本文提出了一个基于随机热力学(Stochastic Thermodynamics)的统一理论框架,用于量化自回归生成模型(如 Transformer, RNN, Mamba, Kalman 滤波器)在序列生成过程中的时间不可逆性。作者引入了熵产生(Entropy Production, EP)作为核心指标,并证明了尽管这些模型具有强非马尔可夫(Non-Markovian)特性,其 EP 仍可高效估算,无需指数级采样成本。
TL;DR
本文为自回归生成模型建立了一套“随机热力学”标准。通过定义路径概率的物理不可逆性(熵产生),作者证明了我们可以像计算损失函数一样轻松地测量 GPT-2 等模型在生成文本时的“时间箭头”。研究发现,单纯反转单词顺序只会产生语法的噪音,而反转句子顺序则能揭示模型对因果逻辑的感悟。
1. 背景:当 AI 遇上物理学
自回归模型(Autoregressive Models)的核心是“预测未来”:给定过去,预测下一个 Token。从物理学视角看,这是一个典型的时间非对称过程。然而,由于这些模型通常具有长程依赖(Non-Markovian),传统的随机热力学工具因计算量巨大而难以介入。
东京大学的 Takahiro Sagawa 教授在这篇论文中打破了这一僵局。他指出:所有主流自回归架构,本质上都是“从确定性摘要中进行随机发射”的装置。
2. 核心直觉:确定性潜状态的妙用
为什么 Transformer 或 RNN 的熵产生(Entropy Production, EP)可算?
在物理实验中,计算非马尔可夫过程的 EP 通常要求你知道所有过去状态的条件概率,这在数据上是不可行的。但自回归模型(如图 1 所示)有一个精妙的特性:
- 潜状态 是确定的:只要输入序列固定, 就是唯一的。
- 发射核 是显式的:Softmax 输出直接给出了正向概率。
作者通过构造一个“协议反转”的后向过程,将 EP 定义为: 这意味着,计算一个 LLM 的“物理熵产生”,只需要两次推理:一次算正向生成的概率,一次把序列倒过来喂给模型算后向概率。
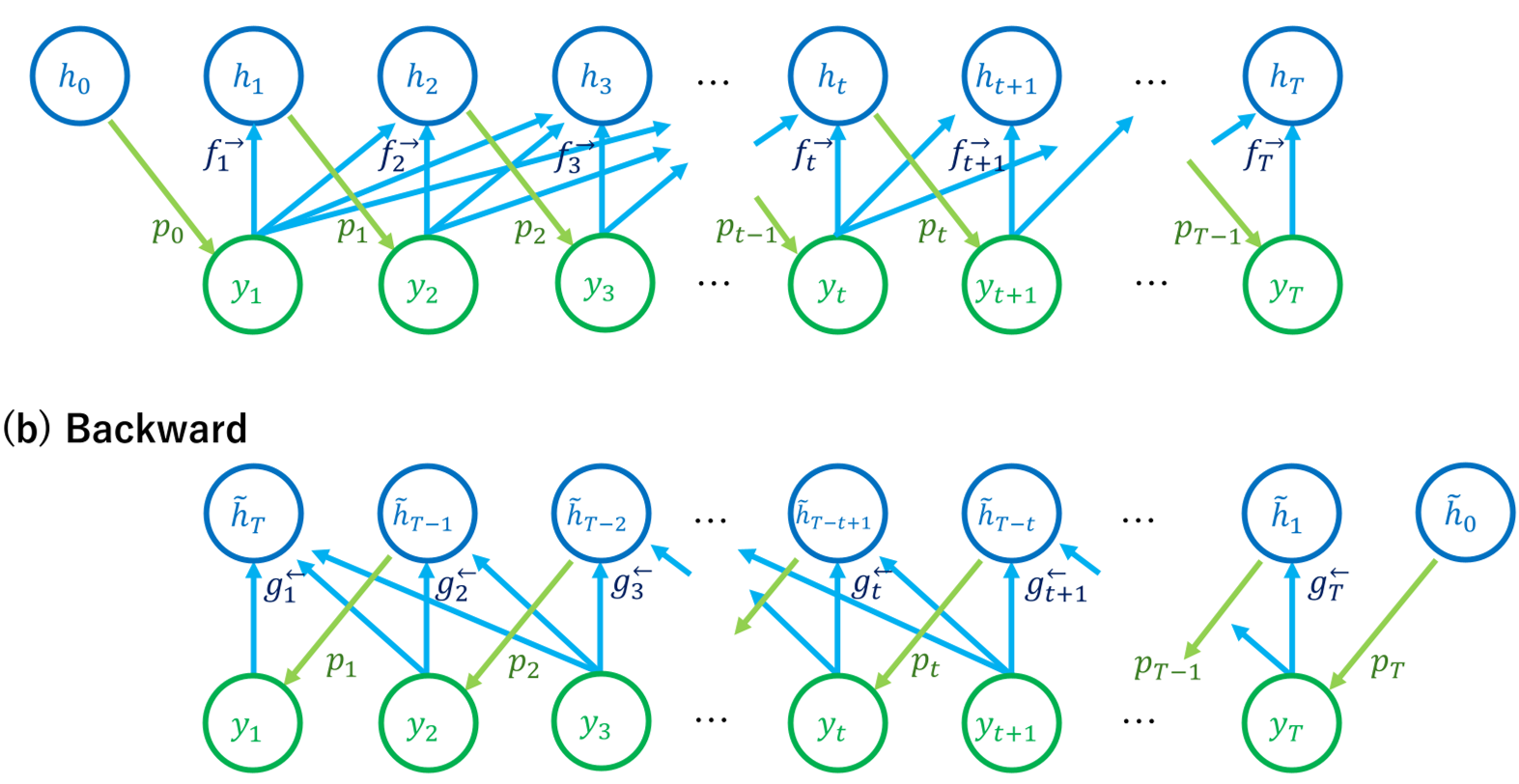 图 1:前向过程(a)与后向过程(b)的因果依赖关系。注意后向过程并非简单的贝叶斯回溯,而是物理意义上的协议反转。
图 1:前向过程(a)与后向过程(b)的因果依赖关系。注意后向过程并非简单的贝叶斯回溯,而是物理意义上的协议反转。
3. 跨架构的统一:从 Kalman 到 Mamba
论文展现了极高的学术品味,将看似无关的模型纳入同一框架(见下表):
