StraTA (Strategic Trajectory Abstraction) is a hierarchical reinforcement learning framework for LLM agents that introduces an explicit natural-language strategy at the start of each episode. By conditioning actions on a global plan, it achieves state-of-the-art results on long-horizon benchmarks, reaching a 93.1% success rate on ALFWorld and 84.2% on WebShop.
TL;DR
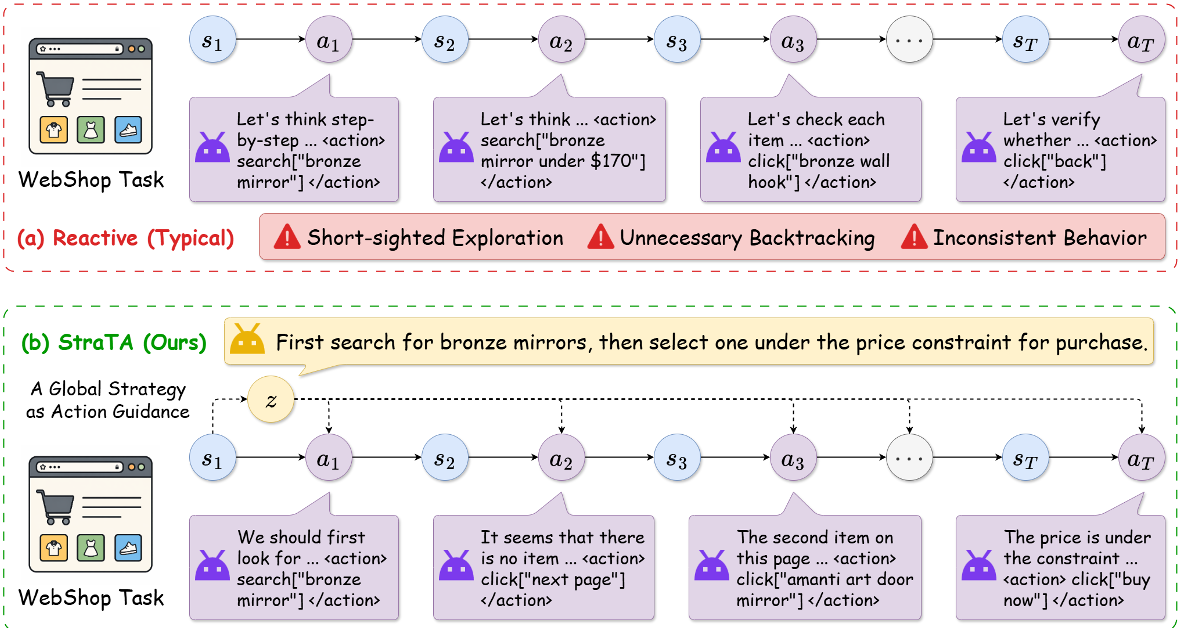
LLM agents often fail at complex tasks not because they lack "knowledge," but because they are too reactive. StraTA (Strategic Trajectory Abstraction) fixes this by forcing the model to generate a high-level strategy before acting. By combining hierarchical GRPO training with diversity-driven sampling and self-critique, StraTA sets new SOTA benchmarks on ALFWorld, WebShop, and SciWorld.
The "Reactive" Trap in Agentic RL
Most current reinforcement learning (RL) methods for LLM agents follow a simple loop: see state , predict action . This works for short tasks but falls apart when the agent needs to maintain a consistent goal over 50+ steps.
The authors identify two core failures in reactive agents:
- Exploration Fatigue: Without a plan, agents wander aimlessly or backtrack unnecessarily.
- Credit Assignment Blame-Game: When an agent fails at step 50, it is nearly impossible to tell if the failure was a bad move at step 49 or a disastrous high-level plan conceived at step 1.
Methodology: High-Level Planning meet Hierarchical RL
StraTA transforms the standard MDP into a two-stage process. First, the model generates a Strategy (). All subsequent actions are then conditioned on , effectively giving the agent a "north star" for the duration of the episode.
1. Hierarchical GRPO (Group Relative Policy Optimization)
Unlike standard PPO which requires a complex critic network, StraTA uses a group-based approach. It samples a "Group of Groups":
- Strategy-level Group: Multiple distinct strategies are sampled.
