本文通过对 51 个类级别生成任务的研究,提出了“规范差距”(Specification Gap)概念,探讨了多代码智能体在独立实现同一类的方法时,因规范不完整导致的协调失败。研究发现,即使使用 SOTA 模型(如 Claude 3 Sonnet),多智能体协作在缺乏详细规范时,其准确率比单智能体基线低 25-39%。
TL;DR
当多个 AI 智能体共同开发一个软件模块时,它们往往像一群没有指挥的乐手。本文揭示了一个被称为 Specification Gap(规范差距) 的现象:由于对内部数据结构缺乏共识,多智能体生成的代码集成后准确率相比单智能体骤降了 30% 以上。研究发现,“详细的规范文档” 是解决冲突的唯一良药,而单纯的错误检测报告几乎无济于事。
背景:协作中的“暗雷”
目前的 AI 代码生成正在从单兵作战转向多智能体(Multi-agent)协作。理想很丰满:Agent A 写初始化,Agent B 写查询,Agent C 写逻辑。但现实很骨感:如果规范没写清楚这个类该用列表还是字典存储数据,Agent A 可能会初始化一个 [],而 Agent B 却尝试用 .get() 访问。这种由于**局部知识(Partial Knowledge)**导致的结构性不兼容,正是软件工程中最难修的 Bug 之一。
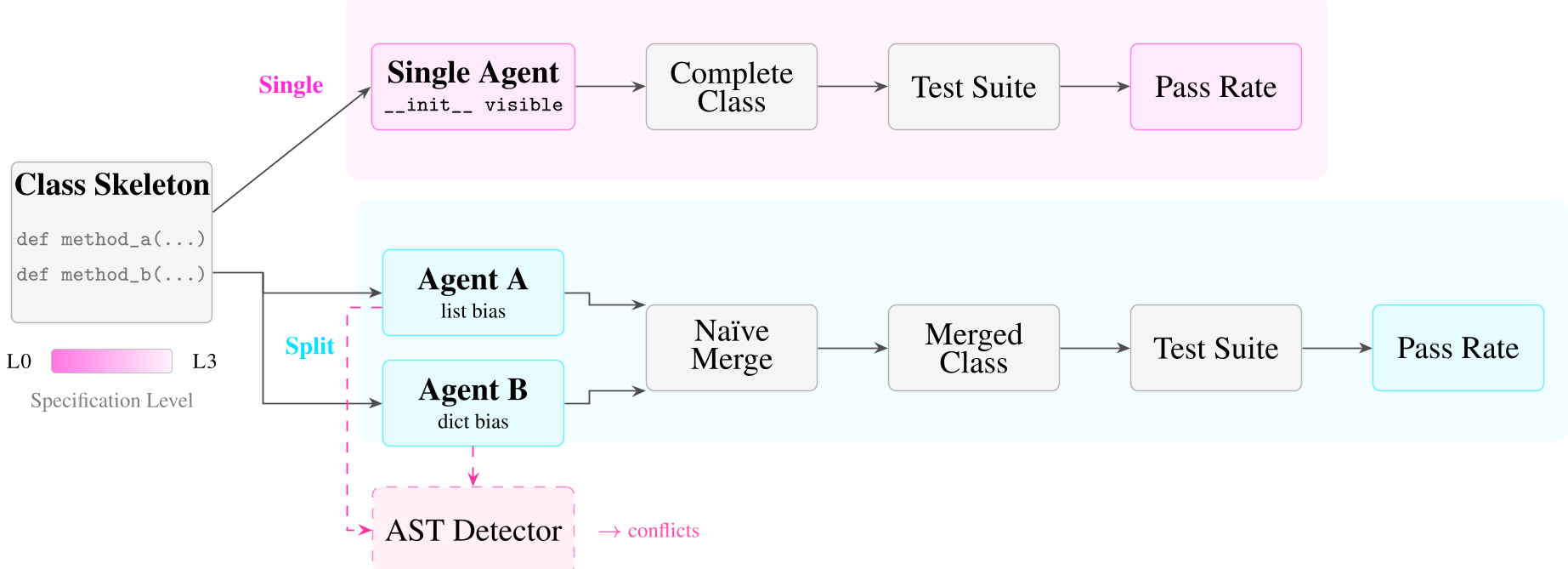
实验设计:结构性偏好的压力测试
为了量化这种“不兼容”,作者设计了一套严谨的消减实验:
- 分级规范 (L0-L3):