| 模型类型 | 潜状态 | 更新机制 | 递归性 | | :--- | :--- | :--- | :--- | | Transformer | Attention Context | 全序列映射 | × (非递归) | | RNN / LSTM | Hidden State | | √ (递归) | | Mamba | Selective SSM State | 输入感知的线性系统 | √ (递归) | | Kalman Filter | 预测器 | 线性更新 | √ (递归) |
对于线性高斯系统(Kalman Filter),作者推导出了 EP 的解析解,并证明了多变量系统的 EP 随时间线性增长,标志着真正的物理不可逆性。
4. 实验洞察:句子反转揭示因果
作者对 GPT-2 进行了深度探测。直接反转单词顺序(如 "Book a is this")会导致极大的 EP,但这只是“语法垃圾”导致的。
更有趣的是“粗粒化反转”: 作者保持句子内部单词顺序不变,只反转句子的先后顺序。
- 因果文本(如:落地 -> 破碎 -> 清扫):反转后 EP 显著升高,因为“效果先于原因”在模型看来极度不自然。
- 非因果文本(如:独立的事实罗列):反转后 EP 较低。
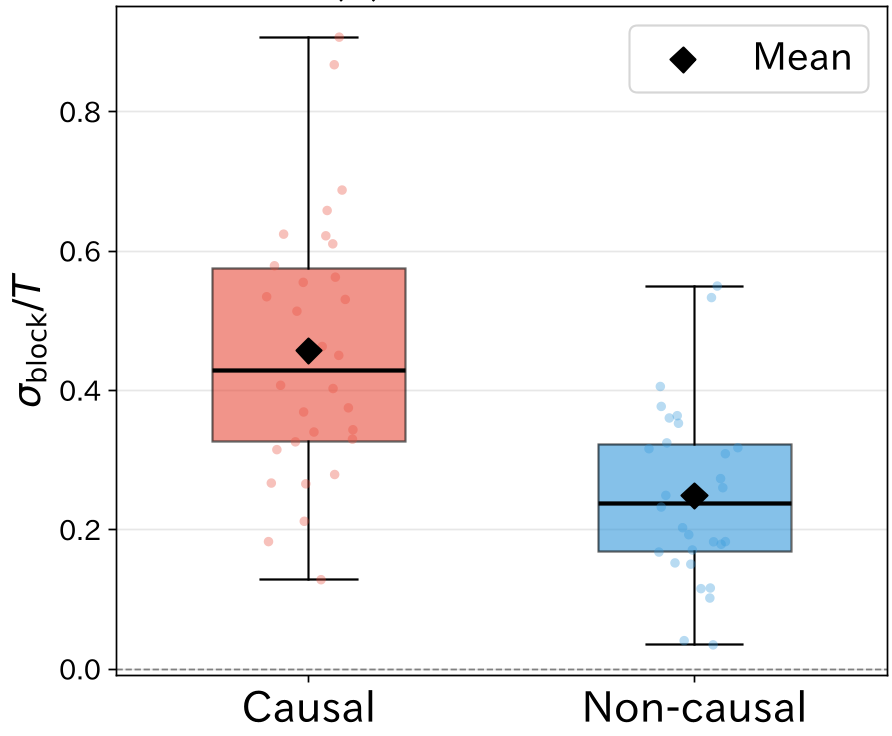 图 4:(a) 单词级 EP 无法区分文本类型;(b) 块(句子)级 EP 成功区分了因果串联与事实罗列。
图 4:(a) 单词级 EP 无法区分文本类型;(b) 块(句子)级 EP 成功区分了因果串联与事实罗列。
5. 深度分解:压缩损失与模型失配
论文最硬核的部分在于将每一步的 EP 分解为:
- 压缩损失 (Compression Loss):潜状态 毕竟是有限维度的,它在总结未来信息时必然存在丢弃。
- 模型失配 (Model Mismatch):将原本用于“正向预测”的神经核直接挪用到“后向预测”时产生的效能下降。
这为 LLM 的优化提供了新思路:如果我们想让模型更具“逻辑对称性”,我们需要最小化其回顾时的压缩损失。
总结与局限
Takahiro Sagawa 的这项研究为生成 AI 注入了物理灵魂。它告诉我们,一个足够强大的 LLM 内部其实构建了一个高度不可逆的“世界模型”。
局限性:目前的实验主要基于 GPT-2。对于更先进的模型(如 GPT-4 或 Claude),其内部对于“语义等价性”的处理更加复杂,简单的 Token 级反转可能不足以捕捉其高层抽象的不可逆性。
未来展望:这种“热力学测温”方法未来或许能用于检测模型幻觉——当模型生成的逻辑链条产生异常的 EP 波动时,可能暗示其进入了不稳定的生成状态。