[Journal of Computational Physics] P-STMAE:突破不规则采样限制,高维动力系统的“遮蔽重构”新范式
本文提出了 Physics Spatiotemporal Masked Autoencoder (P-STMAE),这是一种专门为不规则时间步长的高维动力系统预测设计的模型。该方法结合了卷积自编码器 (CAE) 进行空间降维与 Masked Autoencoder (MAE) 进行潜空间时序建模,在 Shallow Water 和 NOAA 海表温度等数据集上实现了 SOTA 性能。
TL;DR
在科学模拟与环境观测中,数据缺失和时间步长不齐是常态。传统的 RNN 或 CNN 架构在面对这种“残缺”序列时,往往需要通过插值来生搬硬套,导致误差叠加。本文提出的 P-STMAE (Physics Spatiotemporal Masked Autoencoder) 通过在潜空间(Latent Space)进行 Mask 学习,实现了无需预处理、一次性生成完整时空序列的跨越,在海洋气象预报等任务中表现出极强的健壮性。
背景定位:当物理系统遇上“断断续续”的观测
预测高维动力系统(如流体、气候)通常要求数据具有严格的连续性和规律性。然而现实中:
- 传感器故障:导致某些时间点数据完全丢失。
- 自适应步长:数值求解器为了稳定,会在变化剧烈时加密采样,平缓时稀疏采样。
- 代价昂贵:某些昂贵的实验只能进行零星观测。
传统方法如 ConvLSTM 就像一个“强迫症”,必须把缺失补齐才能运行。而 P-STMAE 的设计直觉是:为什么不让模型直接学习这些缺口?
核心机制:潜空间中的“填字游戏”
P-STMAE 的核心架构分为两层:
1. 空间压缩 (Spatial Compression)
直接处理 128x128 甚至更高分辨率的图像序列对 Transformer 的 Self-attention 来说是灾难性的(计算量随长度二次方增长)。作者首先使用 Convolutional Autoencoder (CAE) 将高维场压缩成长度为 128 的向量。
2. 时序重构 (Masked Reconstruction)
这是本文的精髓。作者将观测到的时间步视为已知的“Token”,将缺失步和未来预测步视为“占位符(Placeholder)”。
- Encoder:只对观测到的数据块进行编码。
- Decoder:加入可学习的 Mask Token,通过注意力机制从已观测到的上下文(Context)中推导出缺失的状态。
