本文提出了 SkillRouter,一个专门用于在大规模(约 8 万个)技能库中为 LLM Agent 精确调度工具的“检索+重排序”双阶段框架。该方法通过仅 1.2B 参数的小规模模型组合(0.6B 检索器 + 0.6B 重排器),在 Hit@1 准确率上达到 74.0%,超越了 8B 规模的 Zero-shot 基线及 OpenAI 等商业模型。
TL;DR
在 LLM Agent 生态中,工具(Skills/Tools)动辄上万。传统的做法是给模型看一眼工具的“名字和简介”就让它选,但这在处理复杂任务时几乎是盲投。阿里巴巴的研究团队近日发表论文,指出工具的底层代码实现(Skill Body)才是筛选的唯一真理。他们提出的 SkillRouter 仅用 1.2B 的参数量,就在 8 万个技能的海洋里实现了 74% 的精准命中,吊打 8B 规模的通用模型。
1. 痛点:被忽视的“隐藏体”非对称性
目前的 Agent 架构(如 Claude Code, GPTs)普遍面临一个尴尬:为了省 Token 和计算量,系统只把工具的名称(Name)和简介(Description)塞给模型。这产生了一个隐藏体非对称性(Hidden-body Asymmetry):
- Agent 看到的:名字叫
pdf-merger,简介是“合并 PDF”。 - 逻辑真相(Body):代码里写着它其实只支持带有加密权限的特定 PDF 协议,或者它其实是一个特定的 Python 库封装。
在社区贡献的技能库中,可能存在几十个都叫 pdf-merger 的工具。只看名字,模型根本无法区分哪个才是当前任务的“真命天子”。
2. 核心直觉:Body 才是决定性信号
作者做了一个非常硬核的消融实验(见下表):
- 丢弃 Body:所有主流检索模型(BM25, Qwen, E5)的性能直接崩盘,Hit@1 掉分高达 29-44 个百分点。
- 只看名字/简介:BM25 甚至拿到了 0 分。
