Tempo is an efficient 6B-parameter vision-language framework designed for hour-long video understanding. It introduces a query-aware Local Compressor (SVLM) and Adaptive Token Allocation (ATA) to achieve state-of-the-art performance on benchmarks like LVBench under a strict 8K visual token budget.
TL;DR
Hour-long video understanding is often a "needle in a haystack" problem. Tempo addresses this by replacing blind video sampling with a query-aware distillation mechanism. By utilizing a 2B Small Vision-Language Model (SVLM) as a local compressor, Tempo dynamically allocates its token budget: it "fast-forwards" through irrelevant scenes and provides high-fidelity "slow-motion" focus on query-critical moments.
Despite having only 6B parameters, Tempo outperforms GPT-4o and Gemini 1.5 Pro on extreme-long video benchmarks (LVBench), proving that intelligence in compression is more valuable than raw context length.
The Bottleneck: Context Saturation and Semantic Blurring
To understand a 1-hour video, a model needs to process thousands of frames. If we use standard dense representations, the token count explodes, leading to two failures:
- The "Lost-in-the-Middle" Phenomenon: Even if the LLM has a large window, the attention mechanism gets diluted, causing it to miss evidence buried in the center of the stream.
- Heuristic Failure: Query-agnostic methods (like uniform pooling) might accidentally blur the 2-second clip that actually contains the answer.
Tempo's core insight is that compression should be driven by the user's question. If you ask "What color was the car in the chase?", the model should allocate almost all its "representational bandwidth" to the chase scene, not the landscape shots earlier in the film.
Methodology: The Smart Compressor & ATA
Tempo employs a hierarchical architecture: a Local Compressor (SVLM) and a Global Decoder (LLM).
1. Query-Aware Distillation
Instead of purely visual features, the SVLM takes the segment frames and the user query as input. It distills this cross-modal information into a fixed set of learnable memory tokens. This ensures that the tokens sent to the global LLM are already "pre-filtered" for relevance.
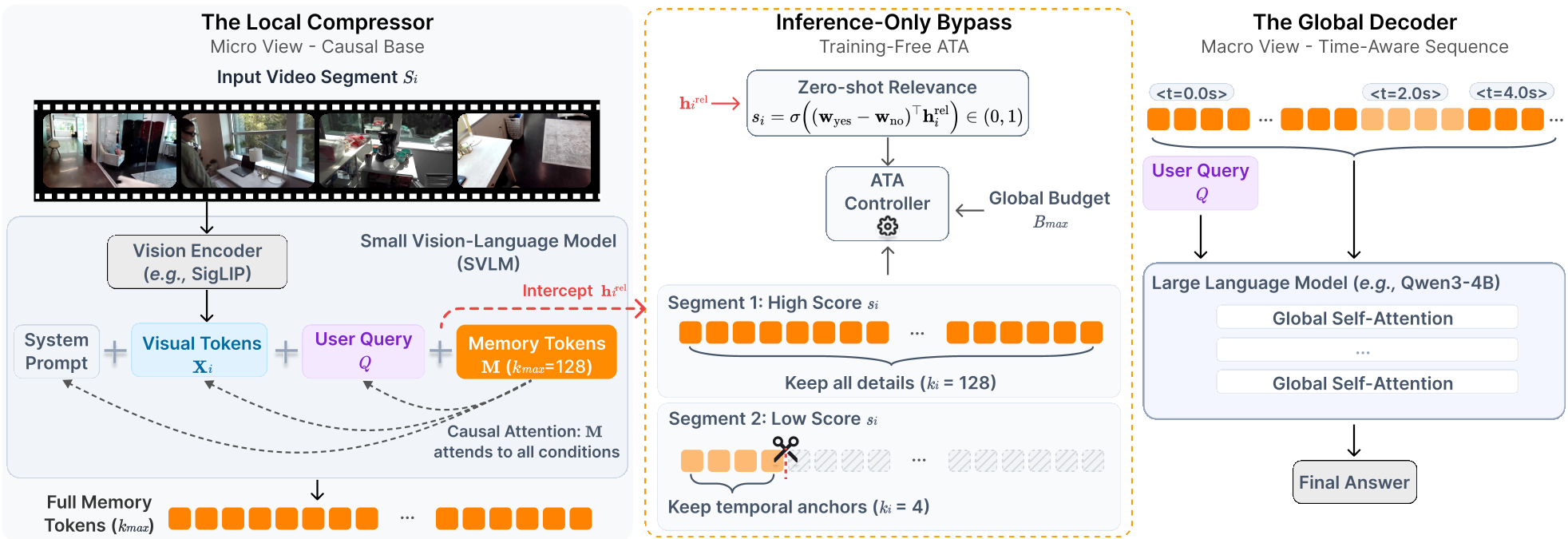
2. Adaptive Token Allocation (ATA)
ATA is a training-free inference strategy that uses the SVLM's internal "relevance prior." It works in two stages:
- Zero-Shot Scoring: The SVLM estimates if a segment is relevant to the query based on internal logits.
- Dynamic Head Truncation: Because of the causal nature of the SVLM, the most important semantic information is "front-loaded" into the first few memory tokens. ATA simply slices these tokens to meet a global budget.
- Temporal Anchors: To keep the model from losing its place in time, even "irrelevant" segments are kept as 4-token minimal anchors, preserving the global storyline.