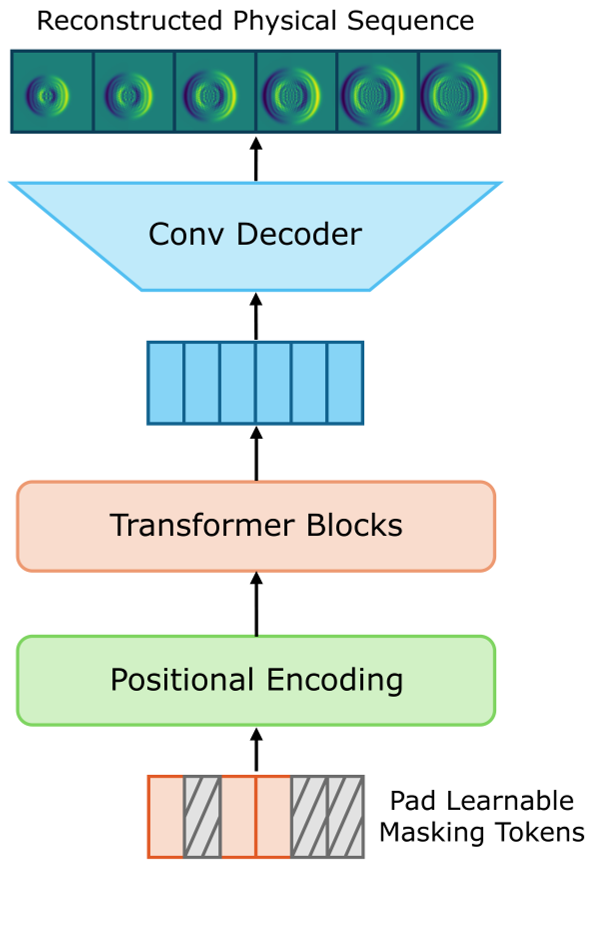 图 1:P-STMAE 架构。左侧为 CAE 编码过程,右侧为 Transformer 在潜空间进行遮蔽和重构的逻辑。
图 1:P-STMAE 架构。左侧为 CAE 编码过程,右侧为 Transformer 在潜空间进行遮蔽和重构的逻辑。
实验战绩:比 RNN 更快、更准、更稳
研究团队在 浅水方程 (Shallow Water)、反应扩散 (Diffusion Reaction) 及 NOAA 海层温度记录 (SST) 三大基准上进行了验证。
关键发现:
- 精度飞跃:在浅水方程实验中,P-STMAE 的误差(MSE)仅为 ConvLSTM 的 1/3。
- 抗干扰能力:当数据缺失率从 1 步增加到 6 步时,ConvLSTM 的性能呈断崖式下跌,而 P-STMAE 的误差曲线几乎是平稳的(见下图)。
- 非线性鲁棒性:通过增加“空档时间(Dilation)”,P-STMAE 在面对更混乱的非线性动态时,依然能保持稳定的 SSIM(结构相似性)。
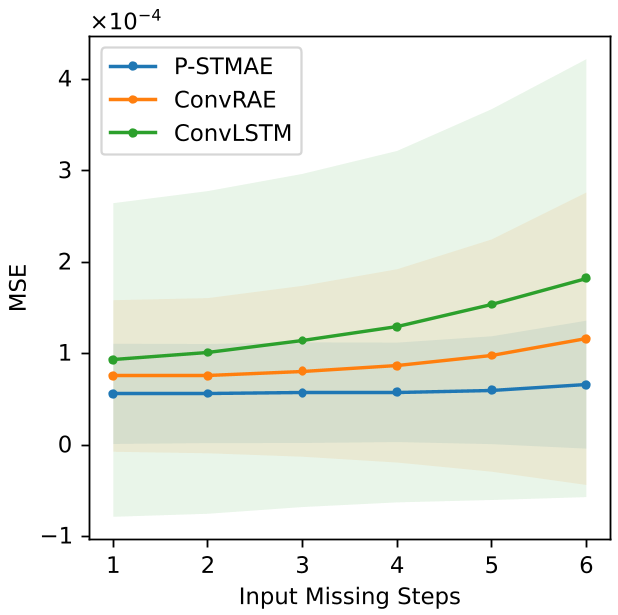 图 2:缺失率分析与采样扩张分析。可以看到 P-STMAE (蓝线) 在复杂工况下的稳定性远超 RNN 变体。
图 2:缺失率分析与采样扩张分析。可以看到 P-STMAE (蓝线) 在复杂工况下的稳定性远超 RNN 变体。
深度洞察:为什么 Masked Attention 有效?
相比于 RNN 的“一步看一步(Autoregressive)”,Transformer 的注意力机制能够实现“全局同步”。在物理系统中,未来的状态不仅取决于过去,也受到物理场整体结构的约束。
- 避免误差累积:RNN 在推导长序列时,前一步的微小误差会像滚雪球一样放大。P-STMAE 通过一次性并行预测(Single-pass Inference),彻底切断了这一传播路径。
- 隐式物理一致性:虽然模型没有显式嵌入 PDE 公式,但通过大量物理场数据的重构训练,模型在潜空间捕获了质量守恒和流体连续性的隐含模式。
总结与局限
P-STMAE 为处理真实世界的“脏数据(Dirty Data)”提供了强有力的工具。它的局限性在于 Transformer 对超长序列的处理开销依然存在。未来,引入 RoPE (旋转位置编码) 或类似 Mamba (SSM) 的架构可能会进一步提升其在长程气候预测中的表现。
对于需要从稀疏、零散的卫星或传感器数据中提取物理规律的研究者来说,这篇论文无疑提供了最佳的架构模板。