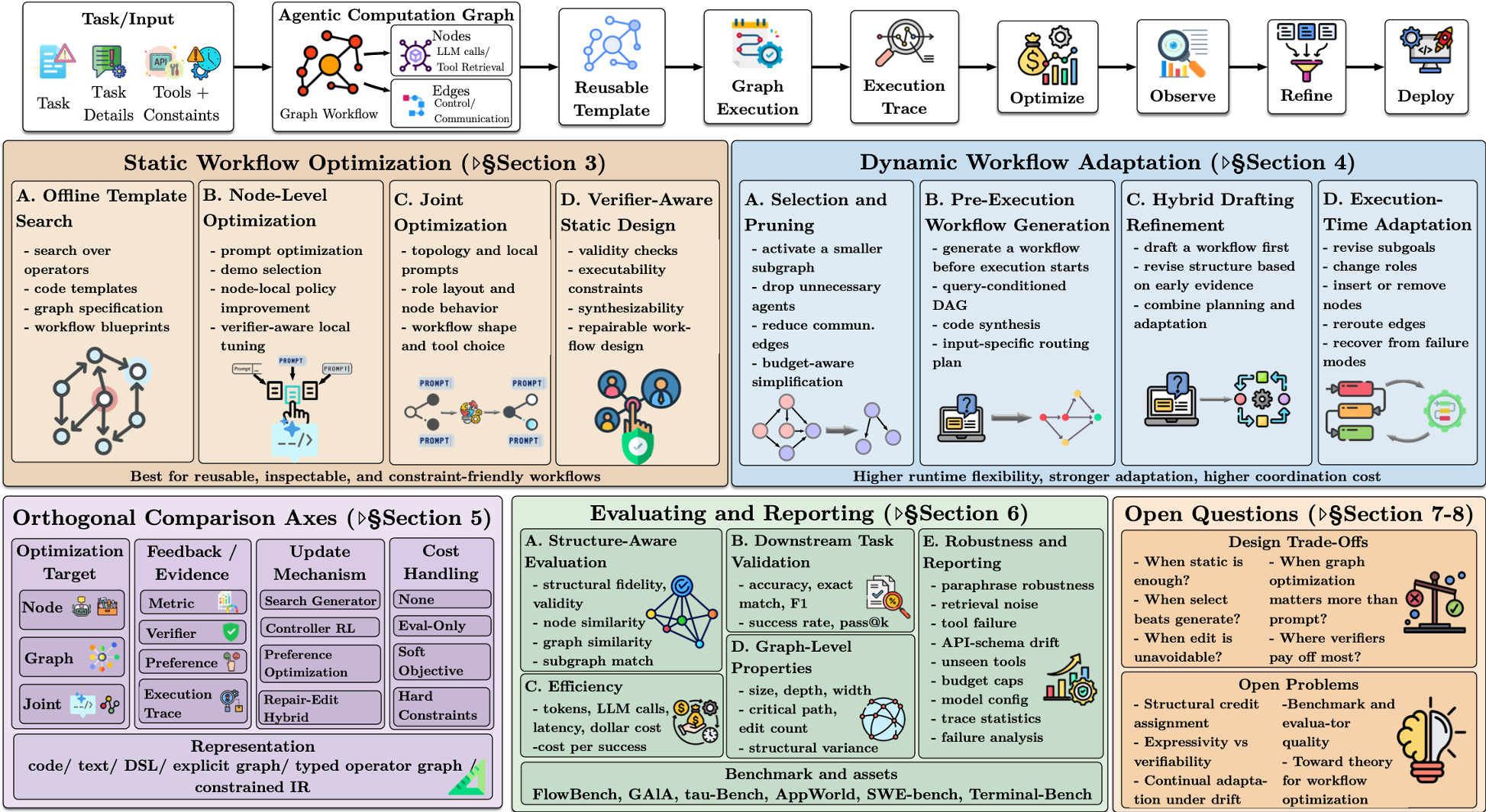
This survey introduces the concept of Agentic Computation Graphs (ACGs) to unify various LLM-based systems into a structural optimization framework. It categorizes methods like AFlow and ADAS into a taxonomy of Static and Dynamic workflow optimizations, establishing new SOTA standards for how agentic structures should be searched, generated, and evaluated.
TL;DR
The "Wild West" of LLM agent design is finally getting a map. This seminal survey moves beyond simple prompt engineering to treat agent workflows as Agentic Computation Graphs (ACGs). By distinguishing between static templates (optimized offline) and dynamic graphs (generated at runtime), the authors provide a rigorous framework for optimizing how LLMs, tools, and verifiers collaborate.
Core Insight: The secret to SOTA performance isn't just a better LLM; it's a better structure—one that can prune itself for easy tasks and rewrite its own logic for hard ones.
The Structural Pain Point: Why Prompts Aren't Enough
Most developers treat agentic workflows as fixed code scaffolds. You write a "Plan -> Execute -> Verify" loop and hope for the best. However, as the paper points out, this leads to "brittle structural assumptions."
If your retrieval fails and your template doesn't have a "Retry" node, a better prompt won't save you. If your task is simple but your workflow is a 10-agent powerhouse, you are wasting tokens. The industry has lacked a way to optimize these topologies—until now.
Methodology: The ACG Hierarchy
The paper introduces a clean abstraction: Template Realized Graph Trace.
- ACG Template (): The reusable blueprint.
- Realized Graph (): The specific structure deployed for a single query (might be a subset of the template).
- Execution Trace (): What actually happened (the logs).
The Taxonomy of Plasticity
The authors organize the field into two major hemispheres:
- Static Optimization: You search for the "perfect" reusable template (like AFlow or DSPy) before the user even types a query.
