本文揭示了大型语言模型(LLM)中“注意力汇点”(Attention Sink)现象的结构性根源,提出了从自注意力值聚合引起的方差差异到 FFN 超级神经元激活的因果链。通过引入 Head-wise RMSNorm 架构改进,成功消除了汇点现象,并在 1.52亿参数模型的预训练中显著提升了收敛速度和表征质量。
TL;DR
为什么大模型总是“迷之关注”序列开头的第一个 Token?这篇来自 arXiv 的最新论文通过严密的因果干预实验,揪出了 Attention Sink 的幕后真凶:因果掩码(Causal Mask)导致位置 0 的 Token 无法进行值聚合,产生的超高方差激活了 FFN 的超级神经元,最终“锁死”了 QK 投影。 作者通过简单的架构修正——Head-wise RMSNorm,不仅干掉了汇点,还让模型训练得更快更稳。
1. 痛点:被误解的“汇点”
在传统的认知中,Attention Sink 被视为 Softmax 算子的“垃圾回收站”:当模型不想关注当前上下文时,由于 Softmax 必须使权重和为 1,多余的分数只能堆给第一个 Token。
然而,本论文提出了更深刻的物理直觉:
- 它是功能还是病态? 虽然它利好长文本流式生成,但也带来了激活异常值(Outliers)和表征崩塌(Representation Collapse)。
- 为什么总是第一个? 作者发现,这并非随机选择,而是由 Transformer 架构的结构不对称性决定的。
2. 核心直觉:值聚合中的“方差陷阱”
在 Decoder-only 架构中,每个 Token 都会进行值聚合: 对于后续 Token(),这是一个加权平均过程,会起到类似低通滤波的作用,降低特征方差。但对于位置 0 的 Token,它只关注自己,方差完全没有被平滑。
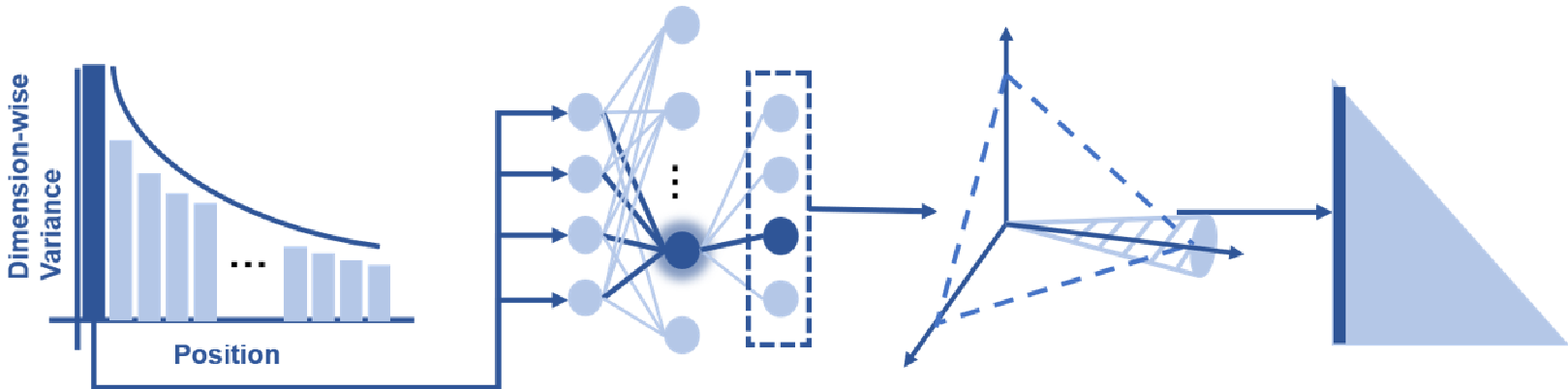 图1:从值聚合方差差异到维度失调的传播链条。
图1:从值聚合方差差异到维度失调的传播链条。
3. 连锁反应:超级神经元的“助燃”
高方差的初始 Token 经过输出投影 进入 FFN 层后,会发生恐怖的放大效应:
- 超级神经元激活:FFN 中存在一些权重范数极大的“超级神经元”。初始 Token 的异常方差精准触发了这些神经元。
- 维度失调(Dimension Disparity):超级神经元产生的剧烈激活通过稀疏的 投影,集中到了极少数维度上。
