本文提出了 SpecEyes,一种针对代理型多模态大模型(Agentic MLLMs)的代理级投机加速框架。通过引入轻量级模型作为投机规划器,并结合基于答案可分性(Answer Separability)的认知门控机制,该方法在保持或提升准确率的同时,实现了 1.1x 至 3.35x 的端到端推理加速。
TL;DR
传统的代理型多模态大模型(Agentic MLLMs)通过不断调用工具(如缩放、OCR)来增强视觉能力,但这种“反复横跳”的循环导致了巨大的延迟。SpecEyes 首次提出在“代理级”进行投机加速:用一个小模型先猜答案,如果猜得够准(通过可信度门控判断)就直接跳过昂贵的工具调用链。实验证明,这种方法能带来最高 3.35x 的加速,甚至能因为减少了冗余步骤而提升 6.7% 的准确率。
背景定位:代理深度的“泥潭”
在视觉推理任务中,模型不再是单次处理图片,而是像人类一样“看一眼、放大看、再读文字”。这种 Agentic 模式虽然强大,却引入了**代理深度(Agentic Depth, D)**的概念。每增加一步工具调用,推理延迟就线性增加;更糟糕的是,工具调用的中间状态导致 GPU 的并行能力(Concurrency)几乎瘫痪,系统级吞吐量面临崩溃。
核心直觉:并不是所有问题都需要“放大镜”
作者敏锐地察觉到:大量用户提问其实非常简单,轻量级的视觉模型(Tool-free)一眼就能看出答案。如果能准确识别出这些“简单题”,直接让小模型处理,就能省去大模型频繁调用工具的巨额开销。
方法论详解:代理级投机漏斗
SpecEyes 构建了一个四阶段的加速漏斗:
- 工具使用启发式判断 (Phase I):由大模型输出一个 Binary Token,快速判断当前任务是否真的需要工具。
- 投机预测 (Phase II):对于无需工具的任务,启动轻量级模型 进行一次无状态的快速预测。
- 认知门控 (Phase III - 核心):本文提出 (Answer Separability) 算法。它不直接看 Softmax 概率,而是衡量 Logit 分布中“第一名”与“竞争对手们”的统计距离。
- 代理回退 (Phase IV):只有当 分数低于阈值时,才会启动完整的大模型代理循环。
