The paper introduces SkillRouter, a compact 1.2B-parameter retrieve-and-rerank pipeline designed to select relevant tools (skills) for LLM agents from pools of ~80,000 candidates. It achieves a SOTA 74.0% Hit@1 accuracy, surpassing much larger 8B-parameter models and proprietary embeddings through task-specific fine-tuning.
TL;DR
As LLM agent ecosystems scale to tens of thousands of tools (skills), the bottleneck has shifted from how to use a tool to which tool to pick. SkillRouter is a 1.2B-parameter pipeline that proves metadata is not enough: by focusing on the full implementation "body" of a skill, it achieves 74% top-1 accuracy on a massive 80k-skill benchmark, outperforming models 13x its size.
Background: The Metadata Myth
Current agent architectures (like Claude Code or OpenAI’s GPTs) follow a "progressive disclosure" design. They show the agent only the tool's name and a brief description to save context space. The implicit assumption? That names and descriptions are enough to identify the right tool.
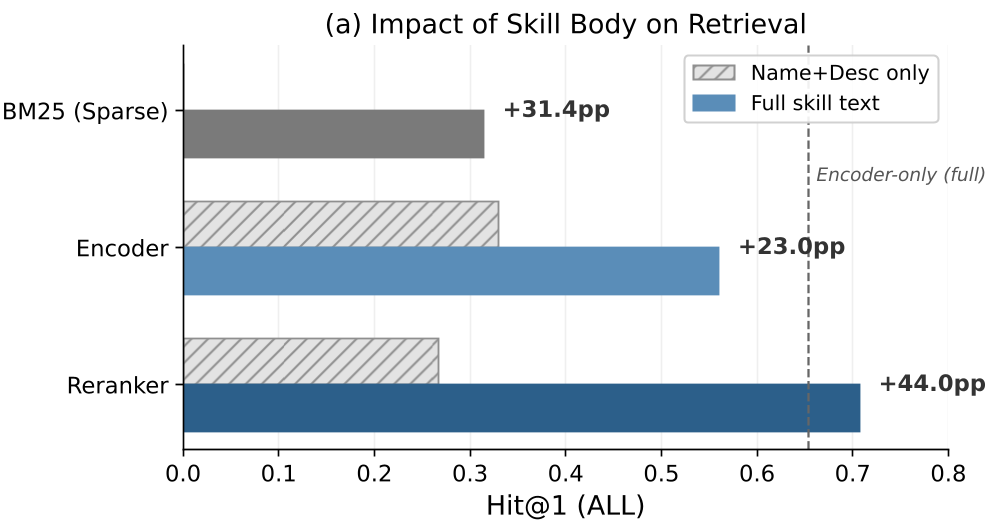
This paper busts that myth. In community-contributed repositories, functional overlap is rampant. If you have 50 different "Git" tools, their descriptions all look the same. The authors found that removing the implementation "body" causes retrieval performance to collapse by up to 44 percentage points.
Methodology: The Anatomy of SkillRouter
SkillRouter employs a classic two-stage architecture but with two "secret sauces" that make it work at a 1.2B parameter scale:
1. Two-Stage Retrieve-and-Rerank
- Stage 1 (Bi-encoder): A 0.6B model reduces 80,000 skills to the top 20 candidates.
- Stage 2 (Cross-encoder): A 0.6B reranker performs deep cross-attention between the query and the full text of those 20 candidates.