- Dynamic Optimization: The agent creates or edits its own workflow on the fly.
- Select/Prune: Activating only needed agents (e.g., Adaptive Graph Pruning).
- Pre-execution: Drawing a map before starting (e.g., Assemble Your Crew).
- In-execution: Changing the engine while the car is moving (e.g., MetaGen).
Key Experimental Insights: Quality vs. Cost
The paper defines the "Quality-Cost" view through a schematic formula: where is task success and is cost (tokens, time, money).
When to use what?
- Static is enough when the task is repetitive and the evaluator is reliable (e.g., Code Gen).
- Selection beats Generation when the tasks vary in difficulty but not in fundamental logic.
- Editing is unavoidable in high-uncertainty environments where you only learn what to do next after a tool fails.
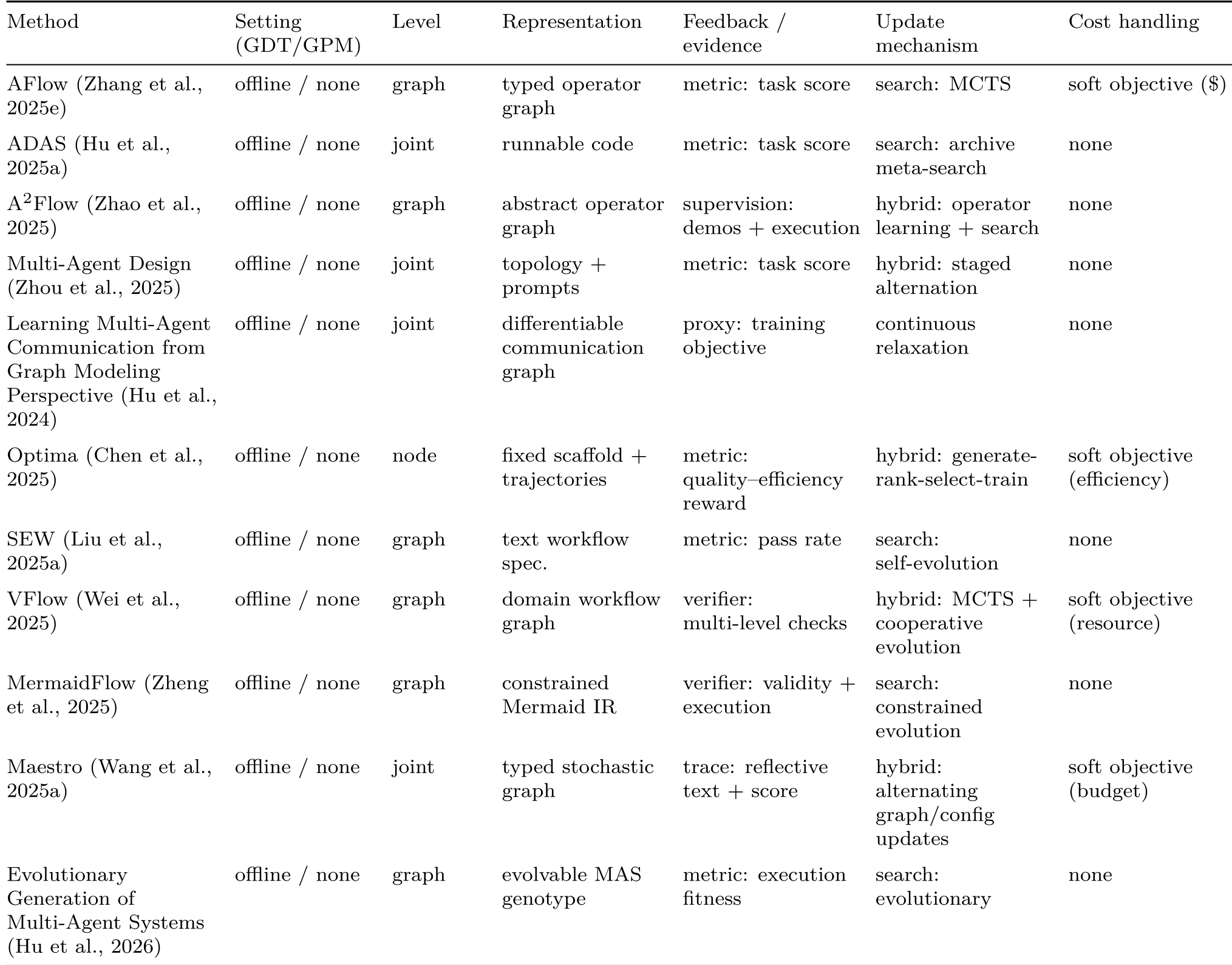
Critical Analysis: The Evaluation Gap
The survey's most aggressive (and necessary) contribution is the Minimum Reporting Protocol. The authors argue that reporting "Accuracy" is no longer enough. If a paper claims a 5% gain, we need to know:
- Graph-level metrics: How many nodes? How much communication volume?
- Structural variance: Did the agent use the same graph every time, or did it adapt?
- Ablation: Was the gain from the "smart" new node or just more compute?
Takeaway for the Future
We are moving toward "Architectural Plasticity." Future LLM systems won't be static bots; they will be fluid "Computation Graphs" that reshape themselves for every dollar spent and every error encountered.
Key Research Front: Structural Credit Assignment. How do we know exactly which edge in a 50-node graph caused the failure? Solving this will be the "Backpropagation" moment for agentic workflows.
Note: This survey identifies 77 core papers and is a must-read for anyone building production-grade LLM Orchestrators.