- QK 锁定:在下一层中,RMSNorm 为了处理这些庞大的异常值,会压缩其他所有维度的比例。这导致 Query 和 Key 向量在投影时被强制“锁定”在特定方向,从而产生极高的点积分数。
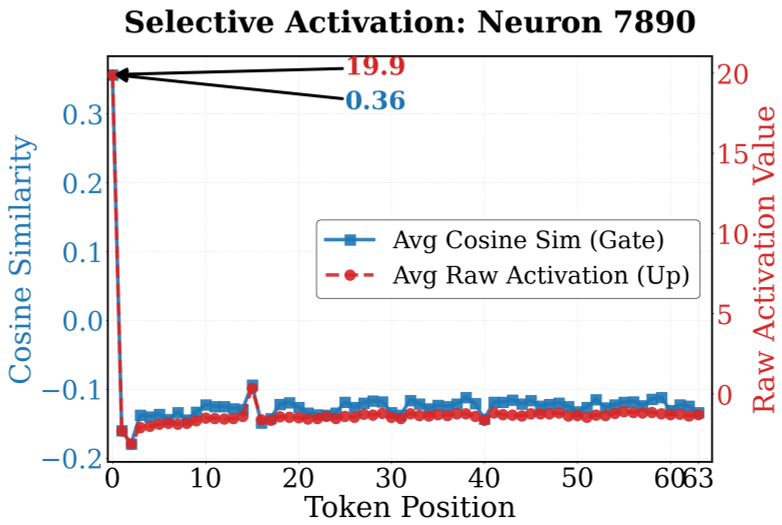 图2:超级神经元 7890 只针对初始 Token 产生海量激活,对后续 Token 则保持沉默。
图2:超级神经元 7890 只针对初始 Token 产生海量激活,对后续 Token 则保持沉默。
4. 实验验证:因果干预
作者通过两个天才般的干预实验验证了这一推论:
- 掩码干预:如果你强制让第 10 个 Token 也无法关注前面的 Token(即模拟初始 Token 的环境),第 10 个 Token 也会瞬间变成一个新的 Attention Sink。
- 方差放大:人为放大任意 Token 的方差,该 Token 也会立即“篡位”变成注意力汇点。
5. 解决方案:Head-wise RMSNorm
既然根源在于不同位置、不同 Header 之间的方差不一致,作者提出了 Head-wise RMSNorm。在自注意力层的值聚合之后、 之前,对每个 Head 独立执行: 这确保了无论 Token 在什么位置,其贡献的能量尺度是统一的。
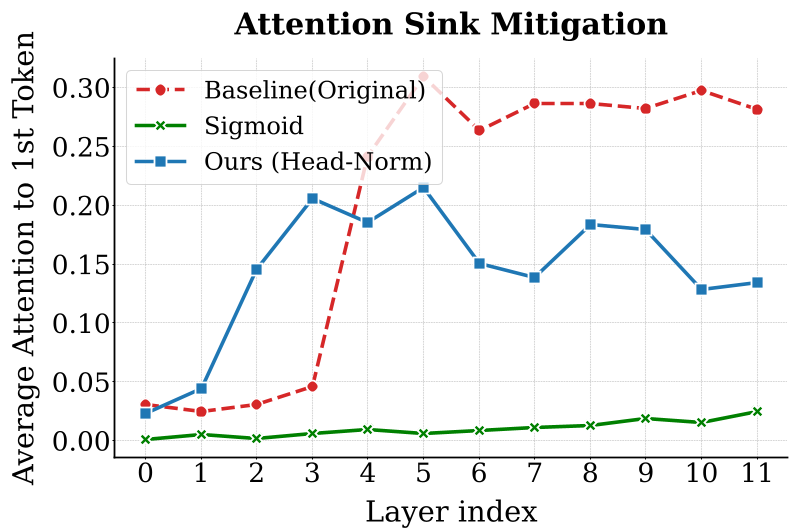 图3:基线模型(红色)在第 5 层开始出现汇点,而 Head-wise RMSNorm(蓝色)彻底抹平了这一异常。
图3:基线模型(红色)在第 5 层开始出现汇点,而 Head-wise RMSNorm(蓝色)彻底抹平了这一异常。
6. 深度洞察与总结
论文向我们展示了一个极具启发性的结论:模型内部的很多奇异行为(如数值异常值),本质上是架构不对称性的“回声”。
- 预训练加速:实验表明,解决方差差异后,模型的验证损失(Validation Loss)下降更快,说明这种结构性缺陷此前一直在阻碍优化。
- 流形崩塌缓解:通过提升 Effective Rank,模型保留了更多的表达空间,不再被单一维度“绑架”。
局限性:目前实验主要在 152M 参数规模上完成。在百亿、千亿参数模型中,虽然 Attention Sink 依然存在,但 Head-wise RMSNorm 的引入是否会影响原本已经适应了“汇点结构”的其他优化特性,仍需进一步在大规模预训练中验证。
结论:Attention Sink 不是上帝掷出的骰子,而是因果掩码埋下的伏笔。Head-wise RMSNorm 为我们提供了一个更优雅、更具数学稳定性的 Transformer 演进方向。