- L0 (Full):包含详细注释、示例代码(Doctests)和明确的数据结构引用。
- L3 (Bare):仅保留函数签名(方法名和参数),没有任何说明。
- 注入偏好 (Structural Biases):
- 给 Agent A 注入“列表偏好”(存储数据必须用 List)。
- 给 Agent B 注入“字典偏好”(存储数据必须用 Dict)。
- 基线对比:以单智能体(Single Agent)在拥有全局视野下的表现作为上限(Ceiling)。
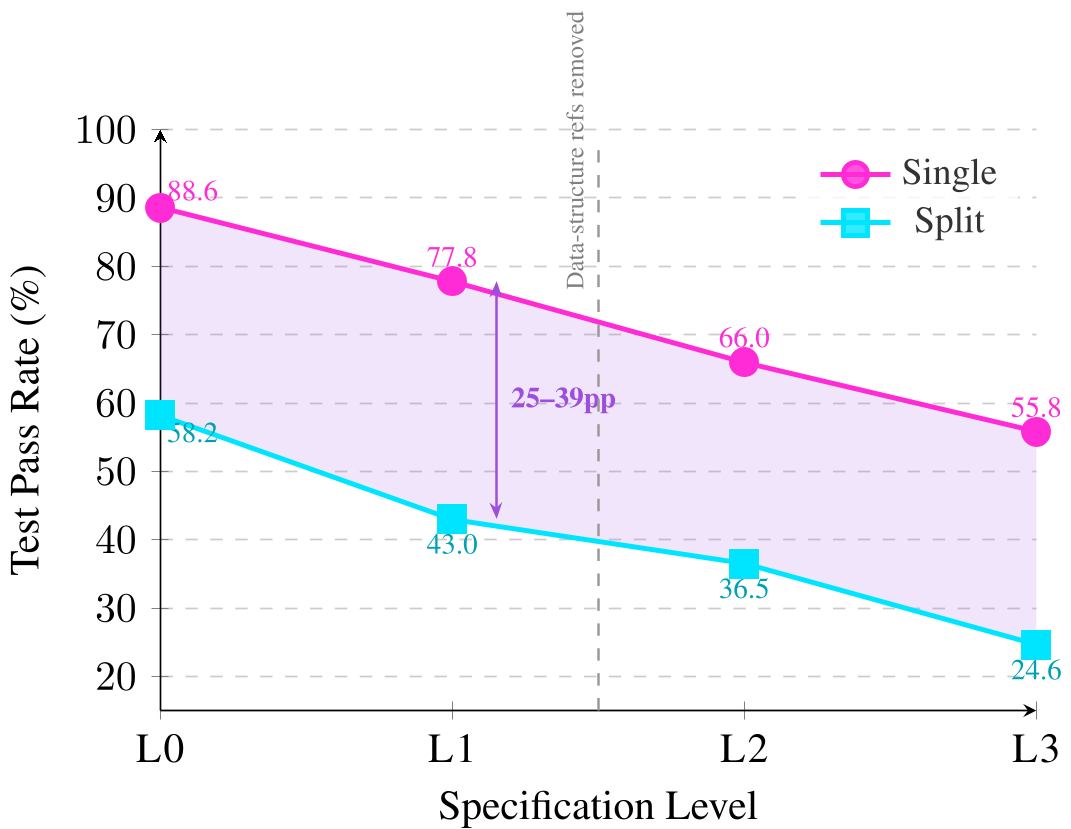
核心发现 1:不可忽视的“协调税”
实验数据显示,随着规范信息的丢失,集成成功率呈现单调下降。在最极端的 L3 级别,多智能体集成的准确率仅剩 24.6%,而单智能体仍有 55.8%。
作者指出,即便在 L0 级别(规范最全时),多智能体依然存在 ~30% 的性能缺口。这意味着,多智能体架构天然存在一种“协调税(Coordination Tax)”,这种惩罚并非源于模型能力不足,而是源于独立生成时无法共享决策状态带来的一致性损耗。
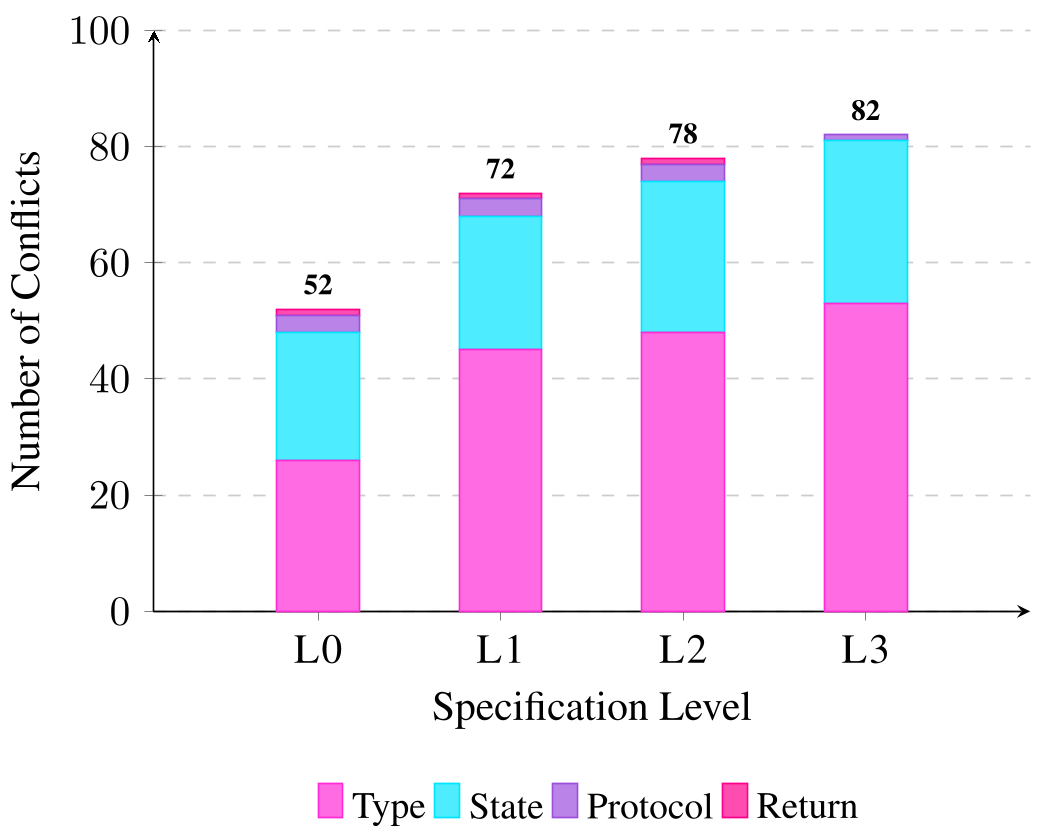
核心发现 2:诊断易,修复难
作者开发了一种基于 AST (Abstract Syntax Tree) 的冲突检测器。该工具不消耗 Token,仅通过分析生成代码的语法树就能判断字段类型是否冲突。
- 诊断效果:在规范越弱(L3)的情况下,检测器的精确度越高(高达 96.7%),因为此时智能体的冲突最“暴力”。