Experimental Results: Beating the Giants
The most striking result is on LVBench, which features videos averaging over an hour in length.
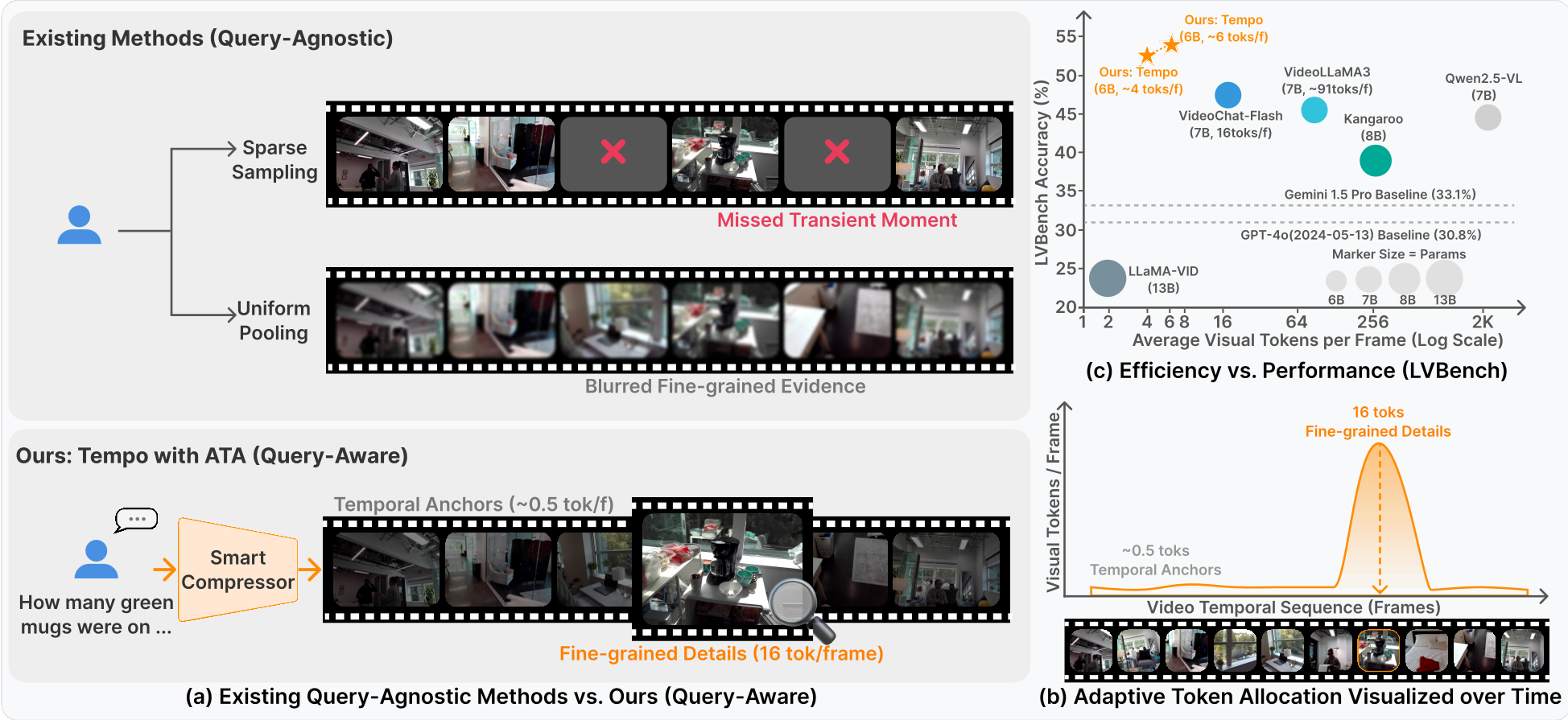
- SOTA Achievement: On LVBench, Tempo-6B achieved a score of 52.3, dwarfing GPT-4o (30.8).
- Efficiency: Tempo often uses an average of only 2.9 to 4.3 tokens per frame, whereas general MLLMs like Qwen2.5-VL use up to 1924 tokens per frame.
- Scaling Behavior: The authors found that while 4K tokens is a "sweet spot" for 30-minute videos, hour-long videos benefit monotonically from scaling up to 12K tokens (reaching 53.7 accuracy).
Ablation Insight: "Less is More"
Interestingly, Tempo sometimes performs better with a smaller 4K budget than an 8K budget. This confirms that active denoising (forcing the model to be extremely picky about tokens) helps the global LLM focus on the evidence that truly matters.
Critical Analysis & Conclusion
Tempo proves that the future of long-video AI isn't just "bigger context windows"—it's smarter routing.
Limitations:
- Multi-turn Dialogues: Currently, if the user asks a new question, the model must re-compress the video segments (though the visual features are cached).
- Serial Nature: While the O(1) truncation is fast, the initial compression pass still requires sequential or parallel segment processing.
Future Outlook: The "semantic front-loading" found in this paper suggests that vision-language models have an inherent hierarchy of information. Future work could involve reasoning-driven compression, where the model generates "thoughts" about a segment before deciding how many tokens to output.
Tempo sets a new standard: for hour-long videos, intent-driven sparsity beats greedy density.