本文提出了 SkillProbe,这是一个专为 LLM Agent 技能市场设计的自动化多智能体安全审计框架。该框架采用“以技能审计技能(Skills-for-Skills)”的范式,通过准入过滤、语义-行为一致性检测及组合风险仿真三个阶段,成功在 ClawHub 市场的 2,500 个真实技能中发现了大量零日漏洞,实现了对复杂 Agent 生态的系统级治理。
TL;DR
随着 LLM Agent 步入“App Store 时代”,技能市场(Skill Marketplace)如雨后春笋般涌现。然而,上海交大与上海创新研究院等机构的最新研究 SkillProbe 敲响了警钟:在对主流市场 ClawHub 的 2,500 个技能进行审计后发现,超过 90% 的热门技能存在安全隐患。研究指出,下载量不仅不能代表安全性,且高风险技能已织成了一张互联的“暗网”,随时准备在多 Agent 协作时爆发级联攻击。
背景定位:Agent 生态的“信任链”断裂
在当前的 Agentic Web 中,技能(Skill)被封装为文档、配置和脚本的集合。LLM 凭借自然语言描述(Semantic Layer)来决定是否调用某个技能,而实际执行则发生在底层脚本(Execution Layer)。
这种语义与执行的解耦催生了两个致命的黑盒:
- 语义-行为不一致 (Semantic-Behavioral Inconsistency):描述写着“天气查询”,代码里却藏着“读取私钥”。
