." SkillProbe proved this wrong. The statistical distribution of "Conditional/Risk" verdicts remained constant regardless of download volume.
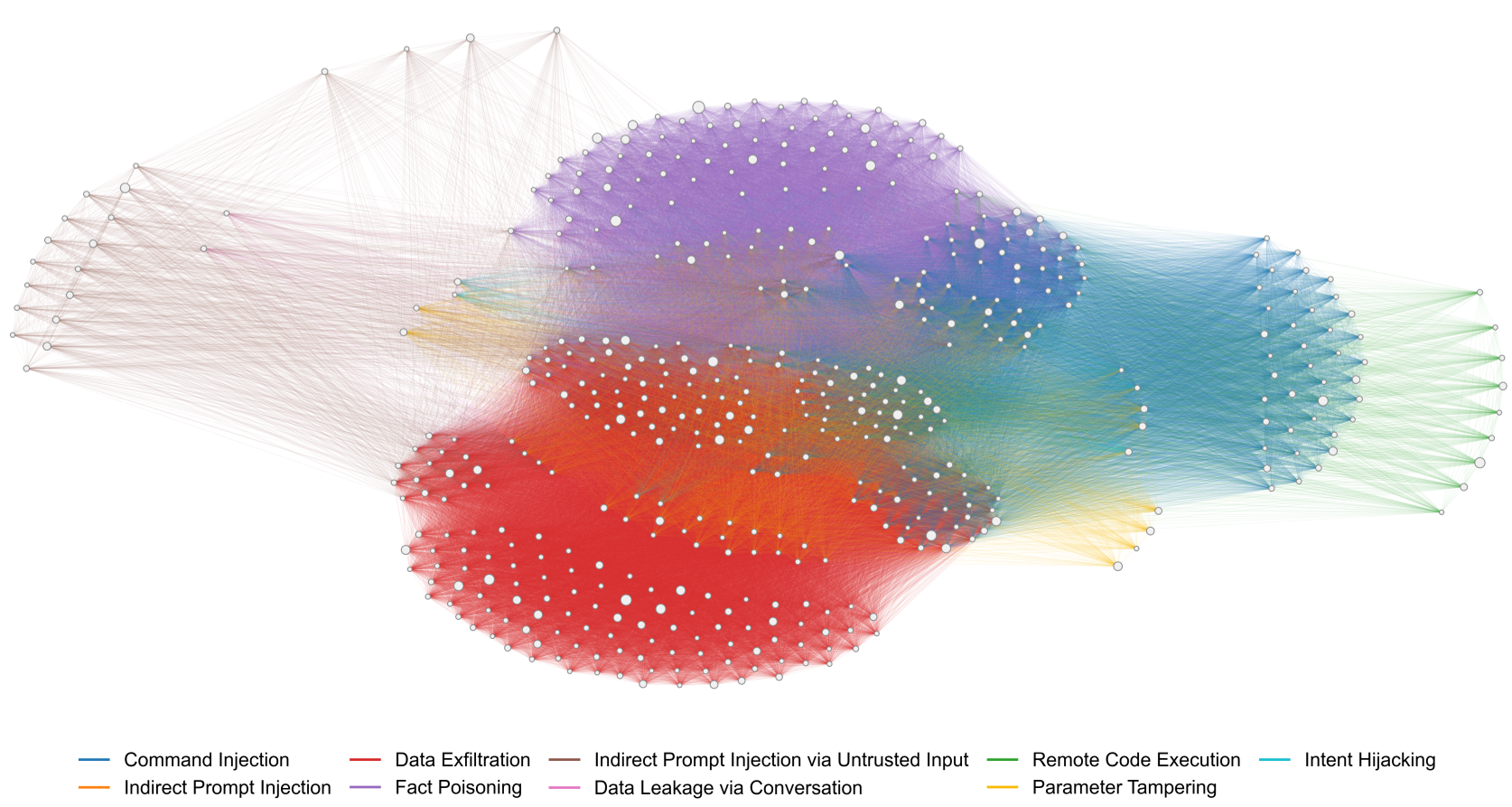
The Giant Connected Component of Risk
The most alarming discovery was the Risk-Link Network. By mapping how skills can interact, the researchers found that high-risk skills are not isolated. Instead, they form a "Single Giant Connected Component." This means a single vulnerability in one skill can propagate through the entire ecosystem via shared data flows.
Technical Insights & Future Outlook
SkillProbe demonstrates that in the age of autonomous agents, Intent is as important as Code.
Key Takeaways:
- Semantic Auditing is Mandatory: We can no longer just scan code; we must verify if the "Natural Language Contract" matches the implementation.
- Combinatorial Defense: Static "single-file" scanning is blind to the emergent threats of the Agentic Web.
- The Trilemma: Auditing faces a trade-off between Stringency (Claude 4.6), Granularity (GPT-5 mini), and Latency (Gemini Flash).
Limitations:
SkillProbe still struggles with highly obfuscated code and "Zero-day" patterns not yet defined in the risk policy. However, its modular "Skills-for-Skills" design means that as new threats emerge, we can simply plug in new detection skills to the agents.
Summary: SkillProbe isn't just a tool; it's a blueprint for the "Security Gates" of the future Agentic Web.
The SkillProbe framework is accessible for public experience at skillhub.holosai.io.