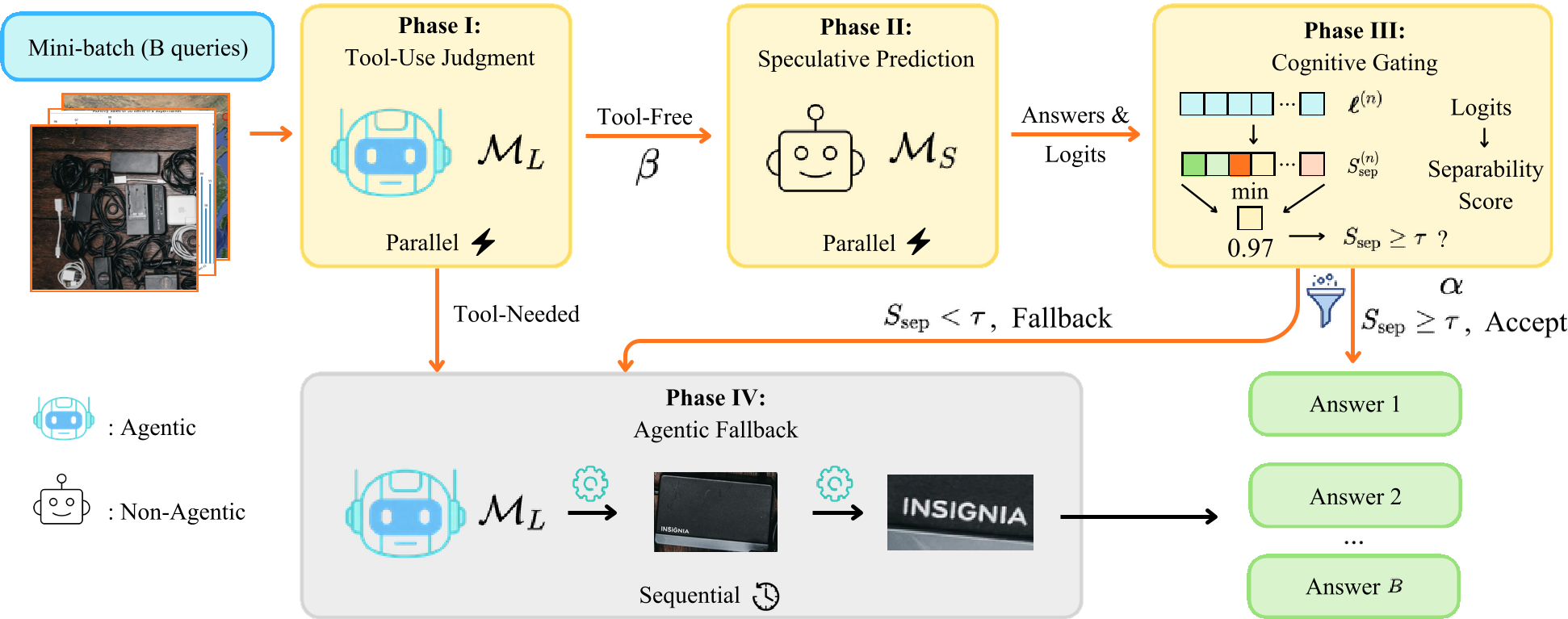 图 1:SpecEyes 运行流水线。通过这种“快慢思考”的异步设计,系统可以将并发任务进行有效分流。
图 1:SpecEyes 运行流水线。通过这种“快慢思考”的异步设计,系统可以将并发任务进行有效分流。
数学直觉:为什么 比 Softmax 更有用?
Softmax 容易产生“过度自信”的偏见。作者提出的答案可分性分数定义为: 这里通过计算前 K 个 Logit 的均值和标准差来标准化领先幅度。这种方法具有尺度不变性,能更真实地反映模型是否在多个候选答案之间犹豫不决。
实验成就
SpecEyes 在 DeepEyes 和 Thyme 两个主流代理框架上进行了验证:
- 速度翻倍:在 POPE 等幻觉测试集上获得了 2x 以上的加速。
- 准确率反超:在 V* Bench 的空间关系任务中,准确率从 82.89% 提升至 89.47%。这说明过度调用工具反而可能引入干扰,适时的“点到为止”更有利于保持逻辑连贯。
- 吞吐量线性增长:随着批处理大小(Batch Size)的增加,小模型的加速优势被进一步放大。
 表 1:在不同基准测试下的性能提升。注意 SpecEyes (min) 策略在维持高准确率的同时提供了最佳加速比。
表 1:在不同基准测试下的性能提升。注意 SpecEyes (min) 策略在维持高准确率的同时提供了最佳加速比。
深度洞察与总结
关键启示:
- 端到端协同:未来的 AI 代理不应只是简单地“串行执行”,而应具备“自我审美”的能力,即对自己产生的推理路径进行实时质量评估,从而实现动态提前退出。
- 异构并行:通过小模型的“快”掩盖大模型的“慢”,是解决 Agent 落地成本问题的实用路径。
局限性:
目前的 SpecEyes 只能在 (不调用工具)和 (完整循环)之间切换。作者在未来展望中提到,**多深度投机(Multi-depth Speculation)**将是下一个前沿——即允许小模型进行 1-2 次廉价的工具调用后再做决定,这能进一步优化类似于 HR-Bench 这种必须依赖高分辨率细节的任务。
总结:SpecEyes 成功将投机推理的概念从微观的 Token 生成扩展到了宏观的任务规划,为构建低成本、高响应速度的多模态 AI 代理提供了清晰的路线图。