本文提出了 SPPO (Sequence-Level PPO),一种旨在对齐大语言模型 (LLM) 推理能力的强化学习算法。通过将推理任务重构为“序列级上下文老虎机”(Sequence-Level Contextual Bandit) 问题,SPPO 在保持高训练吞吐量的同时,解决了长思维链 (CoT) 中的奖励分配不均问题。
TL;DR
在强化学习对齐大模型的道路上,PPO 的稳定性和 GRPO 的效率一直难以平衡。本文提出的 SPPO (Sequence-Level PPO) 突破性地将推理任务建模为序列级上下文老虎机 (Contextual Bandit)。它不仅解决了标准 PPO 在长思维链 (CoT) 中的价值估计失效问题,还通过单样本训练实现了比 GRPO 高 5.9 倍的吞吐量,甚至支持用 1.5B 的小模型作为“批判者”来训练 7B 的大模型。
1. 痛点:为何标准 PPO 在长 CoT 中会“失效”?
标准 PPO 采用的是 token 级的回归任务。在一个包含数千 token 的推理任务中,奖励往往极其稀疏(只有最后做对了才是 +1)。
作者发现了一个致命的**“尾部效应 (Tail Effect)”**:
- Critic 无法区分中间过程:在推理的中早期,Critic 模型给出的价值估计 (Value Estimate) 是纠缠在一起的,无法区分正确路径和错误路径。
- Advantage 信号消失:对于正确的轨迹,Critic 往往在末尾才后知后觉地提高预测值。当 计算出的 Advantage 趋于 0 时,模型就失去了继续优化的动力。
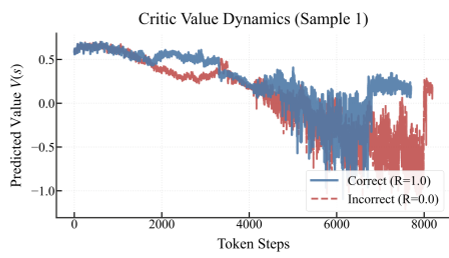 上图显示,只有到序列末尾,正确(蓝色)和错误(红色)路径的 Value 才开始分离。
上图显示,只有到序列末尾,正确(蓝色)和错误(红色)路径的 Value 才开始分离。
2. 核心直觉:从 MDP 到上下文老虎机
作者提出了一个大胆的假设:既然奖励是结果导向且稀疏的,为什么要强迫模型进行 token 级的步步拆解?
SPPO 将整个推理过程视为一个原子动作 (Atomic Action)。在这种架构下:
- Context:仅取决于输入的 Prompt ()。
- Action:整个生成的 Response 序列。
- Value Function:不再预测每一个 token 的期望收益,而是预测这个 Prompt 被解出的概率(标量值)。
通过这种方式,原本极其复杂的时长 (Horizon) 被坍缩为 1。Advantage 信号被均匀地分配给序列中的每一个 token,确保对成功的逻辑链进行整体强化,对失败的链进行整体惩罚。
