SpecEyes is an agentic-level speculative acceleration framework designed for Multimodal LLMs (MLLMs) that replaces iterative visual tool-calling loops with a "think fast, think slow" approach. By utilizing a lightweight, tool-free MLLM as a speculative planner, it achieves a 1.1–3.35× speedup and up to a +6.7% accuracy improvement across benchmarks like V* and POPE.
TL;DR
SpecEyes is a breakthrough framework that addresses the "latency explosion" in agentic Multimodal Large Language Models (MLLMs). By introducing a "Think Fast, Think Slow" architecture, it uses a tiny, tool-free model to "speculate" the answer to complex visual queries. If the small model is confident—determined by a new Answer Separability metric—it bypasses the expensive, multi-step tool-calling process entirely. The result? Up to 3.35x faster inference with better-than-baseline accuracy.
The Problem: The "Agentic Depth" Disaster
The current paradigm for advanced MLLMs (like OpenAI o3 or Gemini Agentic Vision) involves "Agentic Reasoning." Instead of looking at an image once, the model performs a loop: Observe -> Reason -> Call Tool (e.g., Zoom) -> Observe again.
While powerful, this creates what the authors call Agentic Depth (D). Because each tool call depends on the previous output, the system suffers from:
- Latency Explosion: Response time grows linearly with the number of tool calls.
- Concurrency Collapse: Traditional GPU batching fails because each query is "stateful" (mutating its own trajectory), leaving hardware parallelism wasted.
Methodology: The Architecture of SpecEyes
SpecEyes transforms the rigid serial pipeline into a Heterogeneous Parallel Funnel.
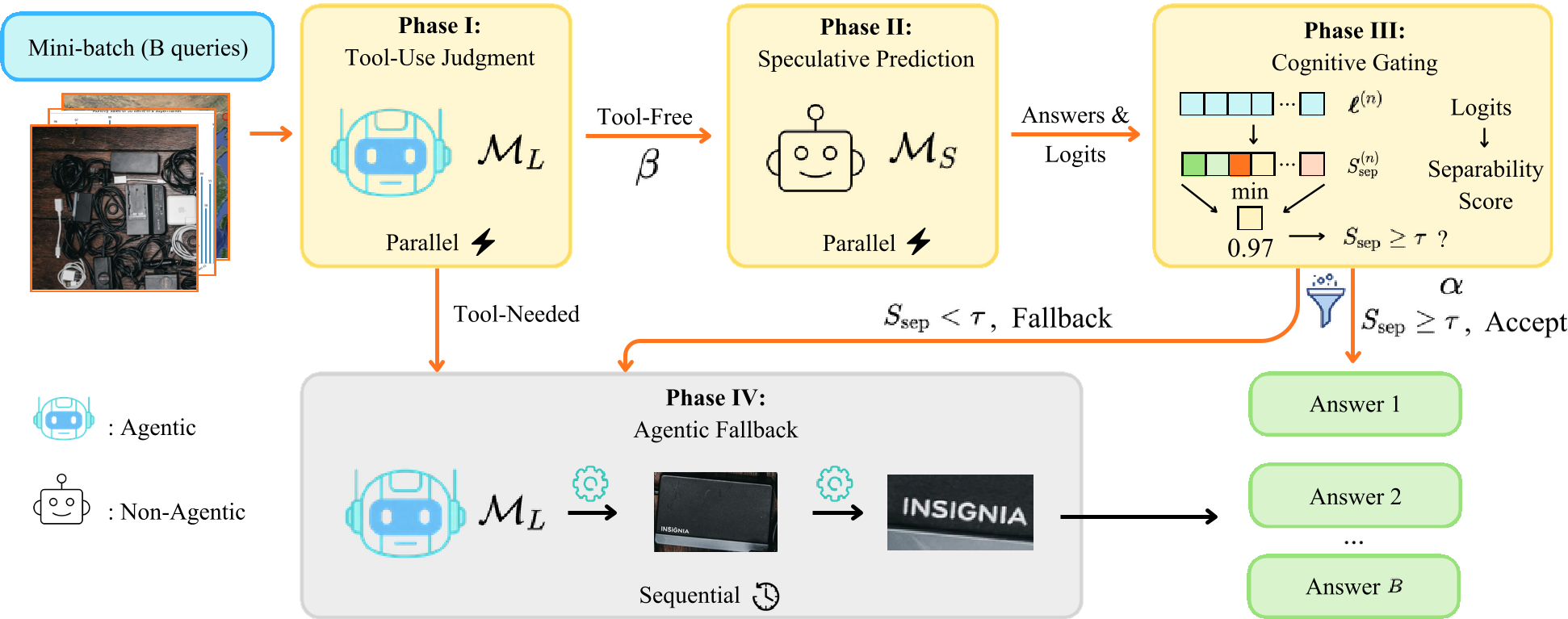
1. Heuristic Screening (Phase I)
The large model ($M_L$) first performs a "vibes check"—a single-token binary classification to see if the query actually needs tools. If the image is simple, it passes to the speculative branch.
