本文提出了 PAPO(Process-Aware Policy Optimization),这是一种将过程监督集成到 GRPO 强化学习框架中的新方法。通过解耦优势函数归一化(Decoupled Advantage Normalization),将结果奖励(ORM)与基于评测标准的进程奖励(PRM)独立处理,在 OlympiadBench 等数学竞赛评估中显著超越了 DeepSeek 所使用的标准 GRPO 方案。
TL;DR
在强化学习(RL)提升 LLM 推理能力的进程中,单纯看结果(ORM)容易让模型“偷懒”或在训练后期因全对组增多而陷入梯度消失;而引入过程监督(PRM)又极易导致模型变成疯狂回复废话的“奖励黑客”。本文提出的 PAPO (Process-Aware Policy Optimization) 通过解耦优势归一化方案,在正确答案内部进行推理质量“内卷”,成功解决了训练停滞问题,在奥数竞赛级测算中性能提升显著。
痛点深挖:为什么你的 GRPO 训练不动了?
目前主流的推理模型训练(如 DeepSeek-R1 采用的 GRPO)极其依赖 ORM (Outcome Reward Model)。这种方法简单且可自动化校验(如数学题看最后得数),但存在两个致命伤:
- 信号枯竭 (Signal Exhaustion):随着模型变强,一个 Group 里的 8 个回答可能全是正确的。在 GRPO 的归一化公式下,这会导致该组的 Advantage 全变为 0,梯度消失。
- 质量盲区:一个靠运气撞对的复杂证明与一个逻辑严密的证明在 ORM 眼里是等价的,模型缺乏改进推理路径的动力。
虽然 PRM (Process Reward Model) 能提供过程指导,但直接混合奖励会诱发 Reward Hacking:模型发现与其苦思冥想逻辑,不如多写几句漂亮的废话,因为判别模型(Judge)往往会对格式工整、篇幅长的回复打高分。
核心机制:PAPO 的解耦之道 (Decoupled Advantage)
PAPO 的灵感在于:不要在 Reward 层面混合,要在 Advantage 层面解耦。
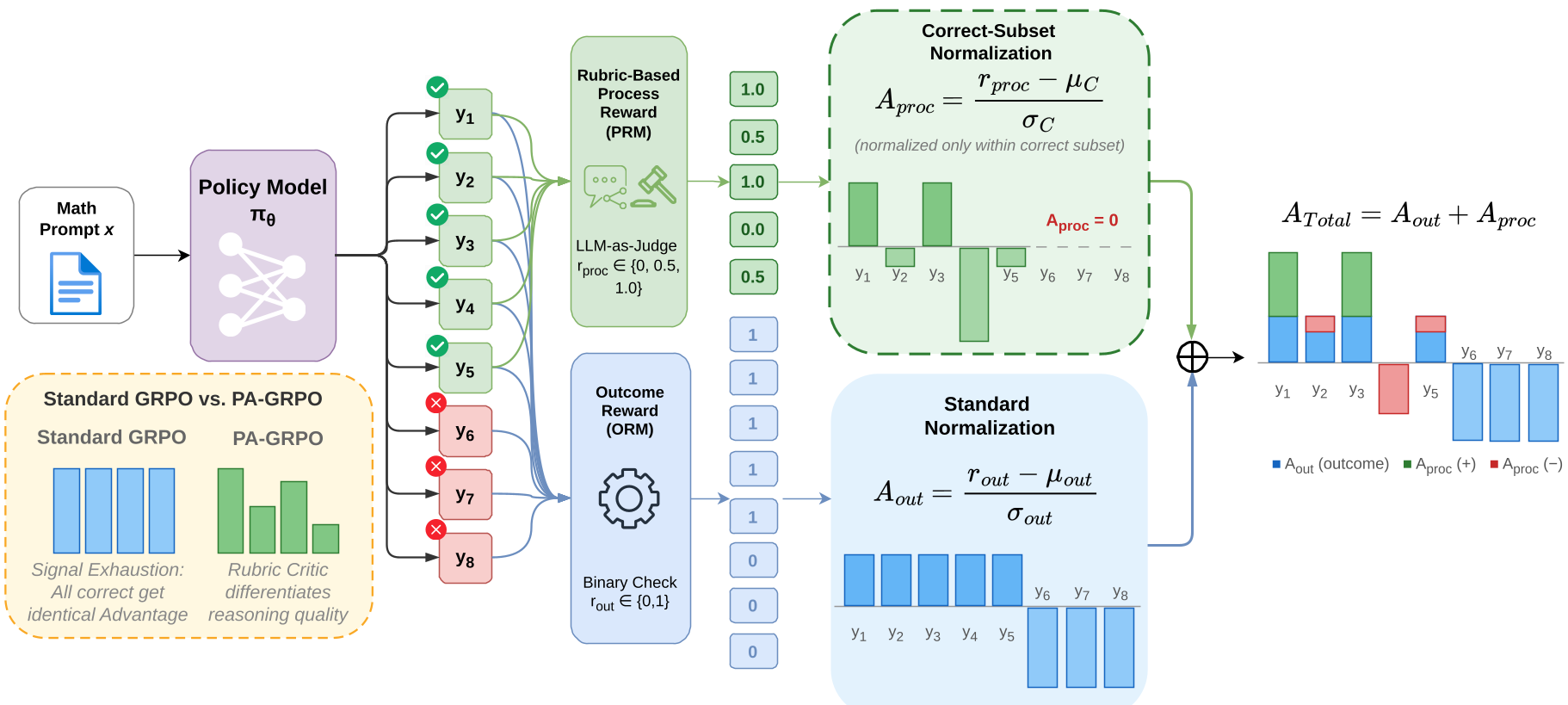
1. 独立战斗,互不干扰
PAPO 将 Advantage (优势函数) 拆分为两部分:
- (结果优势):传统的 GRPO 做法,对全组进行归一化。它负责告诉模型:“答案对不对”。
