本文提出了 Spark3R,一种针对前馈 3D 重建模型(如 VGGT, π3)的免训练(Training-free)加速框架。通过异步 Token 缩减策略,在处理 1,000 帧长视频输入时实现了高达 28 倍的加速,同时保持了 SOTA 级别的重建精度。
TL;DR
前馈 3D 重建模型(Feed-forward 3D Reconstruction)虽然能直接从图像预测几何结构,但面对长视频时总会撞上 Transformer 的“计算墙”。Spark3R 提出了一个巧妙的洞察:在 3D 重建中,Query Token 是敏感的“几何请求”,需要细心呵护;而 Key-Value Token 是共享的“场景背景”,可以大胆裁剪。凭借这一非对称逻辑,Spark3R 在不进行任何重新训练的情况下,将处理速度提升了 28 倍。
背景定位
目前 3D 重建正从传统的“逐场景优化(Per-scene Optimization)”向量量化的“前馈预测”演进。虽然 VGGT 和 π3 效果惊人,但其全局注意力(Global Attention)的复杂度随帧数呈二次方增长。一旦视频超过几百帧,显存和耗时便会失控。
痛点深挖:为何均匀压缩行不通?
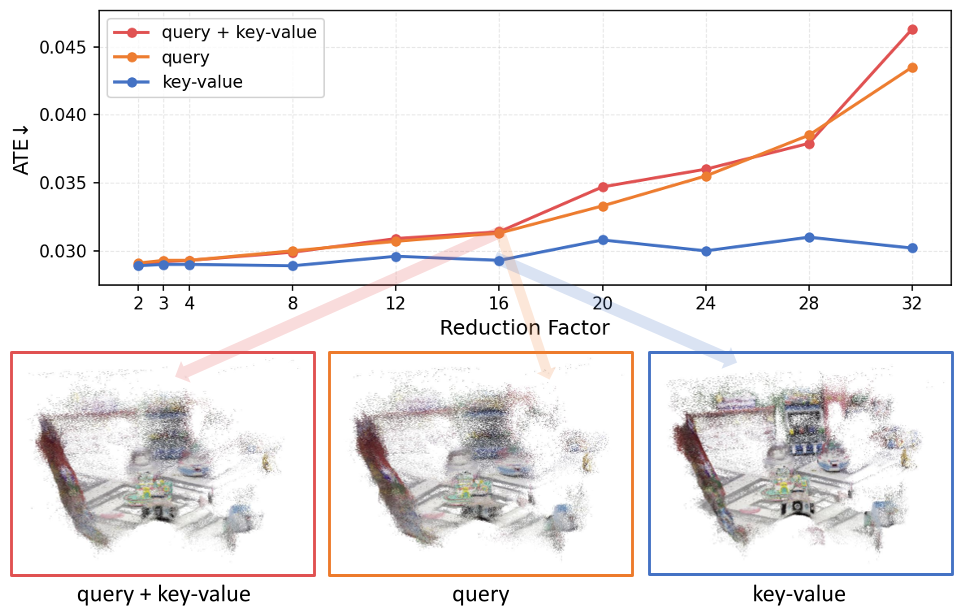
传统的 Token 合并方法(如 ToMe)对 Q 和 KV 一视同仁。但作者通过实验发现(见下图):
- Query 压缩:错误率迅速攀升,因为每个 Query 对应一个视角的特定几何预测。
- KV 压缩:曲线极其平顺,因为场景上下文在多帧间本质上是高度冗余的。
- 均匀压缩:性能下降最快,因为它在浪费 KV 压缩潜力的同时,还伤害了脆弱的 Query。
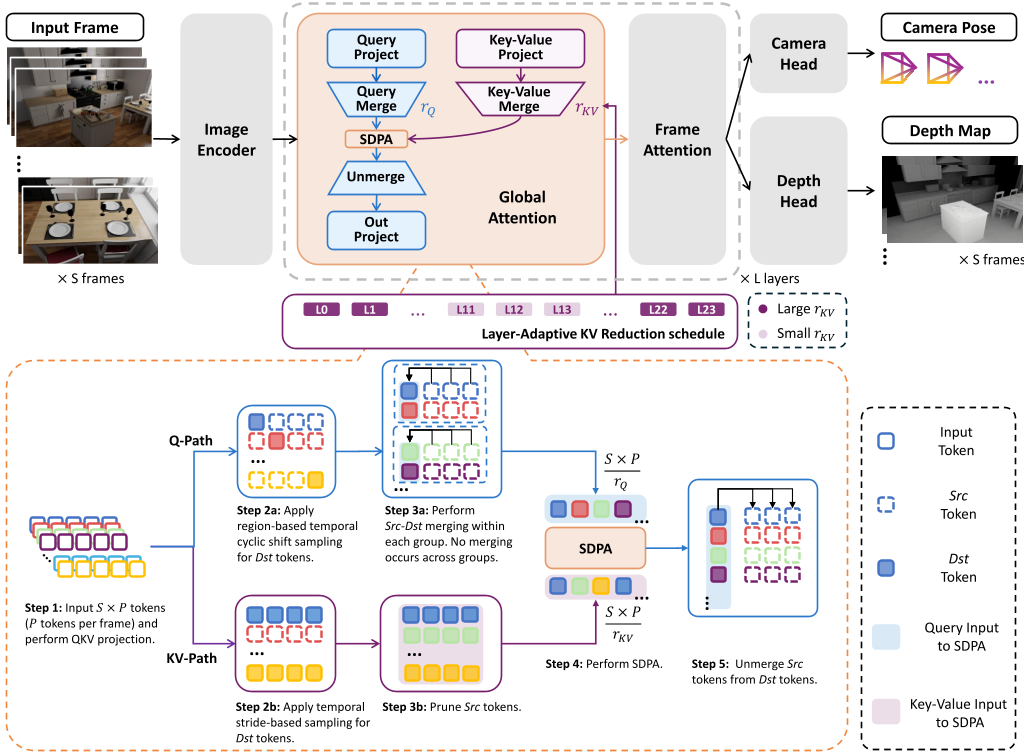
核心方法论:Spark3R 的三个火枪手
Spark3R 的架构设计围绕“非对称”展开,主要包含三个核心组件:
1. 组内 Query 合并 (Intra-Group Query Merging)
作者发现,Token 合并往往发生在时间邻域内。通过将帧分成大小为 G 的模块(默认 G=20),在组内进行匹配,将复杂度从 降低到 。这既保留了核心的几何请求,又避免了无效的全局搜索。
