SparseCam4D is a novel 4D reconstruction framework designed to achieve high-fidelity dynamic scene synthesis from sparse, uncalibrated cameras. It leverages video diffusion models to generate auxiliary observations and introduces a Spatio-Temporal Distortion Field (STDF) to resolve inherent inconsistencies in generative data.
TL;DR
High-quality 4D reconstruction—capturing dynamic scenes over time—traditionally requires an expensive "bullet-time" style setup with dozens of cameras. SparseCam4D changes the game by enabling photorealistic 4D reconstruction from as few as 2 to 3 sparse cameras. By combining 4D Gaussian Splatting (4DGS) with Video Diffusion Models and a novel Spatio-Temporal Distortion Field (STDF), it cleans up the "flickering" noise of AI-generated views to build a rock-solid, consistent 4D world.
The "Density" Problem & The "Flickery" Solution
To capture a dynamic scene (like a person cooking or jumping), you typically need cameras everywhere to fill in the gaps. If you only have two cameras, the space between them is a "blind spot."
Current researchers try two things:
- Geometric Regularization: Using depth maps to guess the shape. Result: Blurry textures and "floating" artifacts.
- Generative Models: Using AI (Video Diffusion) to "dream up" the missing views. Result: The AI dreams are inconsistent—objects shift slightly, and surfaces flicker, making 4D reconstruction "noisy" and unstable.
SparseCam4D’s insight is simple but brilliant: Don't fight the AI's inconsistency; model it.
Methodology: The Spatio-Temporal Distortion Field (STDF)
The researchers introduced the Ennea-plane (9-plane) representation. Instead of just modeling space $(x, y, z)$ and time $(t)$, they added a pose axis $(s)$.
How it works:
- Canonical Gaussians: The model maintains a "perfect" set of 4D Gaussians.
- The Distortion Field: For every AI-generated frame, the STDF calculates a small "tweak" (deformation) in position, rotation, and scale. This tweak accounts for the AI's mistakes (the flickering and shifting).
- Training vs. Inference: During training, the model uses these tweaks to match the AI frames. Once training is done, the tweaks are thrown away, leaving only the "perfect" canonical model for crystal-clear playback.
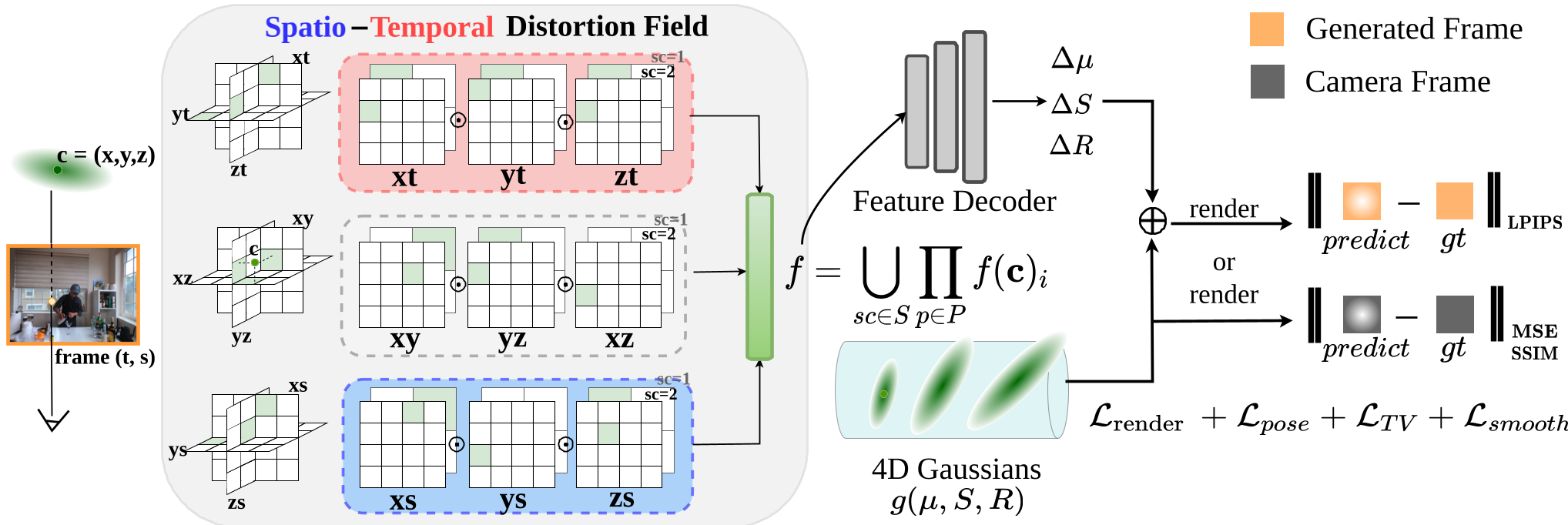 Figure: The STDF pipeline disentangles generative noise from the true scene geometry.
Figure: The STDF pipeline disentangles generative noise from the true scene geometry.
Battle-Tested Results
The authors tested SparseCam4D against heavy hitters like HyperReel, 4DGS, and MonoFusion. Across three major datasets, SparseCam4D didn't just win; it dominated.
| Method | Technicolor (PSNR↑) | Nvidia Dynamic (PSNR↑) | | :--- | :--- | :--- | | 4DGaussians (SOTA) | 16.20 | 16.81 | | MonoFusion (Latest) | 17.97 | 20.22 | | Ours (SparseCam4D) | 23.15 | 24.81 |
Visually, the difference is striking. While other methods produce "broken" geometry or noisy voids in dynamic regions (like a splashing bottle or a moving person), SparseCam4D maintains sharp edges and temporal smoothness.
 Figure: Comparison showing SparseCam4D's ability to recover fine details that other models lose.
Figure: Comparison showing SparseCam4D's ability to recover fine details that other models lose.
Critical Insight: Why This Matters
The most impressive part of this work is its efficiency. Because the Distortion Field is discarded after training, the actual rendering speed remains at ~12 FPS on an A800 GPU—identical to models that use much simpler logic.
Limitations: The model is still "held hostage" by the quality of the Video Diffusion Model. If the AI hallucinates a second head on a person, the STDF can only do so much to fix it.
Conclusion
SparseCam4D is a milestone for "free-viewpoint" video. It effectively bridges the gap between the imaginative power of Diffusion Models and the geometric precision of Gaussian Splatting. For the future of VR/AR and film production, this means high-quality 4D capture is moving out of the multi-million dollar lab and into our living rooms.
Takeaway: By explicitly modeling the "noise" of generative AI, we can use that noise as a powerful signal to reconstruct the real world.