Sakana AI and NVIDIA researchers present a groundbreaking framework for leveraging unstructured sparsity in Transformer Feedforward (FFN) layers. By introducing the TwELL (Tile-wise ELLPACK) packing format and optimized CUDA kernels, the authors achieve over 99% activation sparsity with negligible performance loss, resulting in up to 21.9% faster training and 20.5% faster inference on billion-parameter LLMs.
TL;DR
The industry has long known that Large Language Models (LLMs) are "lazy"—most of their neurons don't actually fire for any given token. However, translating this into actual speed has been a "frustrating paradox" because GPUs hate irregular, sparse data. This paper solves the puzzle by introducing TwELL, a hardware-aware sparse format, and a Hybrid Training Pipeline. The result? 20%+ faster models with 99% fewer active neurons, all while maintaining SOTA accuracy.
The Problem: The Sparse-Dense Mismatch
Modern GPUs are race cars designed for a specific track: Dense Matrix Multiplications. When we introduce unstructured sparsity, we essentially ask that race car to drive through an obstacle course.
- Format Bottlenecks: Formats like ELLPACK require us to "count" non-zeros before we can pack them, which prevents "fusing" operations together.
- Memory Irregularity: Sparse indices lead to non-coalesced memory access, killing DRAM throughput.
- Training Overhead: During training, we must store activations for the backward pass. Storing them sparsely is tricky because "outlier" tokens (highly active ones) can cause memory overflows in static sparse buffers.
The Solution Part 1: TwELL (Tile-wise ELLPACK)
The core innovation is TwELL. Instead of looking at a whole row of a matrix, TwELL divides data into 1D horizontal tiles that match the 2D tiling of NVIDIA's WGMMA (Warpgroup Matrix Multiply-Accumulate) instructions.
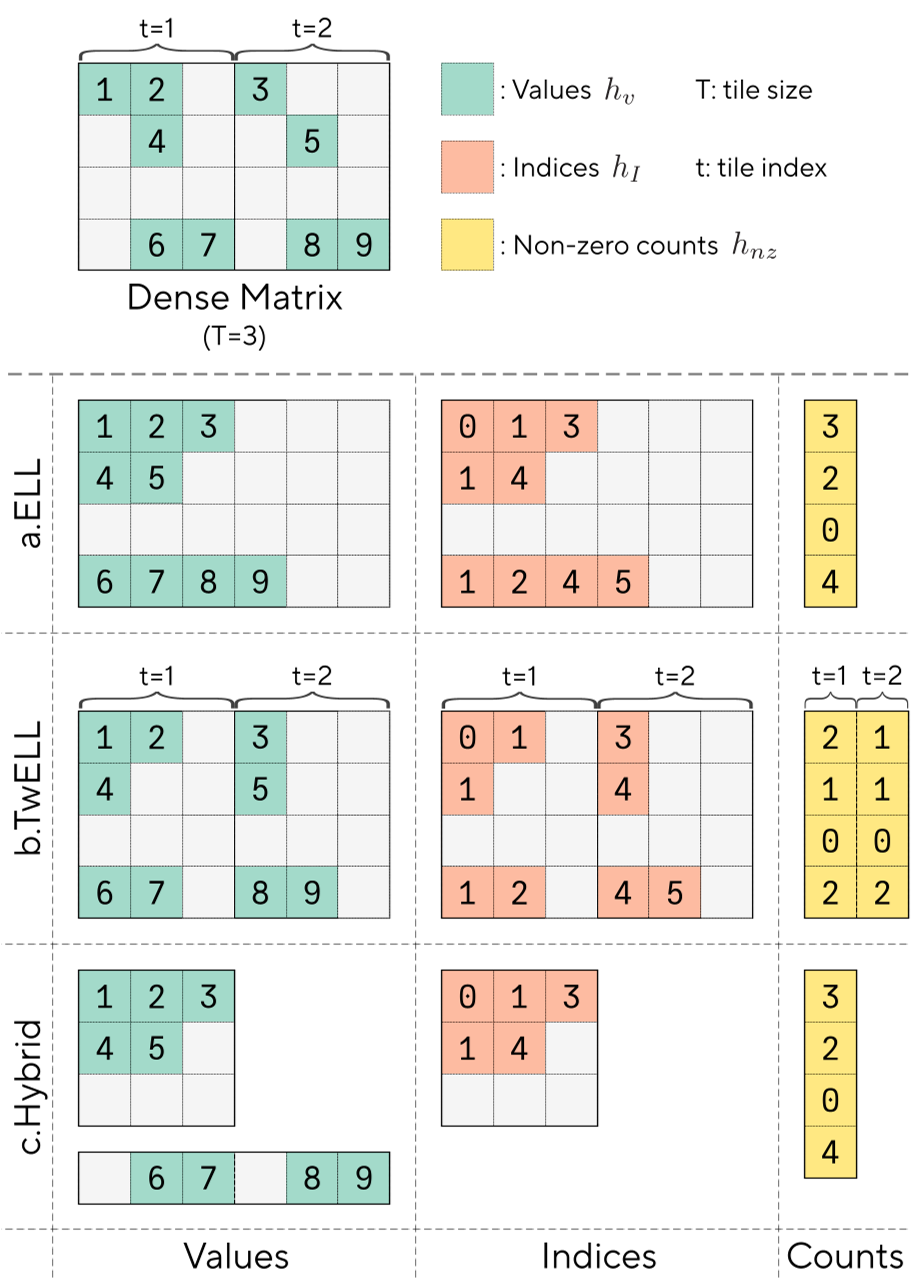 Figure 1: Comparison of ELL, TwELL, and the Hybrid Format.