- 修复陷阱:令人惊讶的是,即使把这份诊断报告给“合并 Agent”看,它也无法有效修复代码。为什么?因为知道“错了”并不代表知道“什么是对的”。
只有当提供完整的 L0 规范时,合并 Agent 才能完美恢复到 89% 的准确率。
深度洞察:规范即合同
本文通过 2x2 因子实验,将故障原因拆解为两部分:
- 信息不对称 (+11pp):Agent 看不到构造函数 implementation。
- 协调成本 (+16pp):Agent 即使看到了构造函数,但由于本身偏好太强,依然可能写出不兼容的代码。
这证明了 Parnas 和 Meyer 等软件工程先驱在几十年前提出的理论——Design by Contract(契约式设计) 在 AI 时代依然是真理。对于模型来说,明确的接口约束和内部状态描述,比任何事后的反馈回路都更重要。
结论与展望
这篇文章给当前盲目追求“多智能体框架”的开发者泼了一盆冷水:
- 不要迷信 Agent 之间的对话和反馈:目前的 LLM 在处理这种底层结构冲突时,单纯的交流效果不如一份硬性的“技术规格说明书”。
- 工程建议:在构建代码生成流水线时,应优先增强 Prompt 中关于数据结构(State Access)的描述。
- 未来方向:如何让 Agent 之间进行更深层的语义协商(而非简单的状态合并)将是攻克“规范差距”的关键。
主编点评:本研究最出彩的地方在于其“复古”的视角——用经典的软件架构理论(模块化、信息隐藏)来剖析最前沿的 AI 协作难题。它提醒我们,无论编写代码的主体是谁,软件工程的基本物理定律从未改变。