本文推出了 daVinci-MagiHuman,一个开源的音视频统一生成基座模型。该模型采用单流 (Single-Stream) Transformer 架构,通过统一的 Token 序列同时处理文本、视频和音频,在人像生成(如面部表情同步、多语种口型配合)方面达到了 SOTA 水平。
TL;DR
在视频生成领域,音画同步一直是个难题。daVinci-MagiHuman 另辟蹊径,抛弃了复杂的多流融合设计,采用单流 (Single-Stream) Transformer 统一处理文本、视频和音频。这不仅实现了人像生成的极高表现力(WER 14.6%),更在 H100 上跑出了“生成 5 秒高清视频仅需 38 秒”的极速。
背景定位:从“拼接”走向“融合”
传统的音视频生成模型(如早期的 Ovi 系列)就像是把两个独立的引擎(一个生成视频,一个生成音频)通过“跨模态注意力 (Cross-Attention)”强行焊在一起。 这种设计面临两个痛点:
- 时空对齐难:视频和音频的时间分辨率完全不同,焊点越多,出错概率越高,容易出现“对不上口型”的问题。
- 工程开销大:多分支架构在 GPU 上会导致严重的算子碎片化,效率低下。
daVinci-MagiHuman 的核心直觉是:既然 Transformer 是通用函数拟合器,何不将所有模态视为同一序列?
核心方法:单流架构的“三板斧”
1. 三明治式布局 (Sandwich Architecture)
模型包含 40 层 Transformer。为了平衡模态特性与统一学习,作者设计了“外专内共”的结构:
- 头部与尾部(各 4 层):保留模态敏感的 Projection 和 RMSNorm 路径,负责将异构数据映射到统一空间。
- 中间躯干(32 层):所有模态共享权重。这种深度融合让模型能真正理解“什么样的频率对应什么样的面部肌肉收缩”。
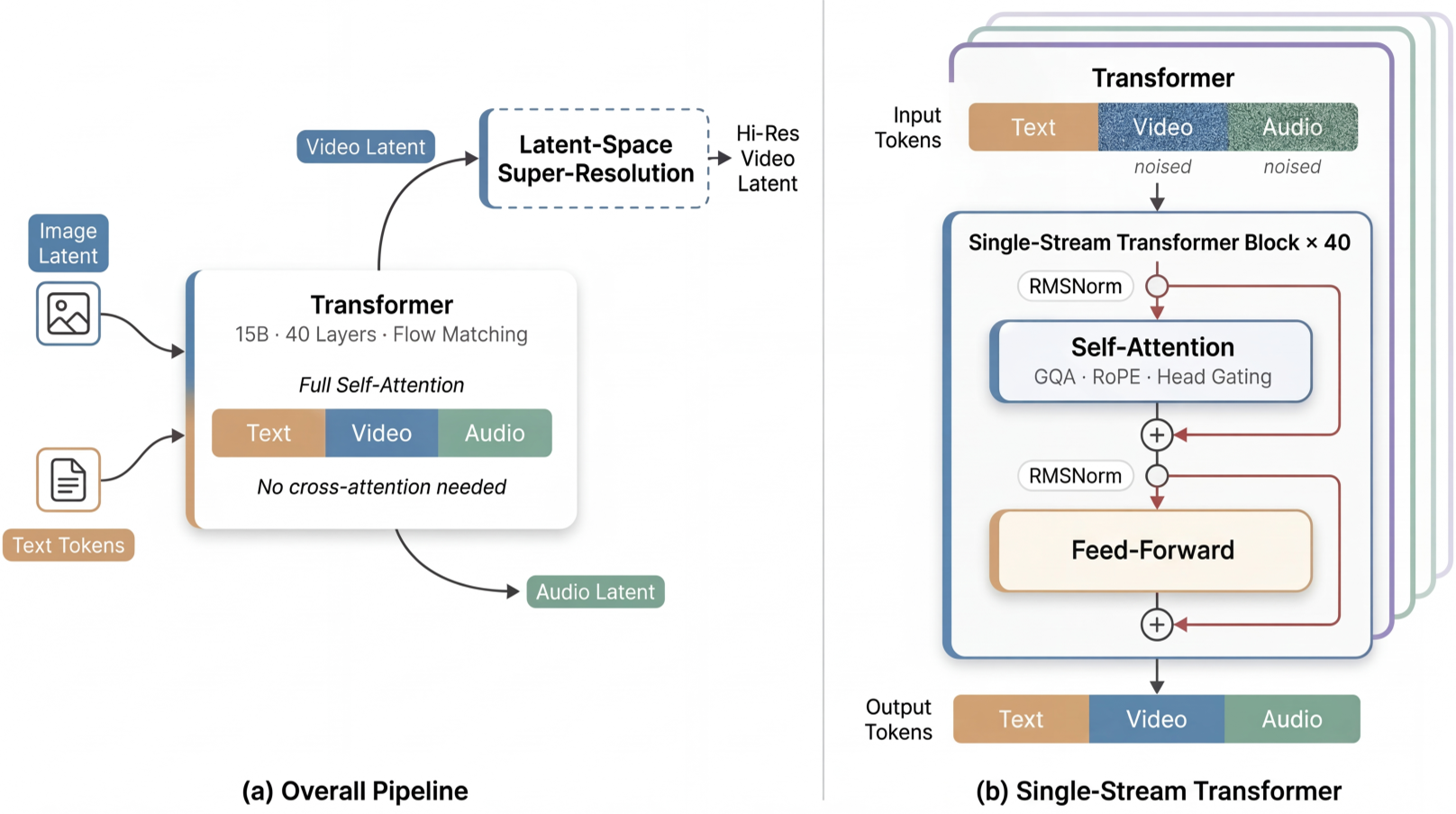
2. Timestep-Free 与 Gated Attention
不同于传统的 DiT 需要显式注入扩散步数(Timestep),daVinci-MagiHuman 直接从输入的噪声 Latent 中感悟当前的降噪进度。此外,引入了 Per-Head Gating 机制,通过学习每一头注意力的标量权重,显著抑制了长序列训练中的数值震荡(Numerical Instability)。
3. 两阶段推理:Latent SR 与 Turbo VAE
为了在高分辨率下保持速度,模型先生成 256p 的低分辨率 Latent,再通过潜空间超分辨率 (Latent-Space SR) 进行细化。配合专门优化的 Turbo VAE,解码延迟大幅降低,满足了实时交互的需求。
实验结果:开源界的顶级战力分析
在学术界最担心的语音清晰度 (Speech Intelligibility) 方面,daVinci-MagiHuman 将词错误率 (WER) 压低至 14.60%,远超之前的 SOTA 模型 LTX 2.3 (19.23%)。

在人类主观评测中,针对 Ovi 1.1 的胜率高达 80.0%,这说明在口型对齐、面部肌肉微表情、身体语言自然度这三个“人像生成”的高地,单流架构展现出了压倒性的感官优势。
深度洞察与总结
单流架构的胜利标志着多模态统一基座的成熟。 daVinci-MagiHuman 的局限性在于其主要针对人像(Human-centric)进行了优化,在复杂的自然场景或多物体交互中的物理一致性(Physical Consistency)评分略低于 LTX 2.3。
启示: 当模型的 Scaling Law 进入下半场,**“架构的简洁性”往往比“模块的多样性”**更重要。对于开发者而言,daVinci 全栈开源的 base 和 distilled 模型组合,为下游社交媒体、虚拟数字人、游戏剧情生成提供了极佳的工具链。
未来,我们有望看到这种单流架构在多模态实时对话(如同 GPT-4o 的交互感)中发挥更大的作用。