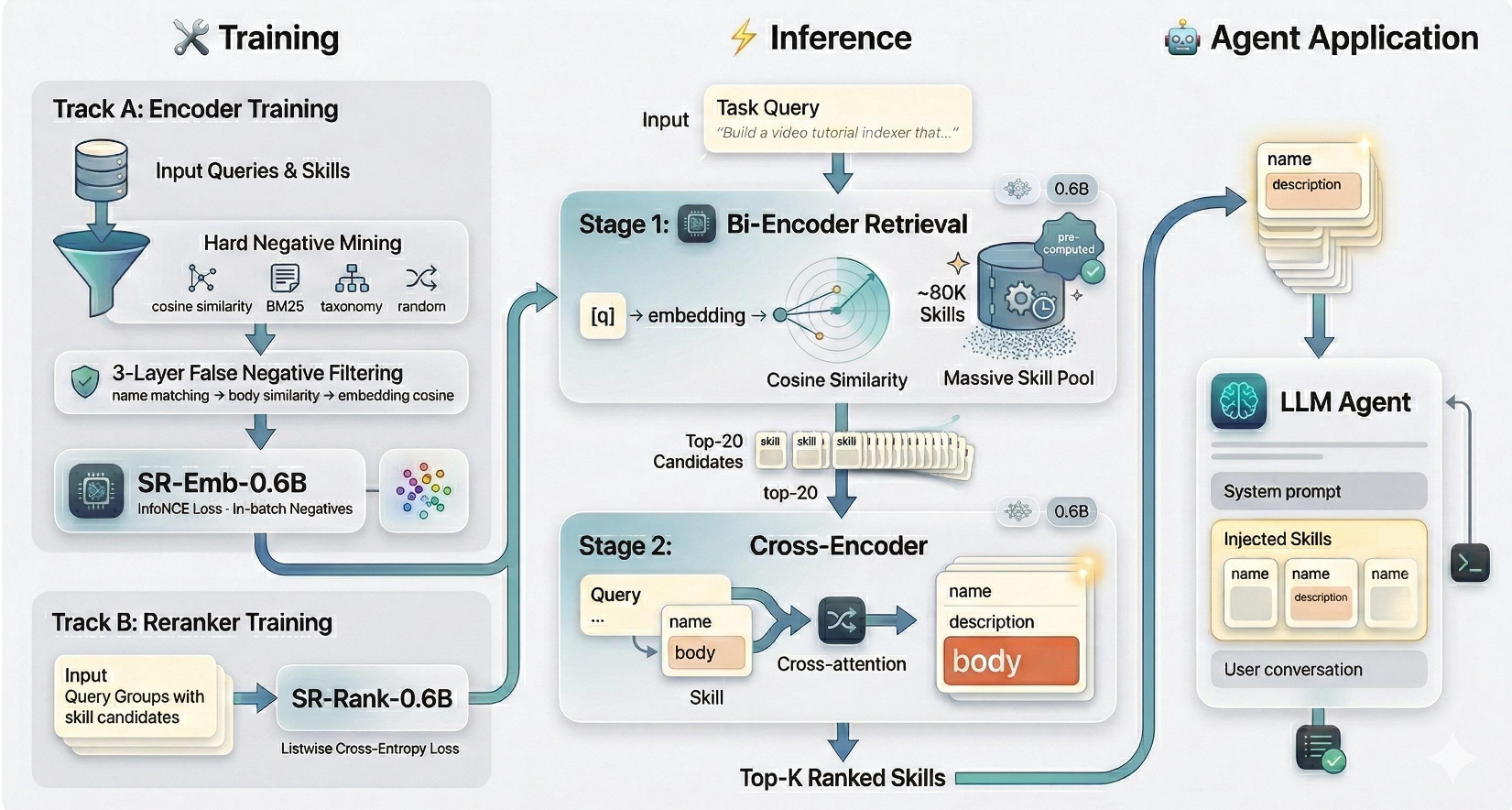
2. The "Body" is Everything
The authors performed an attention analysis on the reranker. The result was staggering: 91.7% of the model’s attention was focused on the skill's body, while the description—the part we usually rely on—received a measly 1.0%.
Key Innovations for Homogeneous Pools
If you are training a model to distinguish between very similar tools, standard training fails. SkillRouter introduces two vital techniques:
- False Negative Filtering: In open-source repos, two skills might do the same thing under different names. If you treat one as a "negative" for the other during training, you confuse the model. SkillRouter uses a 3-layer filter (Name, Jaccard similarity, and Embedding) to purge these "false negatives."
- Listwise vs. Pointwise Loss: Standard rerankers score items one-by-one (pointwise). SkillRouter uses a Listwise Cross-Entropy loss, forcing the model to compare all 20 candidates simultaneously. This "comparative reasoning" is why it handles homogeneous pools so much better than traditional methods.