- 注意力分析:通过对 Cross-encoder 的可视化发现,模型在做最终决定时,91.7% 的注意力都放在了 Body(代码实现)上。
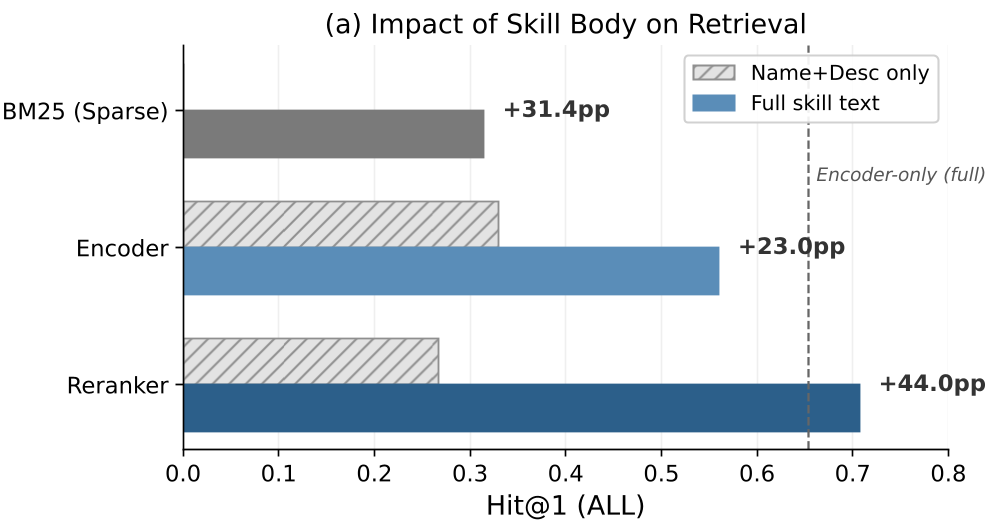 图注:移除 Body 导致的灾难性下降(左)与注意力分布(右)
图注:移除 Body 导致的灾难性下降(左)与注意力分布(右)
3. Methodology:SkillRouter 的双阶段架构
既然 Body 这么重要,干脆在检索全流程都塞进去。SkillRouter 采用了经典的 Retrieve-and-Rerank 架构,但针对技能特性做了极限优化:
第一阶段:精简版 Bi-encoder (SR-Emb)
使用 0.6B 的解码器架构模型作为底座,通过**硬负采样(Hard Negative Mining)**训练。为了解决社区库中 functional overlap(功能重叠)导致的训练噪音,作者设计了三层过滤机制(名称、Trigram 重合度、嵌入相似度)来剔除“假负例”。
第二阶段:Listwise Cross-encoder (SR-Rank)
这是 SkillRouter 的点睛之笔。作者发现,如果用传统的 Pointwise(二分类)损失训练,重排效果很差。原因很简单:入围的前 20 个工具长得太像了。 SkillRouter 采用了 Listwise Ranking Loss,强迫模型在 20 个候选中进行“全场对比”,选出一个最合适的。这种“货比三家”的逻辑在处理同质化严重的技能库时极度有效。
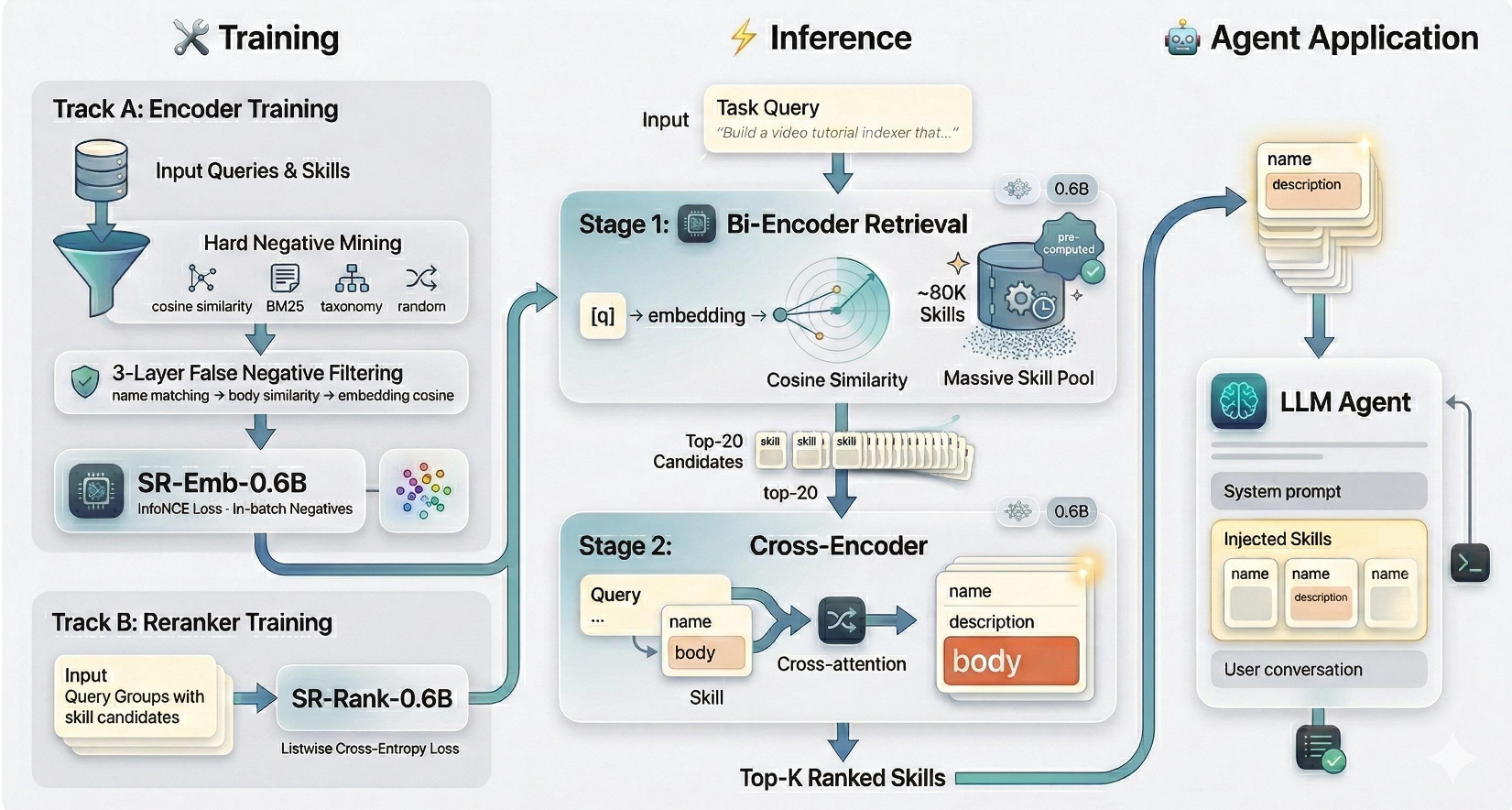 图注:SkillRouter 级联架构图
图注:SkillRouter 级联架构图
4. 实验结果:以小博大的典型
在一个包含 80,000 个技能的测试集中,SkillRouter (1.2B) 面对专家级查询展现了恐怖的统治力:
- Top-1 准确率 (Hit@1):达到 74.0%。