3. SPPO 的算法实现
SPPO 的优势在于它不仅保留了 PPO 的采样效率(样本利用率高),还引入了类似 GRPO 的稳定性。
标量 Advantage 计算
SPPO 训练一个标量 Critic ,其目标函数采用二元交叉熵 (BCE),这比传统的 MSE 损失更能抵抗 LLM 训练中的离群值:
架构图示
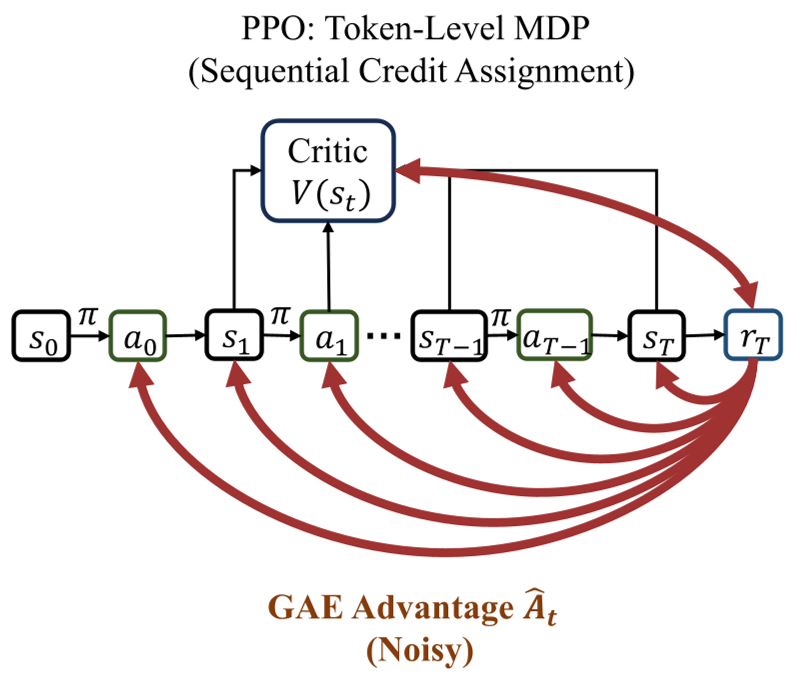 相比 token 级 PPO 的波动,SPPO 广播统一的标量 A,不受序列长度 T 的影响。
相比 token 级 PPO 的波动,SPPO 广播统一的标量 A,不受序列长度 T 的影响。
4. 实验战绩:效率与性能的双重飞跃
在 AIME24/25 和 MATH500 等硬核数学竞赛题上,SPPO 展现了极其强悍的竞争力:
- 1.5B 模型:SPPO 平均得分 48.06,超过了 GRPO (47.08) 和标准 PPO (44.06)。
- 7B 模型:SPPO 同样保持领先,且在收敛速度上降维打击。
训练效率对比
由于 SPPO 支持单样本更新 (N=1),而 GRPO 通常需要 8 个样本来估计基准,SPPO 的训练速度提升了接近 6 倍。
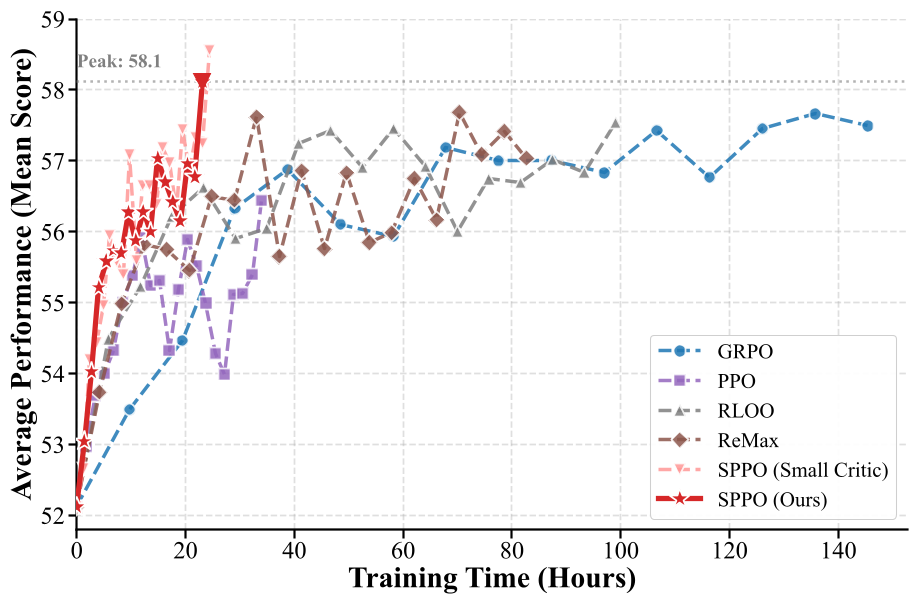 在 22 小时内,SPPO 就达到了 7B 模型的最优性能,而其他方法仍处于爬坡期。
在 22 小时内,SPPO 就达到了 7B 模型的最优性能,而其他方法仍处于爬坡期。
解耦 Critic:用 1.5B 训练 7B
这是本文最吸引工程界的一点。SPPO 证明了:由于 Critic 只需判断问题的“难易度”而非生成逻辑,因此可以使用一个极小的 Critic 模型(如 1.5B)来对齐 7B 的 Actor。
- 显存节省:减少 12.8% 的 Peak VRAM。
- 性能不减:7B Actor + 1.5B Critic 的组合甚至拿下了最高的平均分 (58.56)。
5. 总结与启示
SPPO 的成功告诉我们:在长程推理任务中,与其深陷 token 级的细粒度信用分配泥潭,不如退后一步进行序列级的宏观对齐。
这款算法为资源受限的研究团队提供了一个新范式:
- 不再需要极大的 Batch Size 或昂贵的组采样。
- 小模型 Critic 指导大模型 Actor 的可行性,降低了算力门槛。
局限性:SPPO 强烈依赖于“可验证奖励 (Verifiable Rewards)”,对于无法自动判分的开放式写作任务,如何构建稳健的序列级基准仍是一个开放性课题。
本文由资深学术总编重构。