The paper introduces a unified stochastic thermodynamic framework for non-Markovian autoregressive models, including Transformers, RNNs, and Mamba. It defines "entropy production" (EP) as a measure of temporal irreversibility, providing an efficient Monte Carlo estimation method that circumvents the exponential sampling costs usually associated with non-Markovian systems.
TL;DR
Is a Large Language Model (LLM) a reversible machine? While we read text from left to right, the "arrow of time" in a model's logic is rarely quantified. This paper by Takahiro Sagawa (University of Tokyo) introduces a rigorous bridge between Stochastic Thermodynamics and Generative AI. By defining Entropy Production (EP) for models like Llama, GPT, and Mamba, we can now "calculate" the irreversibility of a sentence—potentially revealing how well a model understands causality versus mere syntax.
The Core Insight: Harnessing Deterministic Memory
In physics, calculating entropy production for non-Markovian processes (where the future depends on the entire past) is a nightmare—it usually requires "infinite" data.
However, Sagawa realizes that modern AI architectures (Transformers, RNNs, SSMs) have a unique property: Deterministic Latent States. Even though the output sequence is non-Markovian, the "summary" of the past (the hidden state ) is updated deterministically. This allows us to evaluate the probability of a reversed sequence without needing to sample every possible history.
Methodology: The Backward Process
The author defines a Backward Process that reuses the same "machinery" (the weights and attention mechanisms) but feeds them tokens in reverse order.
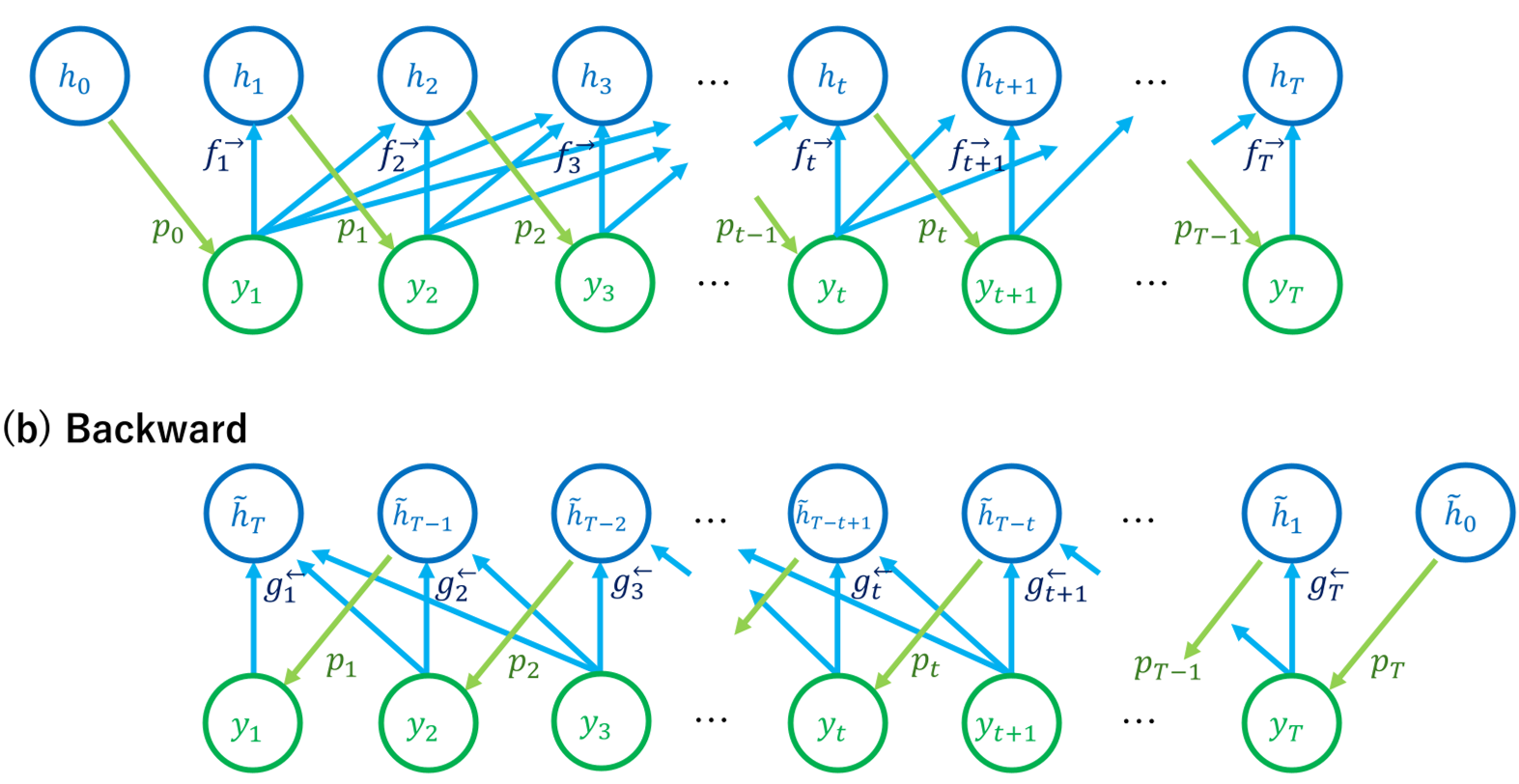 Figure 1: Comparison of Forward (causal) and Backward (anti-causal) dependencies in autoregressive generation.