- Action-level Group: For each strategy, multiple reward-yielding trajectories are executed.
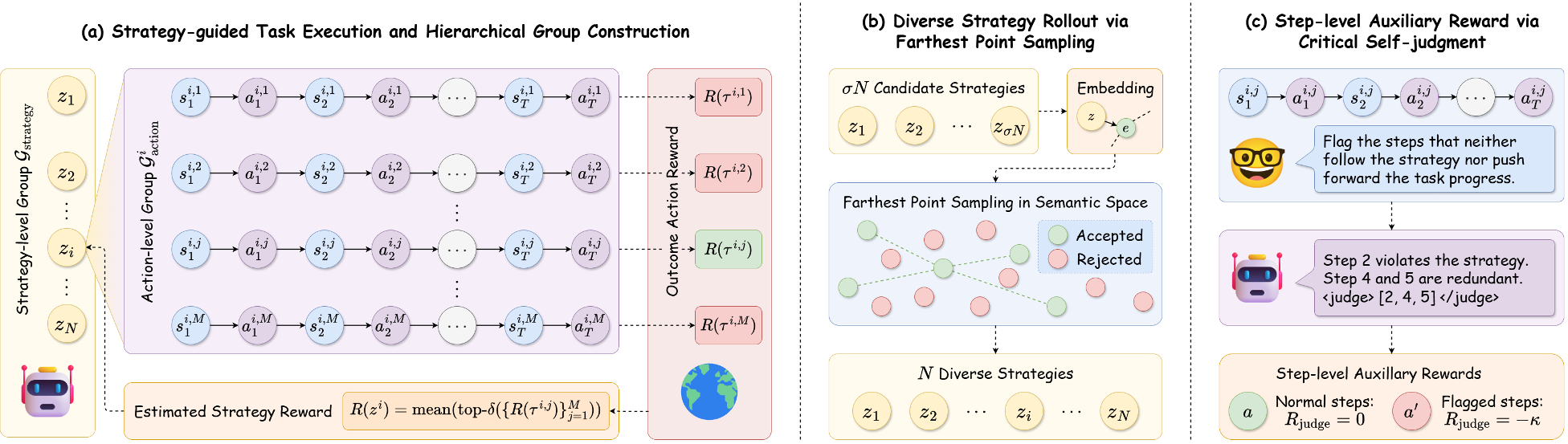
2. Boosting Diversity and Precision
- Diverse Strategy Rollout: To prevent the model from sampling nearly identical strategies, StraTA uses Farthest Point Sampling (FPS) in a semantic embedding space. This ensures the model compares truly different approaches (e.g., "Search the drawer" vs. "Look on the table").
- Critical Self-Judgment: The model acts as its own judge. After a rollout, it flags steps that didn't follow the strategy or didn't help the task. These steps receive a penalty, providing the "fine-grained" feedback that outcome rewards lack.
Experimental Performance: Beating the Giants
StraTA was tested on three brutal benchmarks: ALFWorld (embodied), WebShop (navigation), and SciWorld (science).
Key Breakthroughs:
- SciWorld Dominance: StraTA scored 63.5%, outperforming frontier closed-source models (GPT-5.1/Claude-4 levels) and prior RL baselines.
- Efficiency: Training curves show StraTA converges faster and more stably than vanilla GRPO or PPO, proving that strategic abstraction is a "shortcut" to better learning.
Ablation Insights
The researchers found that while the "Vanilla" hierarchical setup is strong, adding Diverse sampling and Judgment are orthogonal boosters. In WebShop, self-judgment was particularly effective at curbing "looping" behaviors where the agent repeats useless clicks.
Critical Analysis & Conclusion
StraTA demonstrates that explicit abstraction is better than implicit reasoning. By forcing the model to commit to a strategy, we reduce the search space of the RL problem.
Takeaway: If you want a more capable agent, don't just give it more RL steps; give it a hierarchical structure that mirrors human problem-solving.
Limitations: Currently, the strategy is fixed at the start. If the environment changes drastically, a fixed strategy can become a cage. Future iterations likely need "Adaptive Strategy Revision" where the agent can pivot when a plan fails.
For more details, check out the StraTA GitHub Repository.