2. Speculative Perception (Phase II & III)
A small, tool-free model ($M_S$, e.g., Qwen3-VL-2B) attempts to solve the query in a single pass. To ensure we don't trade accuracy for speed, the authors introduce Cognitive Gating via Answer Separability ($S_{sep}$).
Unlike standard probability (Softmax), which is often overconfident, $S_{sep}$ measures the Decision Margin: $$S_{sep}^{(n)} = \frac{\ell_{[1]}^{(n)} - \mu_K^{(n)}}{\sigma_K^{(n)} + \epsilon}$$ It calculates how far the top predicted token stands apart from its top-K competitors. By using a Min-Aggregation strategy (thresholding the weakest token in a sentence), SpecEyes acts as a "worst-case guard" to prevent hallucinations.
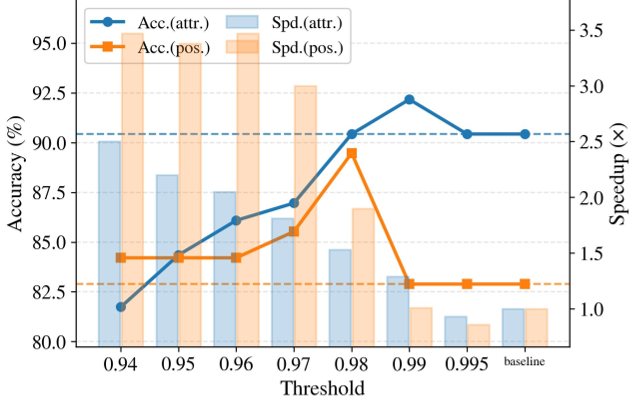 Figure: KDE plots showing that $S_{sep}^{min}$ (c) provides the cleanest separation between correct and incorrect answers compared to standard methods.
Figure: KDE plots showing that $S_{sep}^{min}$ (c) provides the cleanest separation between correct and incorrect answers compared to standard methods.
3. Agentic Fallback (Phase IV)
If $M_S$ is unsure, the system "falls back" to the complex agentic model. Because most queries (avg. 71% in experiments) are accepted by the gate, the heavy model is reserved only for truly difficult cases.
Experimental Performance
The framework was tested on several benchmarks including V Bench* (fine-grained perception) and POPE (hallucination robustness).