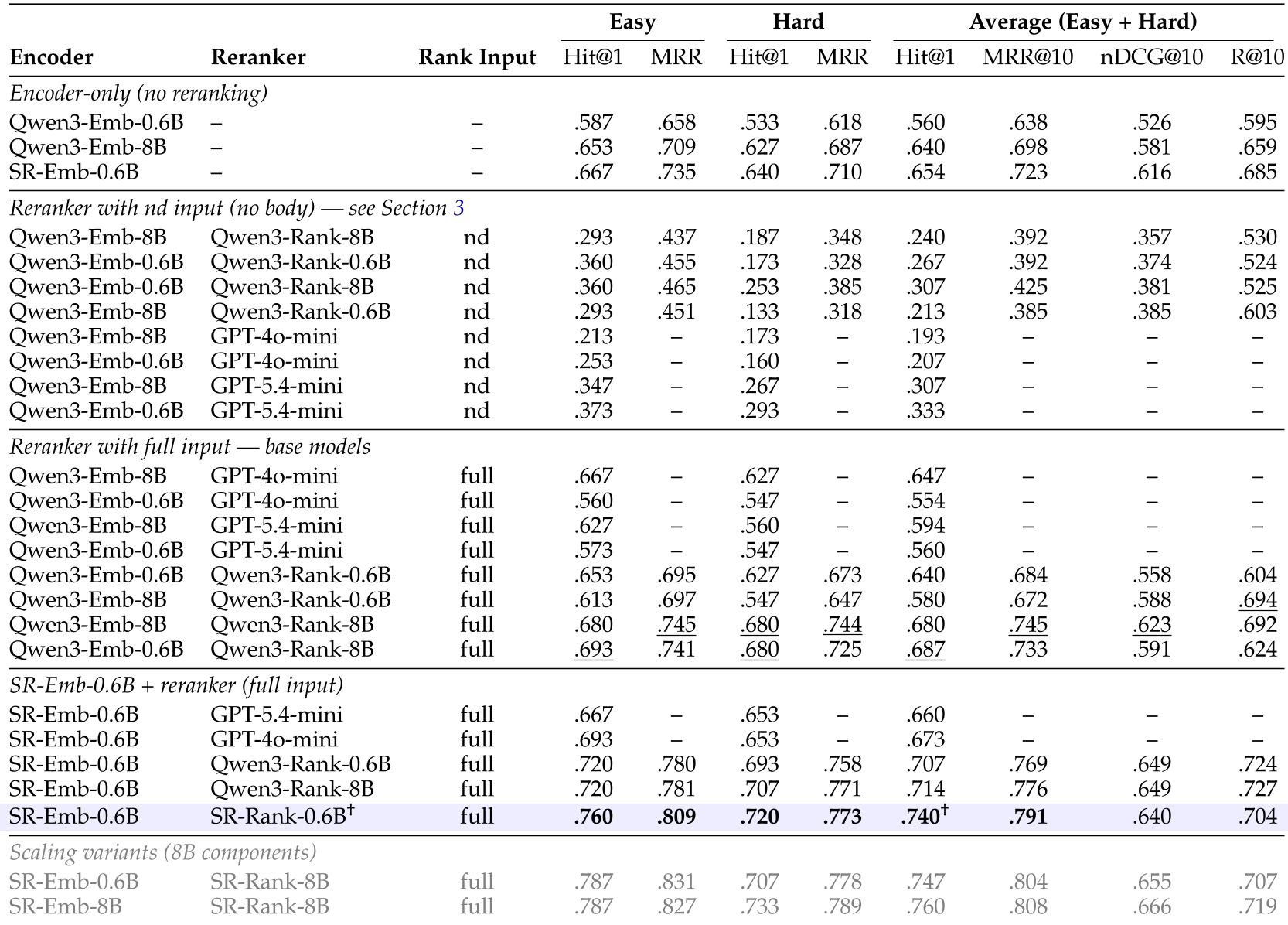
Experiments & Results: Small Model, Big Impact
Despite being only 1.2B parameters, SkillRouter punches way above its weight class:
- SOTA Achievement: 74.0% Hit@1 across 80,000 skills.
- Efficiency: Can be deployed on a laptop CPU, avoiding expensive cloud APIs for "meta-tasks" like skill routing.
- Superiority: Outperforms the Qwen3-8B base model and OpenAI’s text-embedding-3-large.
Critical Insight: The "Hidden-Body" Asymmetry
The most profound takeaway is the Information Asymmetry. The agent cannot see the tool body (it's too long), but the router must see it to make the right choice. This suggests that the "Selector" and the "User" in an AI system should have different perspectives: one focuses on implementation details, the other on execution logic.
Conclusion & Future Outlook
SkillRouter proves that specialized, compact models can outperform generalist giants when provided with the right signals—in this case, the implementation code of the skills themselves. As we move toward local, privacy-first agents, this "router-on-device" approach will be the blueprint for scaling agent capabilities without exploding latency or costs.
Next Step for researchers: Can we use the SkillRouter to synthesize "mini-descriptions" that actually capture the discriminative features of the body, allowing the agent to benefit from that 91.7% attention signal without the context overhead?