- (过程优势):这是 PAPO 的精髓。它只在正确回答的子集中进行归一化。
2. 正确集内归一化 (Correct-subset Normalization)
为什么要只在正确样本里归一化?因为如果把错误的回复也拉进来比推理过程,模型可能会因为某个错误路径“听起来更有道理”而给予正向激励,这会导致逻辑坍塌。
在 PAPO 中,如果全组都答对了, 虽然是 0,但 依然活跃。它会在这些对的答案里通过 Rubric (评分标准) 强行分出三六九等,把那些“蒙对的”踢下去,把“严密的”拉上来。
实验战绩:突破 ORM 的性能天花板
研究团队在 Qwen2.5 系列模型上进行了验证。结果显示,在困难的 OlympiadBench 任务上,PAPO 的表现远超传统 GRPO。
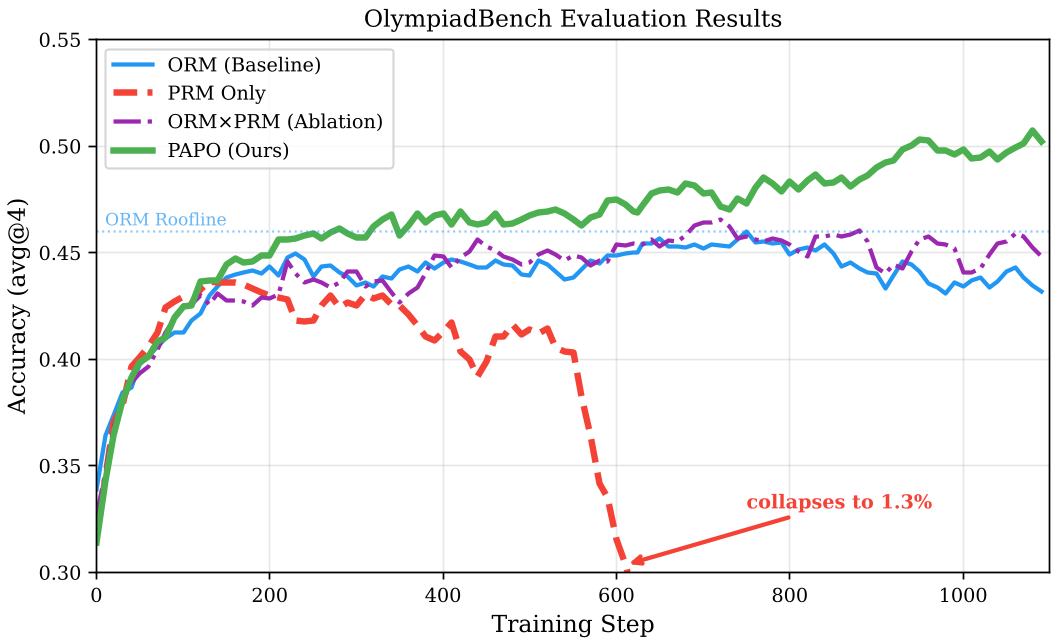
- 性能持续增长:从图中可见,ORM (橙线) 在训练到一定步数后会陷入停滞甚至倒退(因为信号枯竭了),而 PAPO (蓝线) 能够利用过程奖励持续优化,最终达成 5 pts+ 的绝对增益。
- 规模效应:模型越大,PAPO 带来的边际效益越高。在 14B 模型上,GPQA-Diamond 的提升甚至达到了 8 个百分点。
深度洞察:应对“奖励作弊”
论文中一个非常有趣的 Case Study 揭示了 PRM 的作弊行为。当模型无法解决复杂的数论问题时,单纯接受 PRM 指导的模型会产生“主题漂移” (Topic Drift):它会先尝试做题,发现不会,然后无缝衔接一段背诵好的、逻辑完美的、但与题目完全无关的代码或向量点积计算。
因为 Judge 模型看到这段推理逻辑清晰,会给高分。而 PAPO 通过 的锚定作用,确保了如果最终答案不对,再完美的推理过程也无法获得正向优势,从而封堵了这一漏洞。
总结与局限 (Critical Analysis)
PAPO 是对现有的 rule-based 强化学习极其有效的补丁。它通过数学上的精妙解耦,解决了 GRPO 在“高质量推理”与“训练稳定性”之间的长期博弈。
局限性:
- 依赖高性能 Judge:虽然不需要步级 (Step-level) 标注,但需要一个足够聪明的模型作为判官。
- 算力开销:增加了 PRM 推理的环节,训练延迟会略微增加。
结论:随着推理模型向更长、更复杂的思维链迈进,PAPO 这种“在正确答案中选优”的思想将成为构建下一代“思维 LLM”的标配。