- 组合风险陷阱 (Combinatorial Risks):两个看起来人畜无害的技能(例如:一个负责读取邮件,一个负责发送 HTTP 请求),一旦链式调用,就可能演变为数据外泄的重灾区。
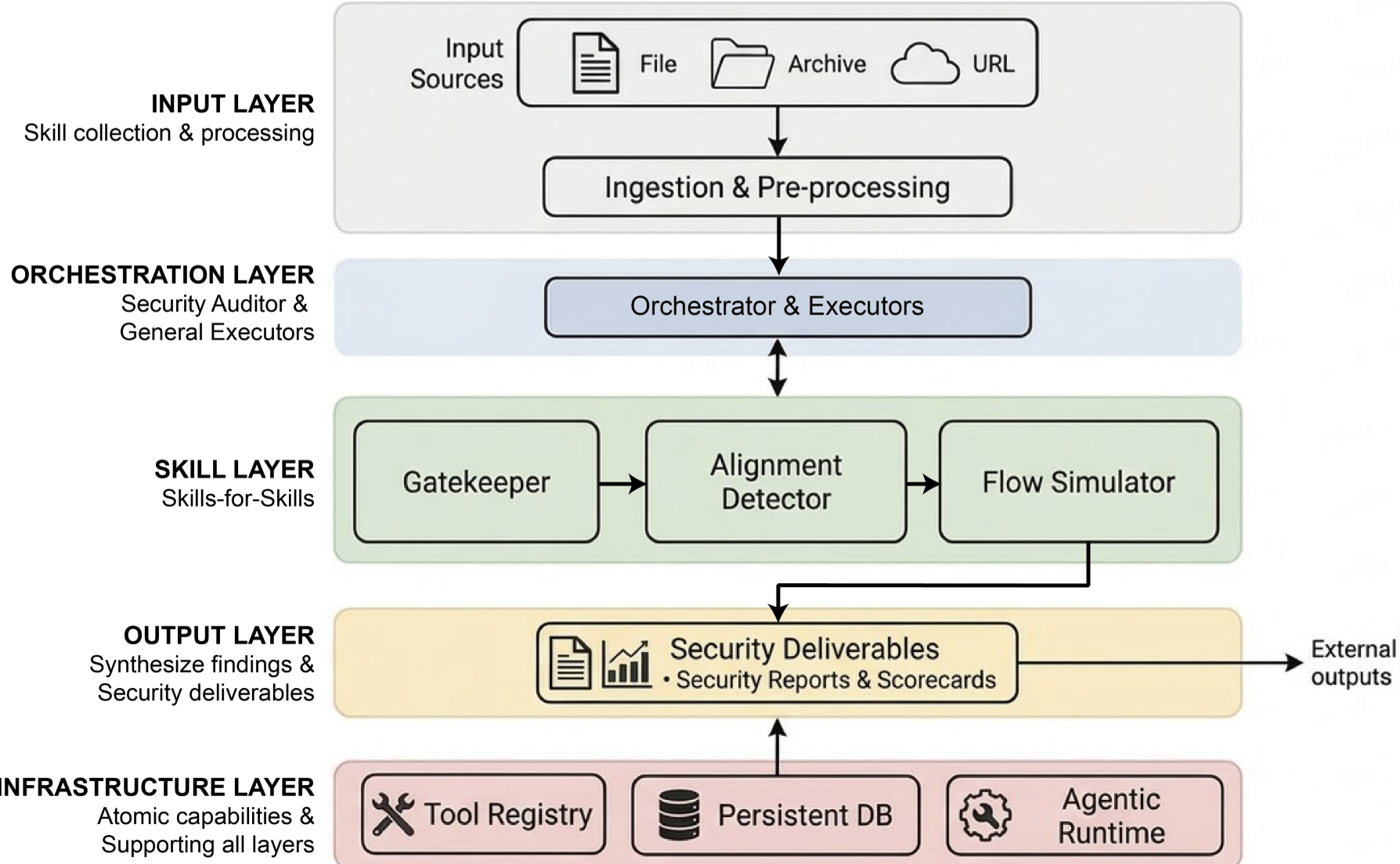
核心机制:Skills-for-Skills 的多智能体协作
为了应对这些复杂威胁,SkillProbe 提出了“以子之矛攻子之盾”的方案,将审计流程模块化为特定的技能。
1. 三阶段审计流水线
- Gatekeeper (准入过滤):扫描已知 CVE 漏洞、恶意代码模式和权限声明的合理性。
- Alignment Detector (一致性检测):这是本文的核心 Insight。它通过 AST 分析和 LLM 推理,构建 D(文档声明)与 C(代码实现)的映射,将其归类为“包含、匹配、越权、交叉”四种状态。
- Flow Simulator (组合仿真):利用风险标签图(Label Graph),将组合风险搜索从 的暴力搜索优化为 的线性检查。
实验发现:流行度悖论与风险暗网
研究团队调用了包括 Claude 4.5、GPT-5 系列在内的 8 种顶级 LLM 作为审计引擎,对 ClawHub 进行了大规模“体检”。
1. 严格的审计者:Claude 4.6 Sonnet
在跨模型评估中,Claude 4.6 Sonnet 被证明是最“挑剔”的审计员,不仅发现漏洞多,且给出的修复建议最为详实。而 Gemini-Flash 则表现出了极高的处理速度(平均 18.5 秒),适合初筛。
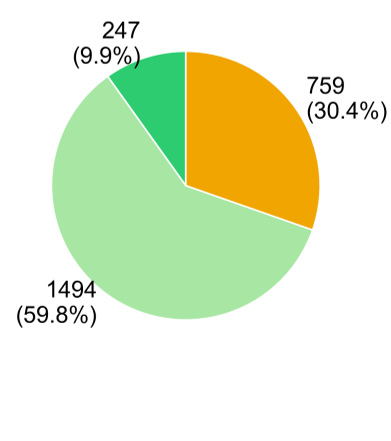