Figure 1: Comparison of ELL, TwELL, and the Hybrid Format.
By aligning the sparse format with the GPU's native tiling, the authors can perform the ReLU and the sparse packing inside the same kernel that did the matrix multiply. This "fuse-everything" approach eliminates the need to read and write intermediate dense data to DRAM.
The Solution Part 2: Hybrid Training
LLM training is inherently unpredictable. Some tokens are "predictable" and trigger few neurons, while "high-information" tokens (like specific nouns/verbs) trigger many. The authors propose a Hybrid Format:
- The Sparse Path: 90%+ of tokens are packed into an aggressive, low-bit ELL format.
- The Dense Tail: The "overflow" tokens that are too active for the sparse format are rerouted to a standard dense buffer.
- Balanced Compute: This allows the GPU to use fast, irregular sparse kernels for the majority of the work while falling back to high-throughput Tensor Cores for the heavy-duty outliers.
Methodology: Inducing Sparsity
The researchers used a simple but effective recipe:
- ReLU-fication: Replace the popular SiLU/GELU with ReLU to ensure actual zeros.
- L1 Regularization: Add a penalty to the loss function to encourage activations to stay near zero.
Surprisingly, they found that even with over 99% sparsity (less than 30 neurons active out of 5632), the model’s reasoning on benchmarks like ARC and HellaSwag remained stable.
Experimental Battlefront: H100 vs. RTX 6000
The performance gains scale with model size. As the model gets larger, the FFN layers account for a higher percentage of the total FLOPs, making the sparse speedup more impactful.
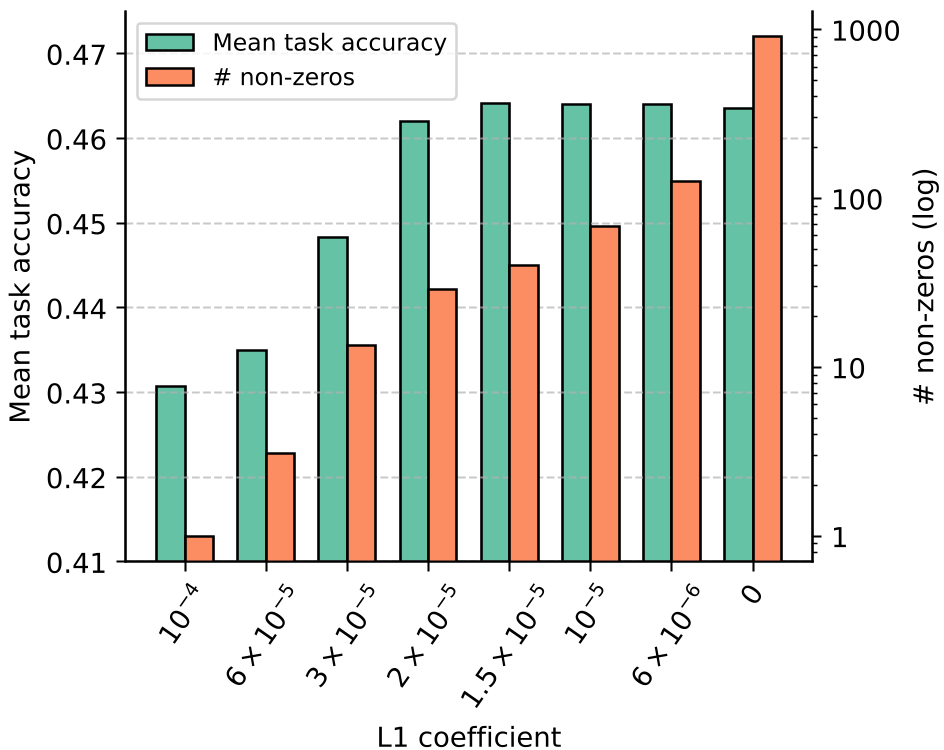 Figure 2: Forward pass speedups and energy savings across different sparsity levels.
Figure 2: Forward pass speedups and energy savings across different sparsity levels.
Key Benchmarks:
- Inference: 2B model tokens/ms increased by 20.5%.
- Memory: Peak training memory dropped by 28.1% for a 1.5B model, allowing larger batches on the same hardware.
- Consumer Hardware: On the RTX 6000, the training speedup was even higher than on the H100 because the sparse kernels could better utilize the larger number of Streaming Multiprocessors (SMs) relative to the memory bandwidth.
Insights: Why does this work?
The paper provides a fascinating look into token-level computation:
- Low Activity: Function words (e.g., "doesn", "couldn") and web URL components (e.g., "doi", "gov") trigger very few neurons. The model knows what’s coming next and doesn't "think" hard.
- High Activity: Specific, niche nouns (e.g., "Vermont", "Greeks", "formaldehyde") require heavy lifting.
- Positional Sparsity: The very first tokens in a sequence use massive amounts of neurons (to establish context), while later tokens use exponentially fewer.
Conclusion & Future Work
Sakana AI has effectively "unlocked" the efficiency of unstructured sparsity. By making it practical to train and run these models on standard GPUs without specialized MoE hardware, they've opened a new path for sustainable AI.
Limitations: The study currently focuses on models up to 2B parameters. Scaling these kernels to 70B+ models and investigating "dead neuron" revival (to support even higher L1 coefficients) are the next logical steps for the community.
All code and kernels are being open-sourced to accelerate research into light-weight foundation models.