Figure 1: Comparison of Forward (causal) and Backward (anti-causal) dependencies in autoregressive generation.
The Entropy Production is defined as the KL-Divergence between these forward and backward path measures:
Experimental Proof: GPT-2 and the Logic of Causality
The most striking part of the study is the experiment on GPT-2. The author compares two types of text:
- Causal Texts: Events with a clear temporal chain (e.g., "The glass fell... It broke...").
- Non-Causal Texts: Independent facts (e.g., "A violin is played with a bow... A drum is played by striking it...").
The "Syntax Artifact" vs. Meaning
If you reverse text token-by-token, you get gibberish ("broken glass" becomes "ssalg nekorb"), which is syntactically impossible. This creates a massive, but uninformative, entropy spike. To solve this, Sagawa uses Temporal Coarse-Graining: reversing the order of sentences but keeping the words inside the sentences in the right order.
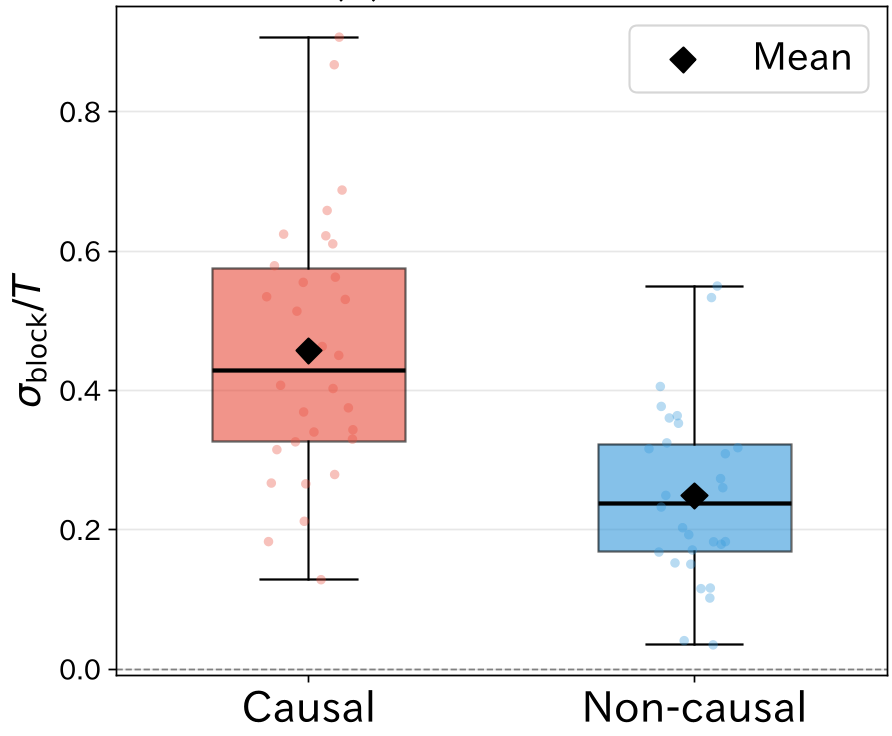 Figure 2: Block-level entropy production for Causal (red) vs. Non-Causal (blue) texts. Causal sequences show significantly higher irreversibility.
Figure 2: Block-level entropy production for Causal (red) vs. Non-Causal (blue) texts. Causal sequences show significantly higher irreversibility.
The result? Causal texts have a significantly higher Entropy Production. The model "senses" that it is far more likely for a glass to fall before it breaks than the other way around.
Theoretical Elegance: The Retrospective Decomposition
The paper goes beyond empirical observation to provide a "Refined Second Law" for AI. It decomposes the loss of information into:
- Compression Loss (): Information lost because the latent state is a finite-size summary of an infinite past.
- Model Mismatch (): The error caused by trying to use a forward-trained "brain" to predict the past.
This suggests that a "perfect" world model would minimize compression loss, retaining exactly the right sufficient statistics to understand the flow of time.
Deep Insight: Why This Matters
Traditionally, we evaluate LLMs using "Perplexity"—how well they predict the next word. But Perplexity doesn't tell us if the model understands the direction of reality.
Sagawa’s framework provides a thermodynamic metric for Causal Reasoning. If a model shows high entropy production on a causal chain, it "knows" that time's arrow matters. As we move toward World Models (like Sora or autonomous agents), this thermodynamic perspective could become a standard tool for measuring how "grounded" a model is in the irreversible laws of our physical world.
Conclusion
This paper is a masterclass in interdisciplinary research. It takes a bridge from the 1990s (Crooks Fluctuation Theorem) and extends it to the cutting-edge AI of 2026. It reminds us that even "virtual" minds are subject to the laws of information and irreversibility.
Takeaway: The arrow of time in an LLM isn't just about the sequence of tokens; it's a measurable thermodynamic quantity that reflects the model's internal understanding of the world's causal structure.