2. 流行不等于安全
这是该研究最震撼的结论:下载量排名前 100 的技能中,潜在风险的比例与“长尾”技能几乎一致。 这种“流行度悖论”说明,当前的 Agent 市场严重缺乏准入监管,用户正在“裸奔”。
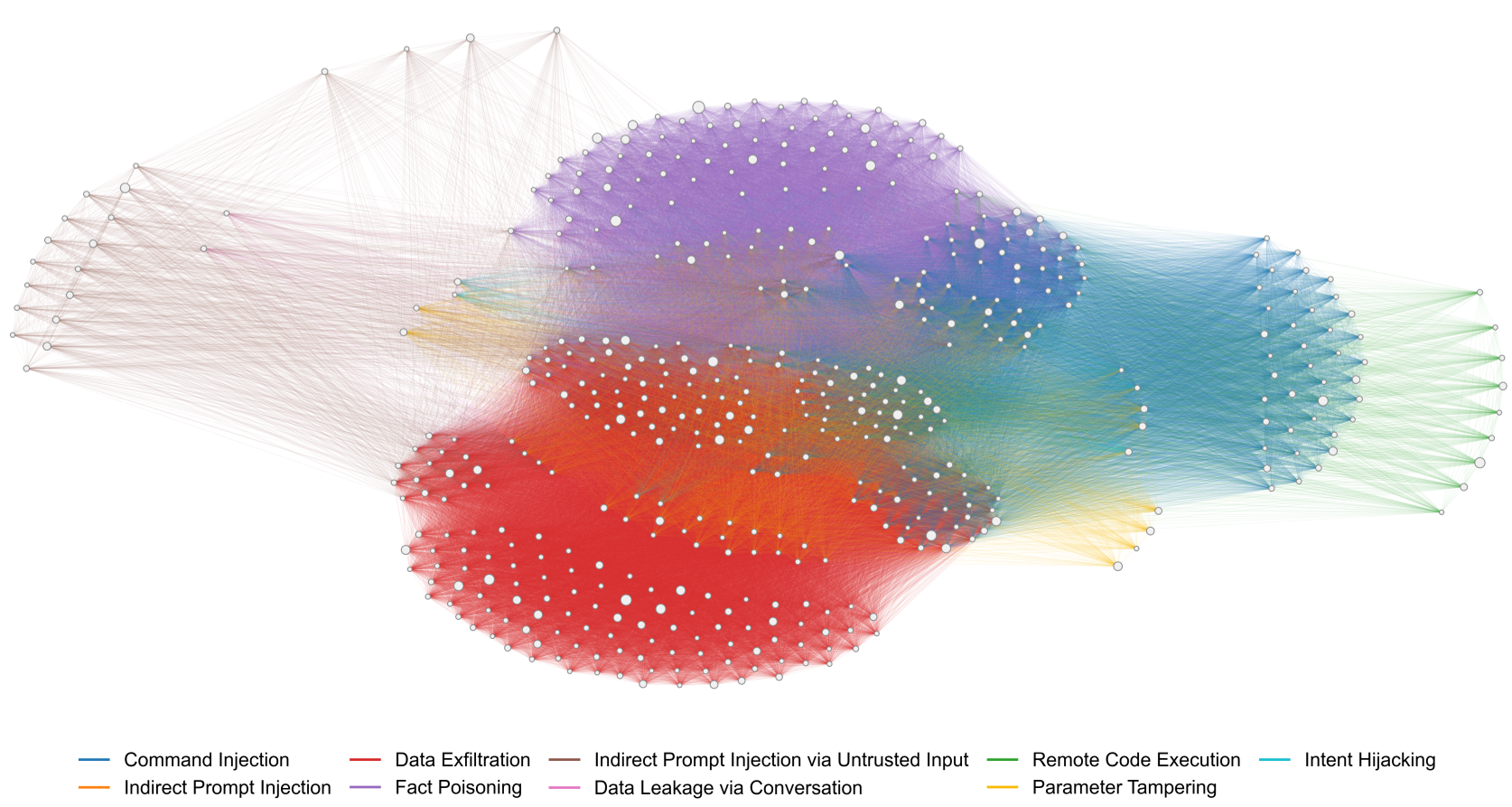
3. 系统性崩溃:全连通的风险网络
通过对 499 个高危技能进行建模,作者发现这些技能在风险特征上构成了一个 “巨大连通分量”。这意味着,只要攻击者巧妙地串联这些技能,就可以在整个 Agent 环境中实现指令注入、隐私数据提取和事实投毒。
深度洞察:从“代码审计”到“意图审计”
SkillProbe 的价值在于它揭示了 Agent 安全的一个范式转移:安全边界不再仅仅是逻辑漏洞,更是语义偏差。
- 对于开发者:必须严格约束 SKILL.md 中的能力描述,任何“多领”权力的行为都可能导致技能被下架。
- 对于市场平台:急需引入类似 SkillProbe 的自动化深度扫描器。
- 局限性:目前的框架对于高度混淆的代码或纯黑盒 API 调用仍存在感知深度上限,这需要未来通过动态沙箱(Dynamic Sandboxing)技术进一步突破。
总结
SkillProbe 不仅仅是一个审计工具,它为构建可信的 Agentic Web 提供了治理标准。在 Agent 赋能生产力的今天,这种针对语义与协作的“防御性编程”思维,将成为生态系统赖以生存的基石。
SkillProbe 现已开放公共体验地址:skillhub.holosai.io