- 对比 8B 基线:比未经微调的 Qwen3-8B 强 6.0%。
- 对比商业模型:优于 OpenAI 的
text-embedding-3-large。
更关键的是效率:0.6B 的检索子模块可以轻松跑在笔记本的 CPU 上。这意味着你的个人 AI 助理无需上传所有私有工具信息到云端,在本地就能完成精准路由。
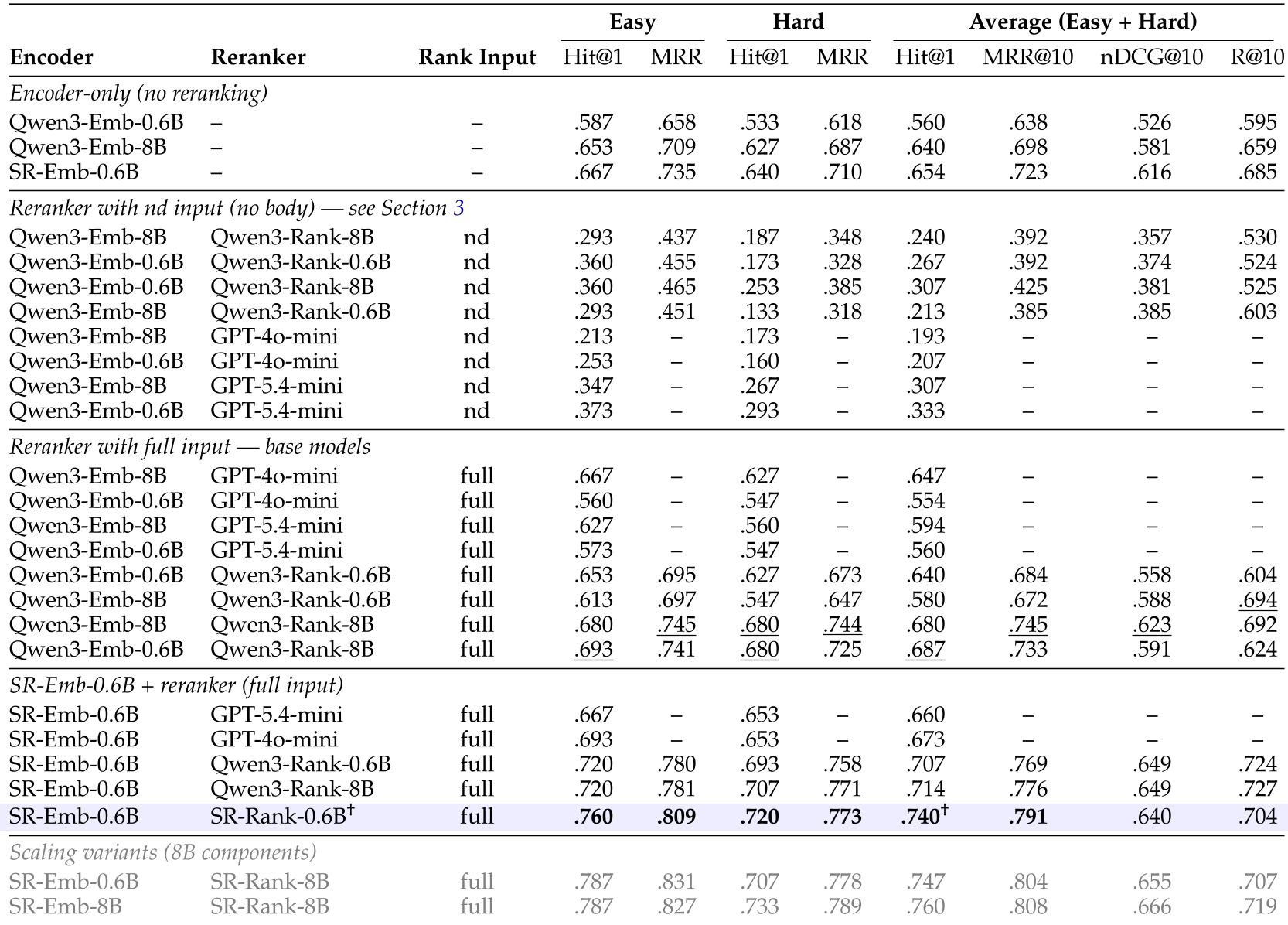 表注:SkillRouter 在全量指标上大幅领先各路基线
表注:SkillRouter 在全量指标上大幅领先各路基线
5. 深度洞察:为什么 0.6B 能赢 8B?
这并非魔法,而是因为作者精准捕捉了 Domain-specific Adaptation 的价值:
- 推理快捷化:微调过程教给了微小模型一种“语义捷径”。例如:Query 提到“提取视频时间戳”,通用模型会去找“视频编辑工具”,而微调后的 SR 模型能直接意识到这需要“语音转文字(Whisper)”技能。
- 抗干扰能力:SR-Rank 模型学会了在 Layer 19 集中处理“名称语义”,而在最后的 Layer 27 回归“Body 细节”。这种层级化的信息处理能力让它在面对极其相似的工具时更有定力。
6. 总结与局限
SkillRouter 证明了:对于专门的 Agent 路由任务,“堆参数”不如“喂代码”。
局限性:
- 目前的评估集(75 个 Query)规模较小。
- 对于需要多步推理(Multi-hop)才能匹配的工具(比如问“检测欺诈”,需要先选“PDF 表格提取”),单纯的检索仍然力有不逮,这类 Case 占了失败案例的 22%。
未来展望: 将 LLM 的推理链(CoT)与检索器结合,或许能解决那最后 22% 的长程语义漂移问题。
Takeaway:如果你在开发 Agent,别再只盯着 README 里的 Description 了,把 Implementation Body 丢进向量数据库,那是性能起飞的最后一块拼图。