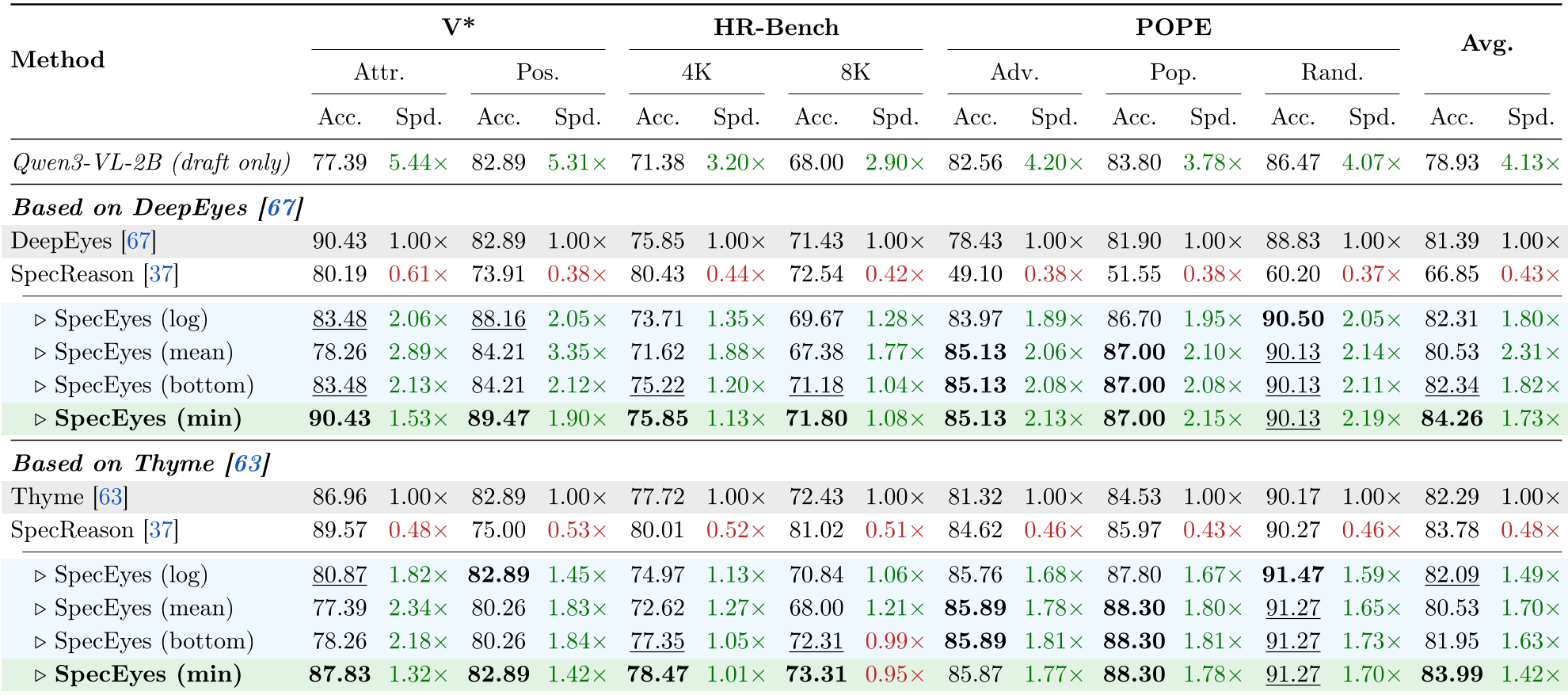
- Speedup: SpecEyes achieved a 1.73x average speedup across all tasks. On spatial reasoning tasks (V* Position), this went as high as 3.35x.
- Accuracy Boost: Interestingly, SpecEyes often outperformed the full agentic baseline (up to +6.7%). This suggests that for some queries, the iterative tool-calling loop actually introduces "noise" or "reasoning drift," and the small model's "intuition" is more robust.
- Throughput: Because the small model is stateless, it can be batched easily. As batch sizes increase, the system-level throughput gain becomes even more pronounced.
Critical Analysis & Insights
Why does this work?
The success of SpecEyes lies in the realization that agentic reasoning is an "overkill" for a significant portion of user queries. By identifying "easy" cases via logit-space separability, we can reclaim the lost hardware efficiency of non-agentic models without losing the "slow thinking" capability of agentic models.
Limitations
The primary bottleneck remains high-resolution benchmarks like HR-Bench. In these cases, the small model (which doesn't use tools like zoom-in) rarely achieves high confidence, meaning most queries still fall back to the slow path. The speedup here is marginal (1.01x - 1.13x).
Future Outlook: Multi-Depth Speculation
The authors suggest that the next step is Multi-Depth Speculation. Instead of just "No Tools" vs "Full Tools," the system could allow the small model to perform 1 or 2 lightweight tool calls before deciding whether to escalate to the massive backbone. This would bridge the gap for high-resolution tasks where a single "glance" isn't enough, but a full 5-step loop is too much.
Conclusion: SpecEyes effectively "unclogs" the pipeline of modern AI agents, making real-time, high-accuracy multimodal interaction a feasible reality for production systems.