SpatialBoost is a scalable training framework that enhances the spatial awareness of pre-trained vision encoders (e.g., DINOv3, SigLIPv2) using language-guided reasoning. By converting dense 3D spatial information into hierarchical linguistic descriptions and using an LLM as a teacher, it achieves state-of-the-art performance, notably improving DINOv3's ADE20K mIoU from 55.9 to 59.7.
In the current AI landscape, vision encoders like DINOv2 and SigLIP are the bedrock of visual understanding. However, these models have a "flat" worldview. Having been trained primarily on 2D internet crawls, they often fail to grasp the 3D geometry and spatial relationships necessary for complex tasks like robotics or immersive scene understanding.
How do we teach a 2D model about 3D space without a massive, expensive 3D dataset? The answer, according to the researchers at KAIST and NAVER Cloud, isn't more pixels—it's Language.
The Core Insight: Language as a Spatial Bridge
The fundamental premise of SpatialBoost is that language can act as a structured, scalable supervision signal for 3D geometry. While a depth map is just a grid of numbers, a linguistic description like "The chair is 1.5 meters behind the table" provides semantic and geometric context that an LLM can reason about.
SpatialBoost operates through a three-stage pipeline, ultimately using an LLM to "explain" the 3D world to the vision encoder.
Hierarchical Reasoning: The Spatial CoT
The authors argue that current spatial VQA (Visual Question Answering) datasets are too simplistic. To build a truly robust representation, they propose a Spatial Chain-of-Thought (CoT) dataset spanning three levels:
- Pixel-level: "What is the depth value at coordinate (x, y)?"
- Object-level: "Is object [A] to the left of object [B]?" (Using the pixel-level data as a rationale).
- Scene-level: "How far is object [A] from object [B]?"
By training the model to answer these in sequence, the vision encoder is forced to learn hierarchical spatial features.
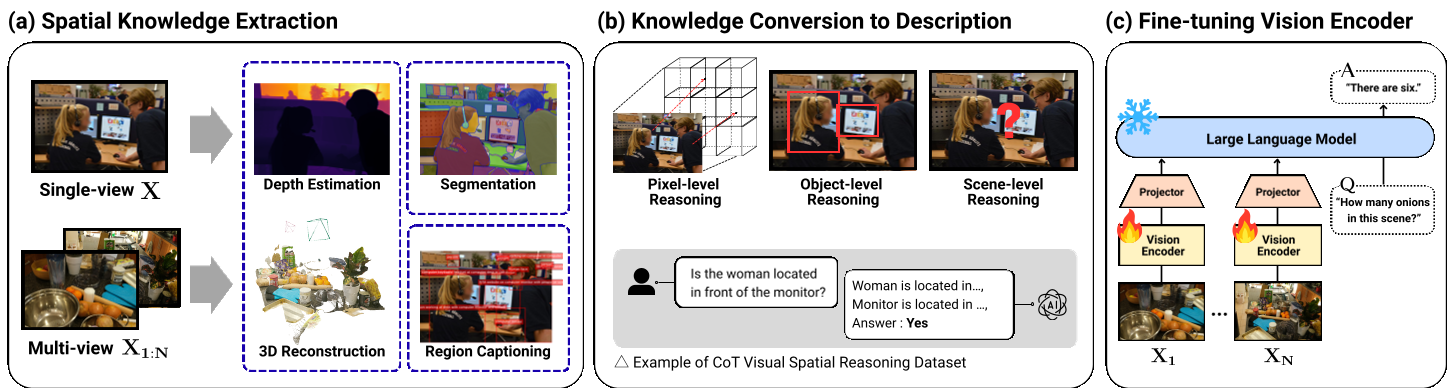 Figure 1: SpatialBoost leverages LLM-guided reasoning to transform 2D visual inputs into structured 3D knowledge.
Figure 1: SpatialBoost leverages LLM-guided reasoning to transform 2D visual inputs into structured 3D knowledge.
Architecture: Learning without Forgetting
A common pitfall in academic research is "fine-tuning degradation"—where a model gets better at a specific task (like depth estimation) but loses its general intelligence (like classification).
To combat this, SpatialBoost introduces the Dual-Channel Attention module. For every attention layer in the original encoder, a new, parallel "spatial channel" is added.
- Original Channel: Frozen (Preserves general visual knowledge).
- Spatial Channel: Trainable (Learns new 3D insights).
- α-Gating: A learnable parameter that dynamically blends the two.