2. 轻量级 KV 裁剪 (Lightweight KV Pruning)
由于 KV Token 对应的相似度极高(常超过 0.9),作者大胆去掉了复杂的“合并取平均”操作,直接进行“采样裁剪”。这种方法几乎零开销,却能极大地缩减注意力图的大小。
3. 层自适应调度 (Layer-Adaptive Schedule)
并非所有 Transformer 层都同等重要。通过离线探测发现,中间层对 KV 压缩更敏感。Spark3R 为低敏感层分配了更高的压缩倍率(高达基础倍率的 3 倍),从而榨取最后的性能红利。
实验与结果:不仅是快,甚至更准
在 7-Scenes 和 ScanNet 等标准数据集上,Spark3R 展示了令人振奋的结果:
- 速度:在 1000 帧任务下,原本需要 1100 秒的处理过程缩短至 40 秒以内(提升约 28 倍)。
- 精度:在 VGGT 模型上,Spark3R 奇迹般地降低了位姿误差(ATE 从 0.156 降至 0.065)。
- 直觉解释:这是由于在高倍压缩下,模型缓解了“注意力稀释”现象——Query 能够更集中地关注精简后的高质量 KV 上下文,从而得到更清晰的几何边界。
 上图显示,Spark3R (底行) 在处理复杂细节(如门框和纹理)时,比之前的 FastVGGT 更加锐利,且消除了 ZipMap 中的结构扭曲。
上图显示,Spark3R (底行) 在处理复杂细节(如门框和纹理)时,比之前的 FastVGGT 更加锐利,且消除了 ZipMap 中的结构扭曲。
深度洞察与总结
Spark3R 证明了在 3D 视觉任务中,“理解 Token 的角色属性”比“改进算子本身”更重要。它通过极简的逻辑(采样与局部合并)实现了比复杂重训练(如 ZipMap)更优的权衡。
局限性:作为一种“即插即用”的剪枝方案,它无法突破原模型本身的精度上限。未来,如果能结合微调(Fine-tuning),在大规模点云分布上进行自适应学习,其天花板可能更高。
结论:对于资源受限的机器人或自动驾驶场景,Spark3R 提供了一种极具吸引力的长视频 3D 重建加速方案。