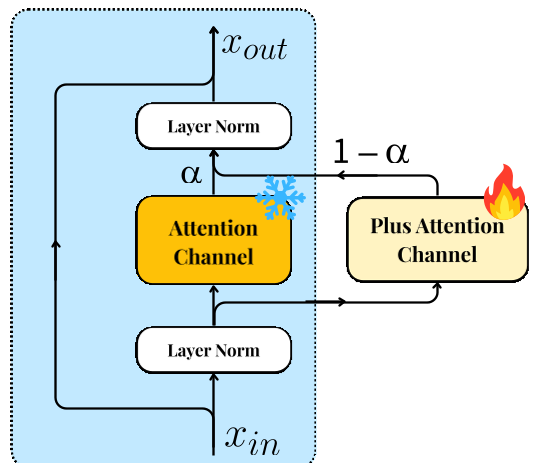 Figure 2: The Dual-Channel Attention mechanism allows the model to expand its capabilities without catastrophic forgetting.
Figure 2: The Dual-Channel Attention mechanism allows the model to expand its capabilities without catastrophic forgetting.
Experimental Breakthroughs
The results across the board are impressive. SpatialBoost doesn't just "not break" the base models; it actively improves them—even on 2D tasks.
- Semantic Breakthrough: On ADE20K, DINOv3 + SpatialBoost hit 59.7 mIoU, a +3.8% gain over the standard model.
- Robotics Potential: In vision-based robot control (CortexBench), the average success rate jumped from 72.8 to 80.8.
- The OpenCLIP Miracle: Perhaps the most shocking result was on 3D semantic segmentation, where OpenCLIP improved from a meager 6.9 mIoU to 54.9 mIoUs, effectively gaining a "spatial sense" it never functionally had before.
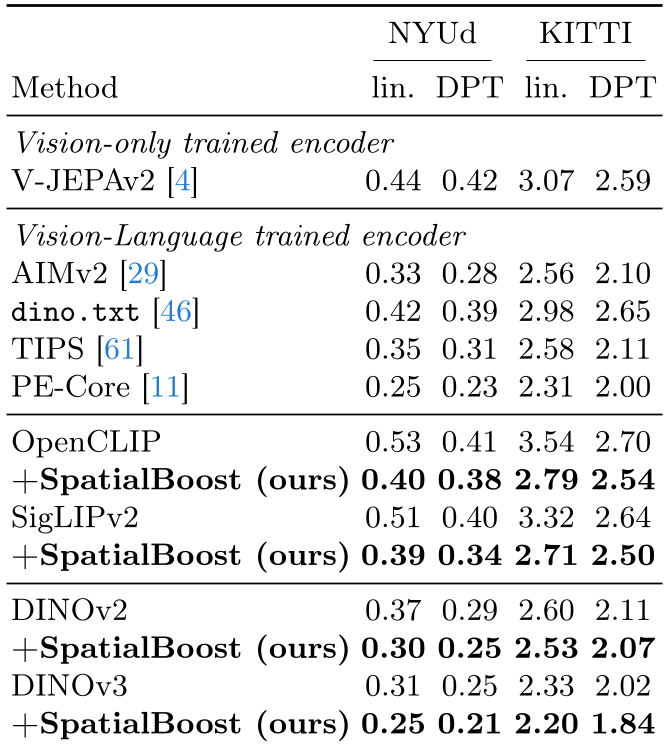 Table 1: Significant improvements in depth estimation metrics (RMSE) across various SOTA backbones.
Table 1: Significant improvements in depth estimation metrics (RMSE) across various SOTA backbones.
Why it Works: The Efficiency of LLM Supervision
In a fascinating ablation study (Table 6 in the paper), the authors compared using an LLM as a teacher vs. using traditional labels (like SAM segmentation decoders or depth layers). The LLM-based supervision outperformed every pixel-level alternative.
This suggests that the reasoning requirement—having to process spatial relations in sentences—forces the vision encoder to learn more abstract, transferable features than simple regression to a depth map ever could.
Conclusion and Future Outlook
SpatialBoost proves that we don't necessarily need more multi-view footage or expensive LiDAR data to build better vision models. By leveraging the linguistic reasoning power of LLMs, we can refine our existing 2D encoders into 3D-aware agents.
While the reliance on other vision models (like Depth-Pro) to generate the training data creates some potential for bias propagation, the authors' experiments show this effect is marginal. SpatialBoost represents a significant step toward "World Models" that can see and act in our 3D reality.